
Jobs
From version 2.2, encryption(in-flight, at-rest) is enabled for all kinds of jobs and catalogs. All the existing jobs(User created, and also system created) were updated with encryption related settings, and all the newly created jobs will have encryption enabled automatically.
Jobs enable you to run python, pyspark and drag-and-drop built codes in order to work on the datasets and perform any operation on the datasets.
How to Create a Job?
- Click on
+ New Jobs - Fill in the required fields (Details shown in the table below)

For example, let’s say you wish to create a test job that finds the highest-paying job and its salary. To achieve this, you can follow these steps:
- Create a new tester job using the job type
Spark - Set the network configuration to public
- Enable bookmarking for the job, if desired
- Specify the maximum capacity or worker type for the job, or leave it blank to use the default values
- Attach any necessary libraries with custom packages
- Run the job
Creating a Job will require you to fill some of the following fields:
| Attribute | Description |
|---|---|
| Name | The name by which the user wants to create the job. The name must be unique across the amorphic platform |
| Description | A brief description about the job created |
| Job Type | Choose the job registration type whether it is a Spark Job or a Python Job. |
| Bookmark | Specify whether to enable/disable/pause a job bookmark. If job bookmark is enabled then add a parameter transformation_ctx to their Glue dynamic frame so glue can store the state information |
| Max Concurrent Runs | This specifies the maximum number of concurrent runs allowed for the job |
| Max Retries | The specified number will be the maximum number of times the job will be retried if it fails |
| Max Capacity | Max capacity is the number of AWS Glue data processing units that can be allocated when the job runs (This parameter is only available for Python Jobs) OR
|
| Timeout | Maximum time that a job can run can consume resources before it is terminated. Default timeout is 48 hrs |
| Notify Delay after | After a job run starts, the number of minutes to wait before sending a job run delay notification |
| Datasets Write Access | User can select datasets with the write access required for the job |
| Datasets Read Access | User can select datasets with the read access required for the job |
| Domains Write Access | User can select domains with the write access required for the job. User will have write access to all the datasets (existing and newly created if any) under the selected domains |
| Domains Read Access | User can select domains with the read access required for the job. User will have read access to all the datasets (existing and newly created if any) under the selected domains |
| Parameters Access | User accessible parameters from the parameters store will be displayed. User can use these parameters in the script |
| Shared Libraries | User accessible shared libraries will be displayed. User can use these libraries in the script for dependency management |
| Job Parameter | User can specify arguments that job execution script consumes, as well as arguments that AWS Glue consumes. However, adding/modifying ["--extra-py-files", "--extra-jars", "--TempDir", "--class", "--job-language", "--workflow_json_path", "--job-bookmark-option"] arguments are restricted to user for an ETL job. |
| Network Configuration | There are five types of network configurations i.e. Public, App-Public-1, App-Private-1, App-Public-2 and App-Private-2.
|
| Keywords | Keywords for the job. Keywords are indexed and searchable within the application. Please choose keywords which are meaningful to you and others. You can use these to flag related jobs with the same keywords so that you can easily find them later |
| Glue Version | Based on the selected Job Type, you may select respective Glue Version to use while provisioning/updating a job. Currently Glue Version(s) 2.0, 3.0 & 4.0 is supported for Spark jobs & 1.0 and 3.0 for Python Shell jobs. |
| Python Version | Based on the selected Job Type and Glue Version, you may select respective Python Version to use while provisioning/updating a job. While creating a Spark job, Python Version can only be 3, for all Glue Versions (2.0, 3.0, 4.0). For Python Shell jobs, if the Glue Version is 1.0, Python Version can be 3, or if the Glue Version is 3.0, Python Version can be 3.9. |
| Data Lineage | Based on selected Job Type and Glue Version, you may select if you want to view the lineage of data on executing a job. Data lineage is currently supported for spark jobs with Glue versions 2, and 3. |
| Tags | Select the tags and access type in order to read the data from tag based access controlled datasets. |
Read access to datasets with Lakeformation as target location cannot be provided to jobs. Only read operation is supported for tag based access controlled(TBAC) S3 & Lakeformation datasets from jobs. Read access to the job for tag based access controlled datasets can only be provided through tags. Access to tag based controlled Lakeformation datasets with column restrictions on tags cannot be accessed by the Job.
