DeepSearch Indices
DeepSearch Indices enables users to create an index in AWS Kendra to enable deep searching of dataset file data.
For example, suppose you have a dataset of product information stored in a file on Amazon Web Services (AWS) S3. This file contains information such as product name, product description, price, and reviews. To make it easier to search this data, you can create an index in AWS Kendra using Deepsearch Indices.
This will allow you to perform deep searches of the product information by product name, description, price, and reviews, among other fields. For instance, you can search for all products that cost less than $50, or search for all products that contain the word "laptop" in their description. By creating an index, you can make it easier to find the information you need within your dataset.
How to Create DeepSearch Index?

To create a new Deepsearch Index follow the below steps:
- Clicking on
+ New Deepsearch Index - Fill in the below information apart from the name and description of the index:
Auto Terminate: This enables Deepsearch Index termination to save resource costs based on the termination time value provided by the user. Auto termination process is triggered every hour and looks for any Deepsearch Indices that needs to be notified or deleted and sends an email when one of the below criteria is met. The user will receive a notification email in the following scenarios:
- If the difference between the auto-terminate process trigger run (every whole hour) and the termination time is less than 30 minutes.
- If the auto-termination process was successfully able to delete the Deepsearch Index after the termination time
- If the auto-termination process wasn't able to delete the Deepsearch Index due to some fatal errors.
Auto Termination Time: You can set auto termination time for Deepsearch Index of less than 168 hours (7 days). If current time is greater than termination time, Index will be deleted next whole hour.
- Auto-termination process is scheduled to run every hour on the hour (e.g: 6:00, 7:00, 8:00, 9:00).
- User will receive a email notification only when the user is subscribed to alerts. Please refer to Alert Preferences to enable alerts.
- When the termination time elapses, auto termination process will terminate/delete the Deepsearch Index and also deletes all the metadata related to the Deepsearch Index and this process cannot be undone.
Once the index is created with the above metadata, the index will be in the CREATING state. It will take a few minutes to complete creating the index and the status will be ACTIVE. It will contain the following information:
| Type | Description |
|---|---|
| Index Name | Deepsearch Index Name, which uniquely identifies the index. |
| Description | A brief explanation of the index typically the type of data added to it. |
| Status | Status of index. Ex: CREATING, ACTIVE etc. |
| Documents Count | Number of the documents added to the index through datasets. |
| Auto Terminate | Status of the auto-termination Ex: Enabled, Disabled |
| Remaining Time | Amount of time (in hr) left for auto-termination |
| Auto Termination Time | Time at which the system auto terminates the deepsearch index. |
| CreatedBy | User who created the index. |
| LastModifiedBy | User who has recently updated the index. |
Deepsearch Indices Operations
Amorphic DeepSearch Indices provides below operations for a DeepSearch index. However, you should have sufficient permission to perform the below operations.
| Type | Description |
|---|---|
| Create Index | Create an Deepsearch Index in AWS Kendra. |
| View Index | View an existing index. |
| Add Datasets | Add datasets to the index. |
| Sync Jobs | Sync the documents to the index. |
| Search | Search for the indexed document data. |
| Delete Index | Delete an existing index. |
Add Datasets
You can add datasets to the index using the Add datasets to Index option. Note that only datasets containing unstructured files can be indexed. For more information on the types of supported documents, refer to the AWS Documentation.