How to write a file to a dataset?
You can write a file to a dataset using jobs. For example, if you want to follow the Landing Zone (LZ) process and write to the LZ bucket with validations then follow the below file name conventions:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>/<FileType>/<FileName>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo/csv/test_file.csv
If user want to write directly to DLZ bucket and skip the LZ process then user should set Skip LZ (Validation) Process to True for the destination dataset and follow the below file name convention:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>_<DatasetId>_<epoch>_<FileNameWithExtension>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo_1234-4567-8910abcd11_123123123_test_file.csv
Job Details
Job details page should be displayed with all the details specified and also with the default values for the unspecified fields (if applicable).
Edit Job
Job details can be edited using the 'Edit' button and changes will be reflected in the details page immediately.
Edit Script
Job script can be edited/updated anytime using the 'Edit Script' button. Once the script is loaded in the script editor, Turn off the read mode and edit the script accordingly. Click on 'Save & Exit' button to save the final changes.
The following picture depicts the script editor:
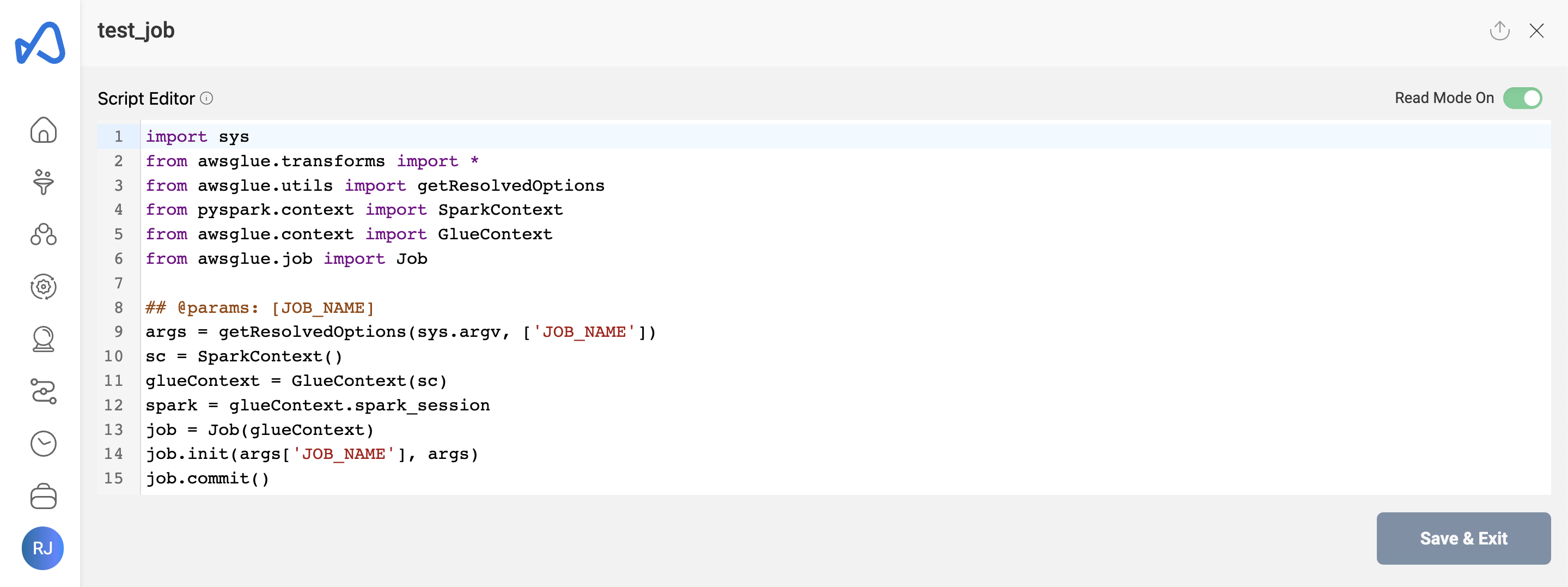
User can also load the script from a python file using the 'Load Script' (upload) button on the top right side of the script editor.
Manage External Libraries
Users can upload external libraries to ETL job using the 'Manage External Libraries' option from the three dots on the top right side of the details page. Click the '+' sign on the top right & then Click on 'Select files to upload' and then 'Upload Selected Files' button after selecting the files to upload one or more library file(s).
The following example shows how to upload external libraries to an ETL job.
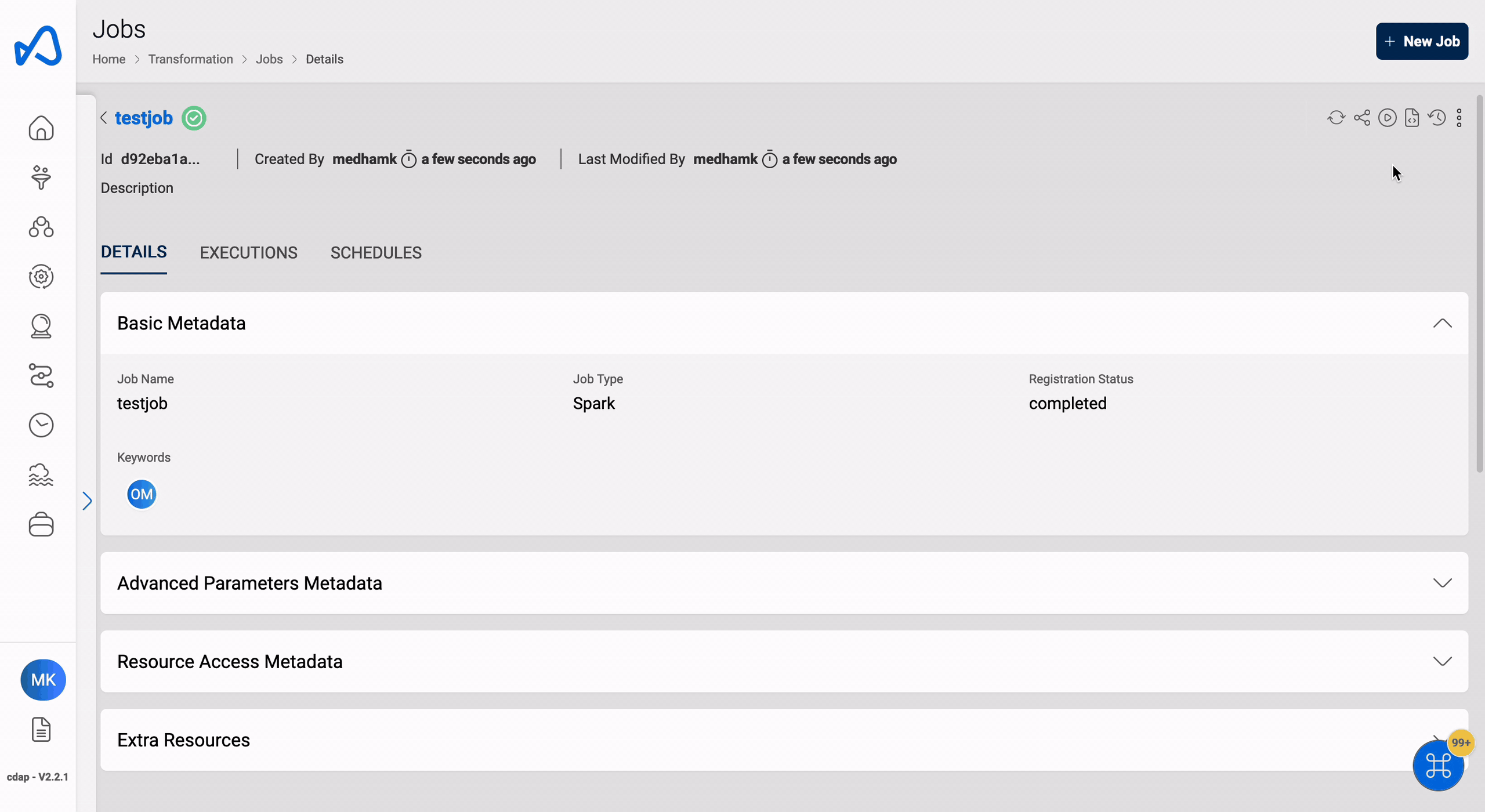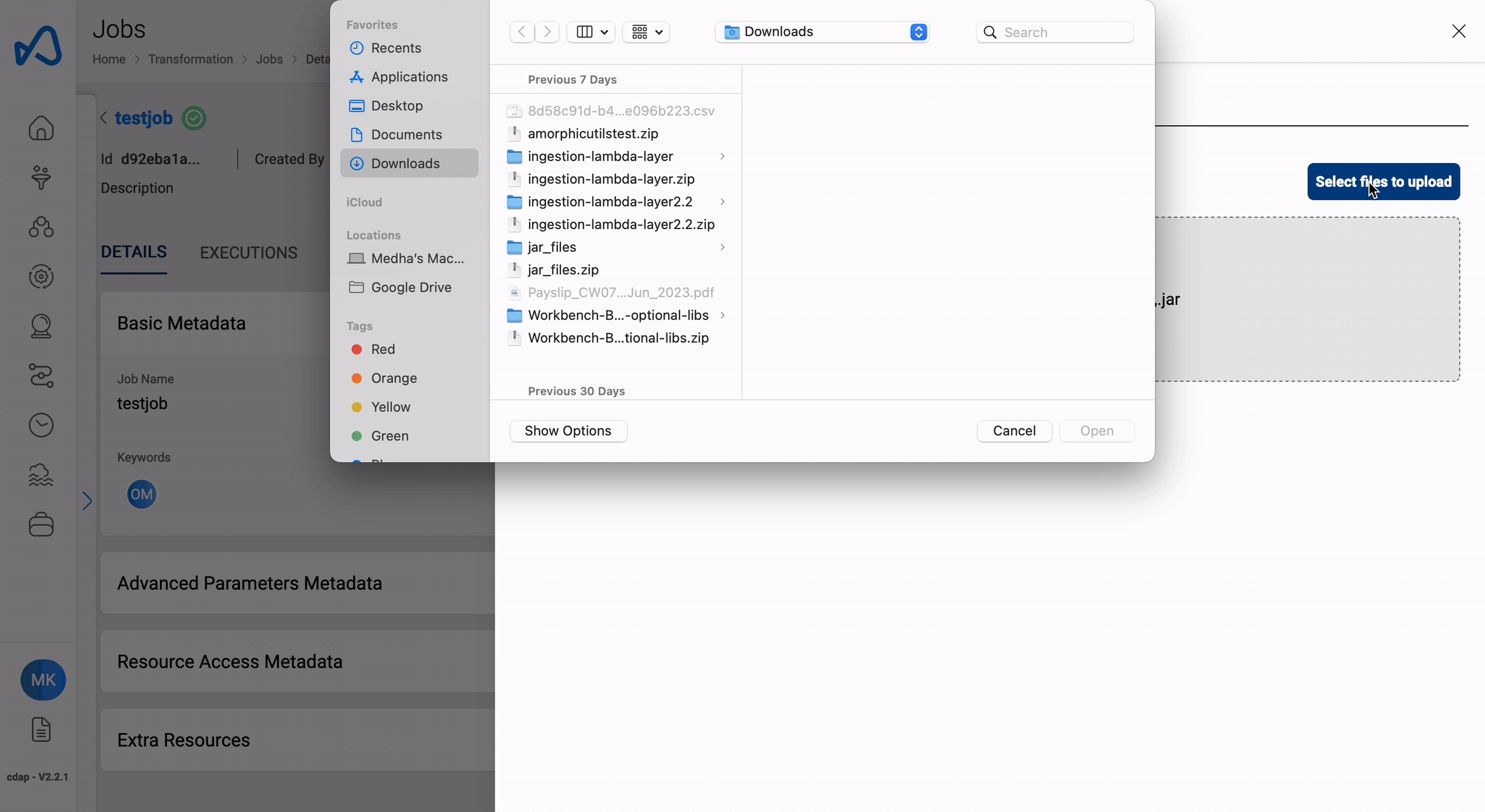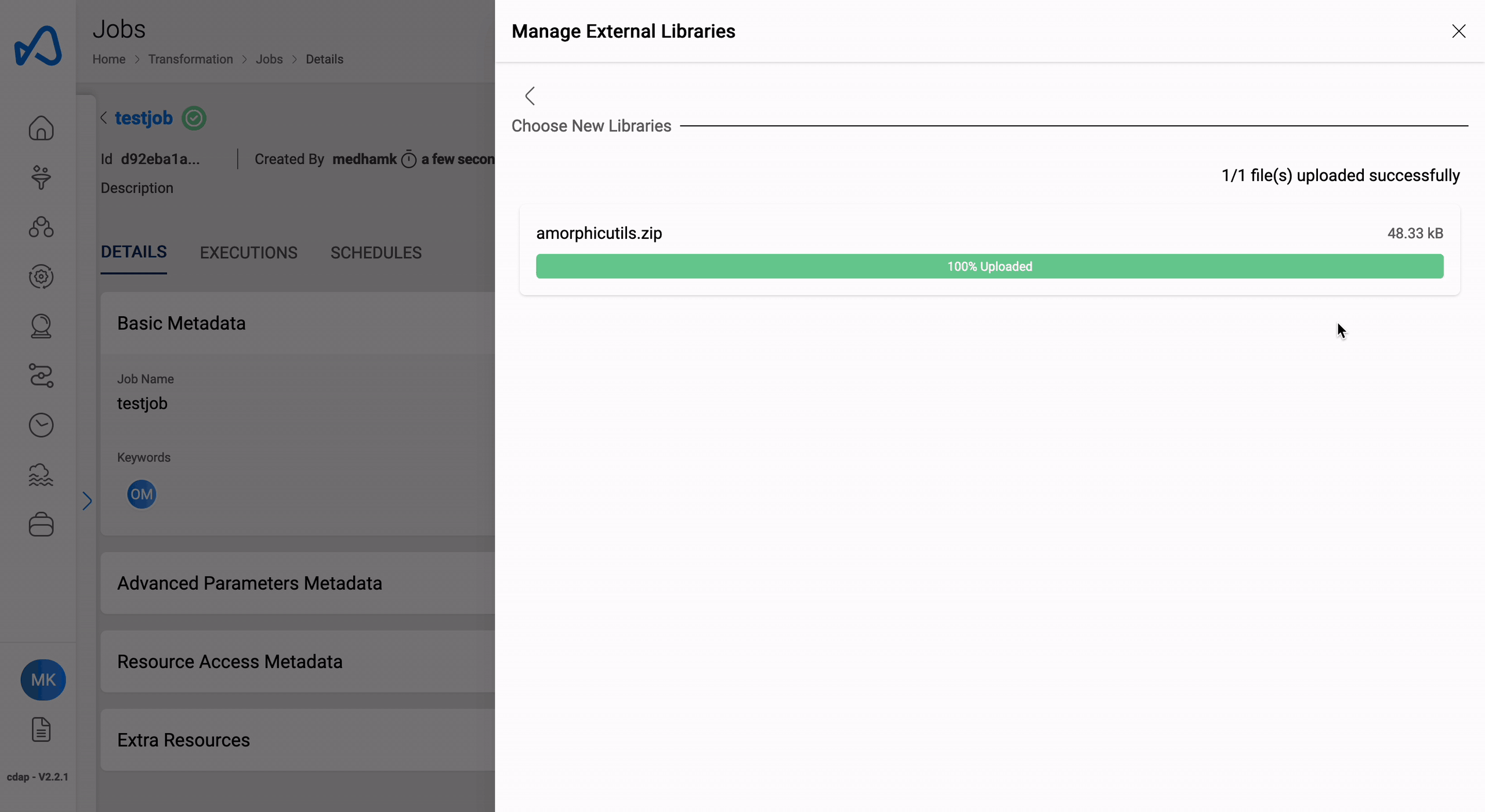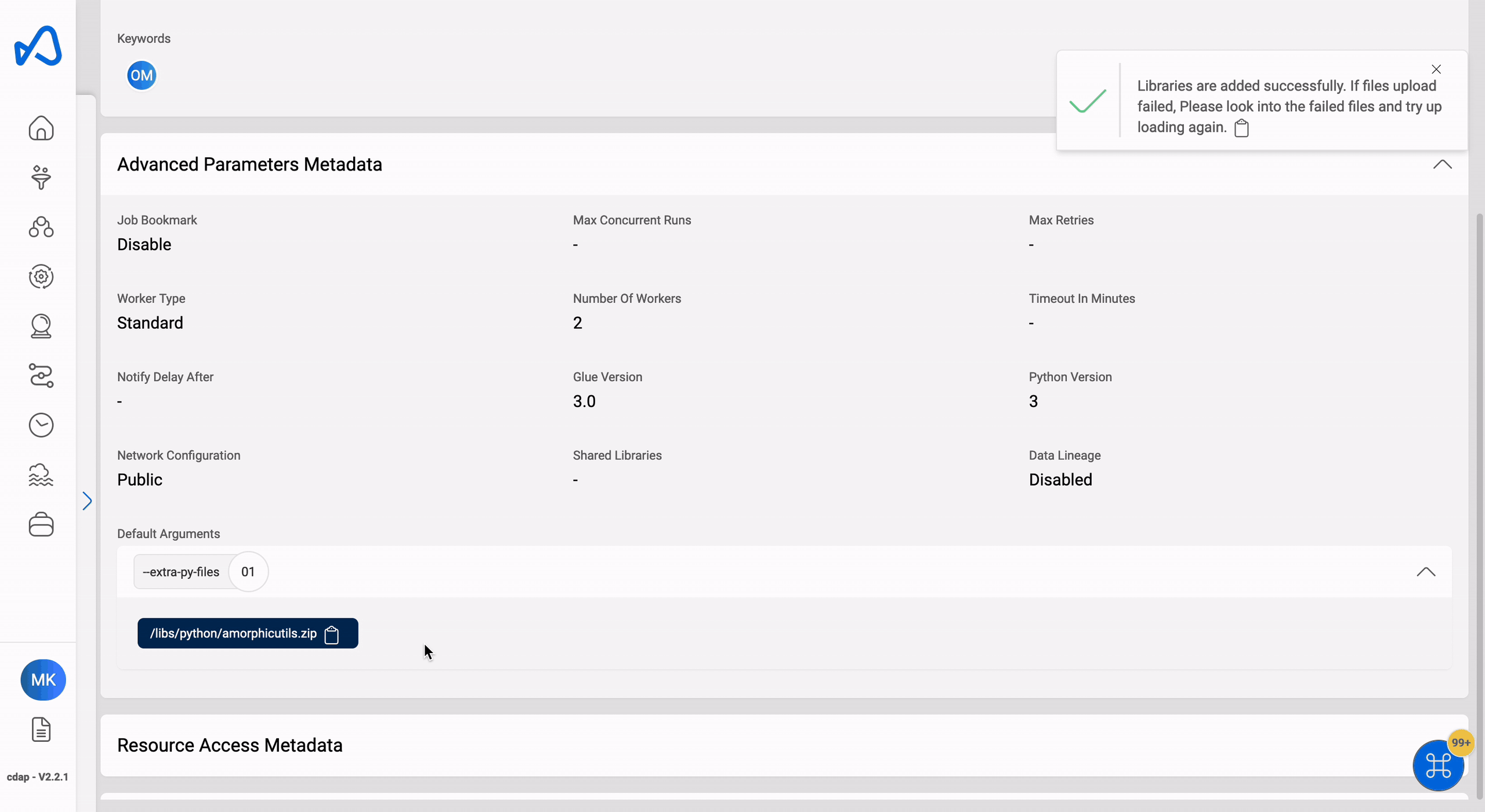
Uploaded library file(s) will be displayed in the details page immediately.
Users can remove the external libraries from the ETL job by selecting the libraries and clicking on the 'Remove selected libraries' button in 'Manage External Libraries'. User can also download the external libraries by clicking on the download button displayed on the right of each uploaded library path.
Update Extra Resource Access
To provide parameter or shared libraries or dataset access to a job in large number, use the documentation on How to provide large number of resources access to an ETL Entity in Amorphic
Run Job
To execute the Job, click on the Run Job (play icon) button on the top right side of the page. Once a job run is executed, refresh the execution status tab using the Refresh button and check the status.

Once the job execution is completed, Email notification will be sent based on the notification setting and job execution status.
User can stop/cancel the job execution if the execution is in running state.
User might see the below error if the job is executed immediately after creating it.
Failed to execute with exception “Role should be given assume role permissions for Glue Service”
In this case, User can try executing it again.
The following picture depicts how to stop the job execution:

Job executions
You can filter through & find all the executions in the Execution tab. The job executions also contain executions that have been triggered via job schedules, nodes in workflows, and workflow schedules. Also, if the Job has Max Retries value then the job will display all the executions including the retry attempts.

You can also check the corresponding Trigger Source for the execution entry.

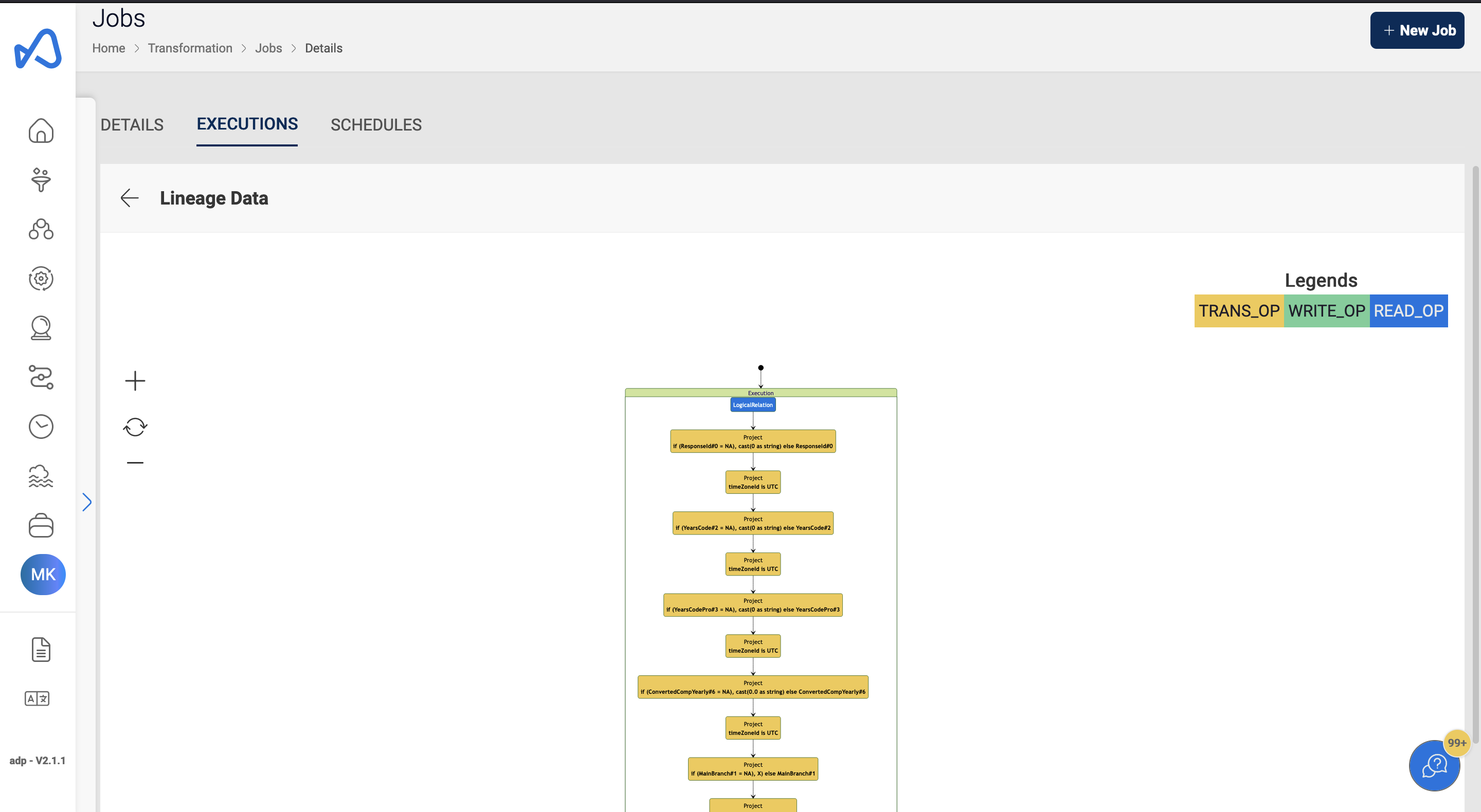
If Data Lineage is enabled, the generated data lineage, if available, can also be viewed here.
This would show you the operations that have been performed on the data during the execution of the spark job. There can be read operations, transformation operations, and write operations. In an IP whitelisting enabled environment, data lineage cannot be enabled for jobs with Public Network Configuration. For others, the Elastic IP address, which is the public IP of the source, needs to be whitelisted.
Download logs
You can also download the job output and error log. For job output, you can either download the latest 1 MB data or the complete job output logs. The log status shows triggered while fetching the logs and available when it's ready to downloaded.
Job Bookmark
Bookmark Job helps track data of a particular Job run. For more info on job bookmarks please refer documentation. Refer this documentation to understand the core concepts of job bookmarks in AWS Glue and how to process incremental data.
Choose from the below three bookmarks:
Enable - Keeps track of processed data by updating the bookmark state after each successful run. Any further job runs on the same data source, since the last checkpoint, only processes newly added data.
Disable - It's the default setting, which means that the job will process the entire dataset each time it is run, regardless of whether the data has been processed before.
Pause - It allows the job to process incremental data, since the last successful run, without updating the state of the job bookmark. The job bookmark state is not updated and the last enabled job run state will be used to process the incremental data.
For job bookmarks to work properly, enable the job bookmark option in Create/Edit job and also set the transformation_ctx parameter within the script.
Below is the sample job snippet to set the transformation_ctx parameter:
InputDir = "s3://<DLZ_BUCKET>/<DOMAIN>/<DATASET_NAME>/"
spark_df = glueContext.create_dynamic_frame_from_options(connection_type="s3",connection_options = {"paths": [InputDir],"recurse" : True},format="csv",format_options={"withHeader": True,"separator": ",","quoteChar": '"',"escaper": '"'}, transformation_ctx = "spark_df")
Use Case: Connecting to customer system/database from a glue job
Customer has a glue job that needs to connect to a system/database that has a firewall placed in front of it. In order to establish the connection, the public IP of the source needs to be whitelisted. The public IP required here will be the NATGateway ElasticIP.