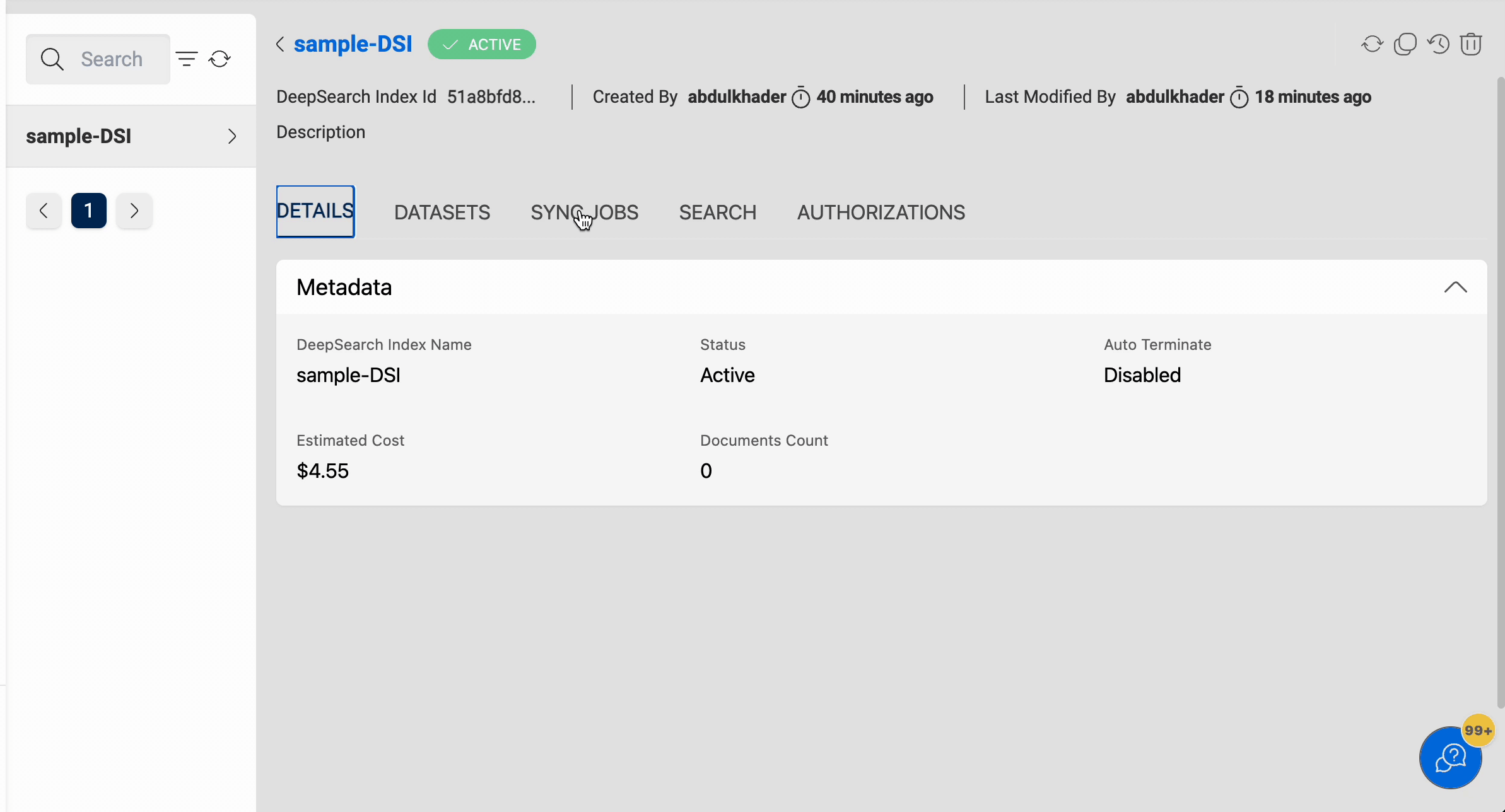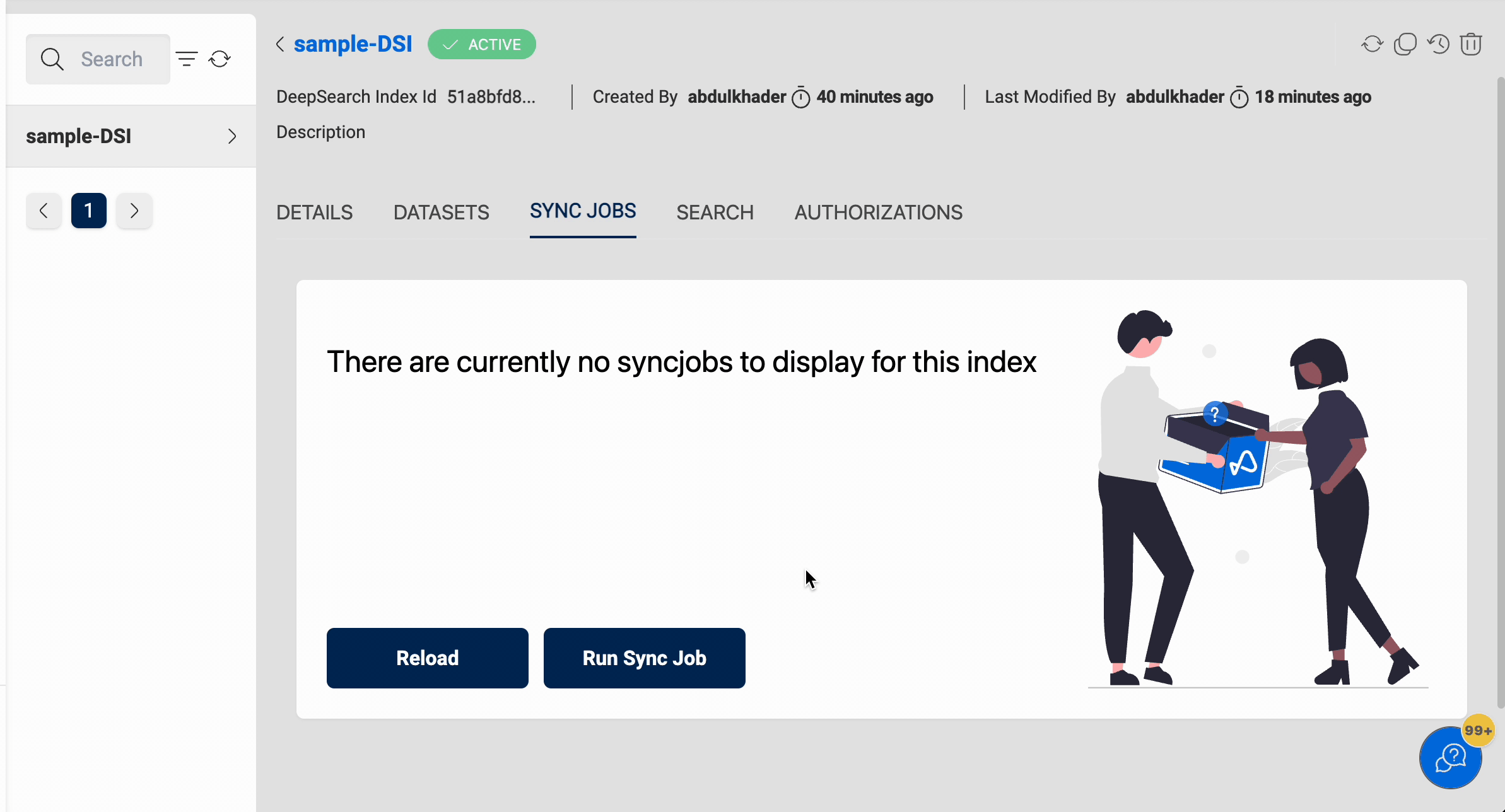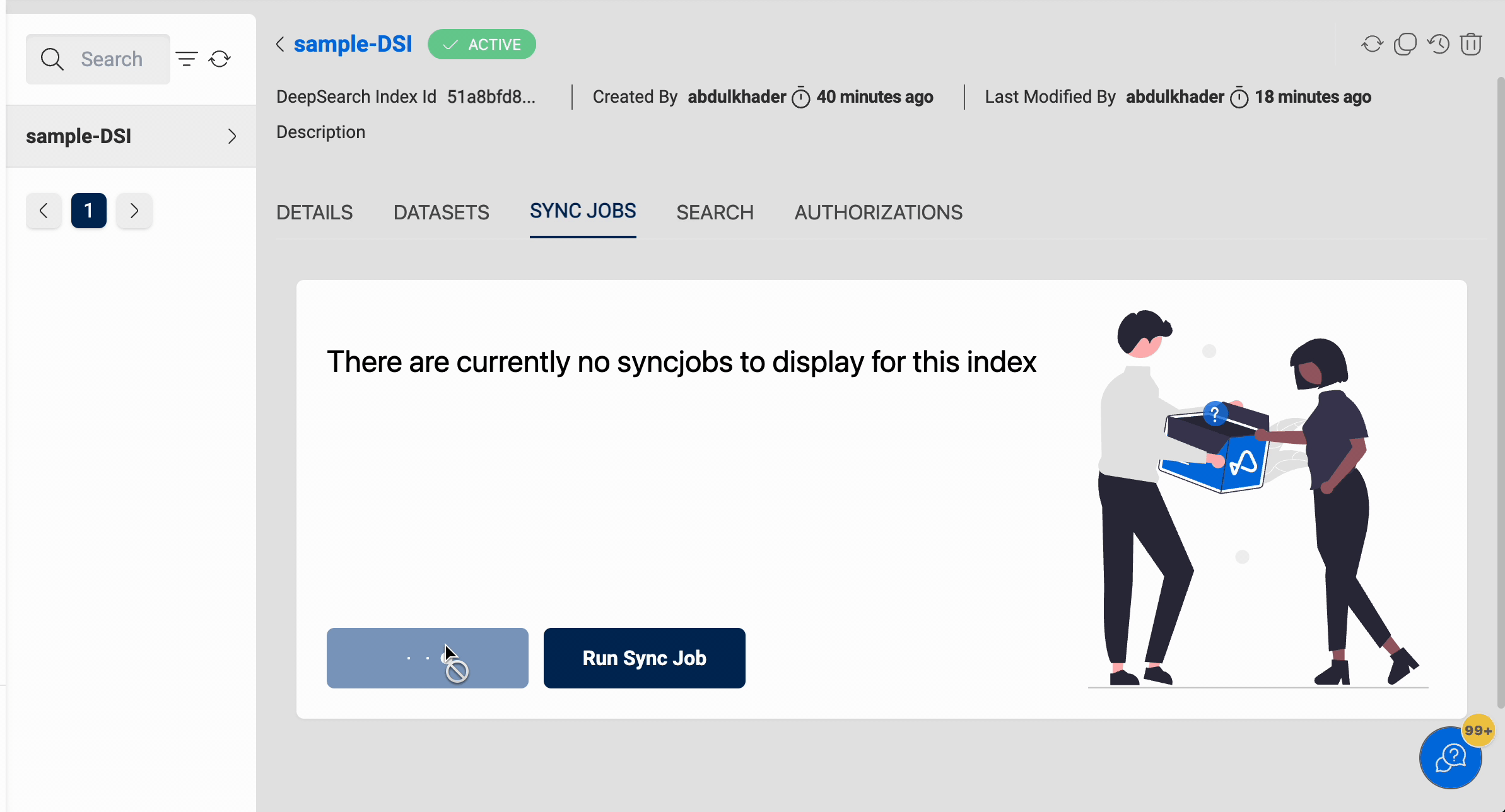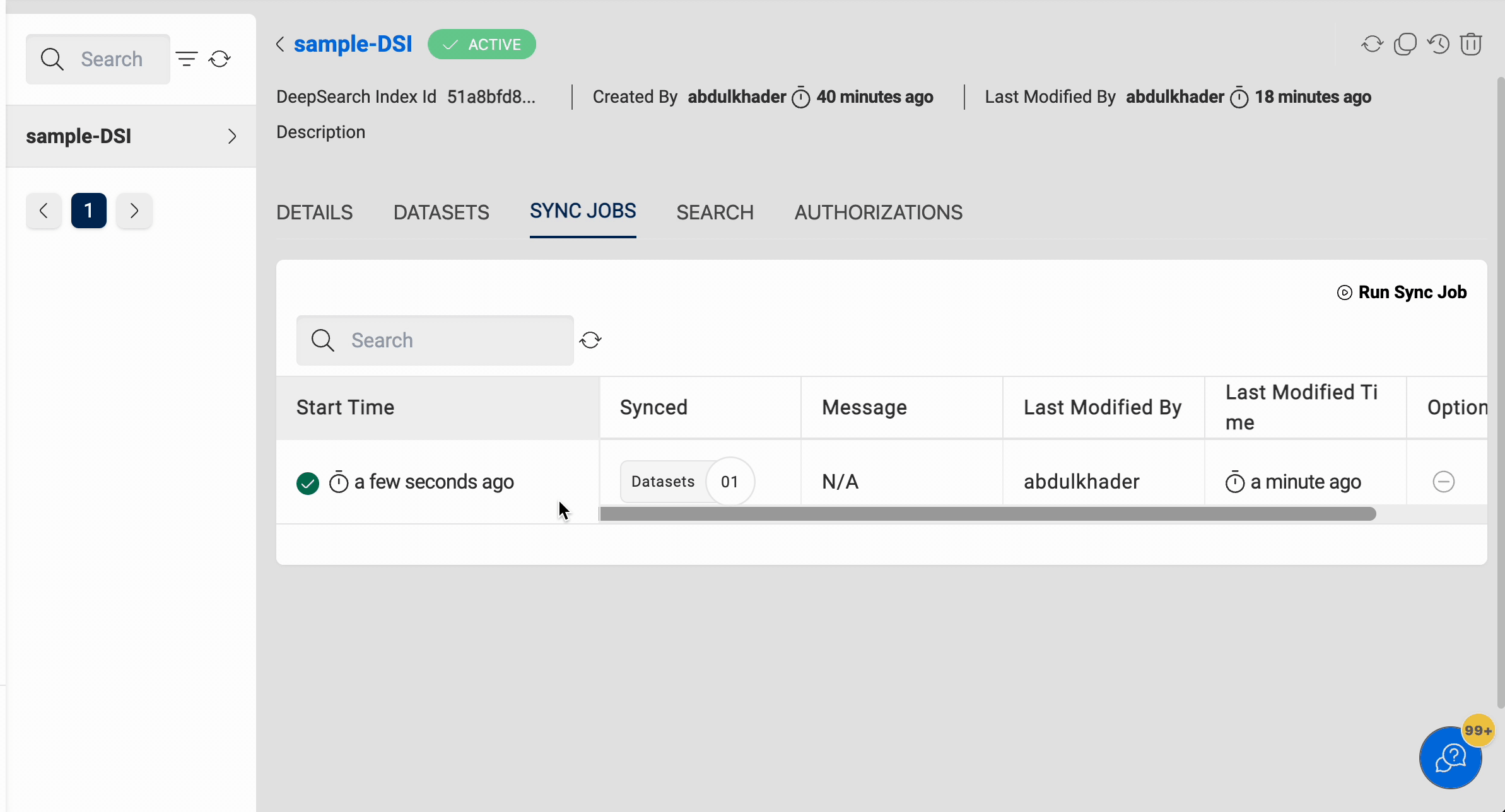
Sync Jobs
Once the datasets are added to the index, you can run the Sync job to add the documents (structured and unstructured) from the datasets to the index.
Once the sync job is triggered and the job is in the SYNCING state, you can take the following actions:
- Refresh the jobs using the 'Refresh' button on the right side to get the latest status of the job.
- Stop the syncing of the datasets using the 'Stop' (red) button beside the SYNCING status of the respective job.
You can also view the details of the job, such as the Status, Datasets synced, Error message (if failed), etc.
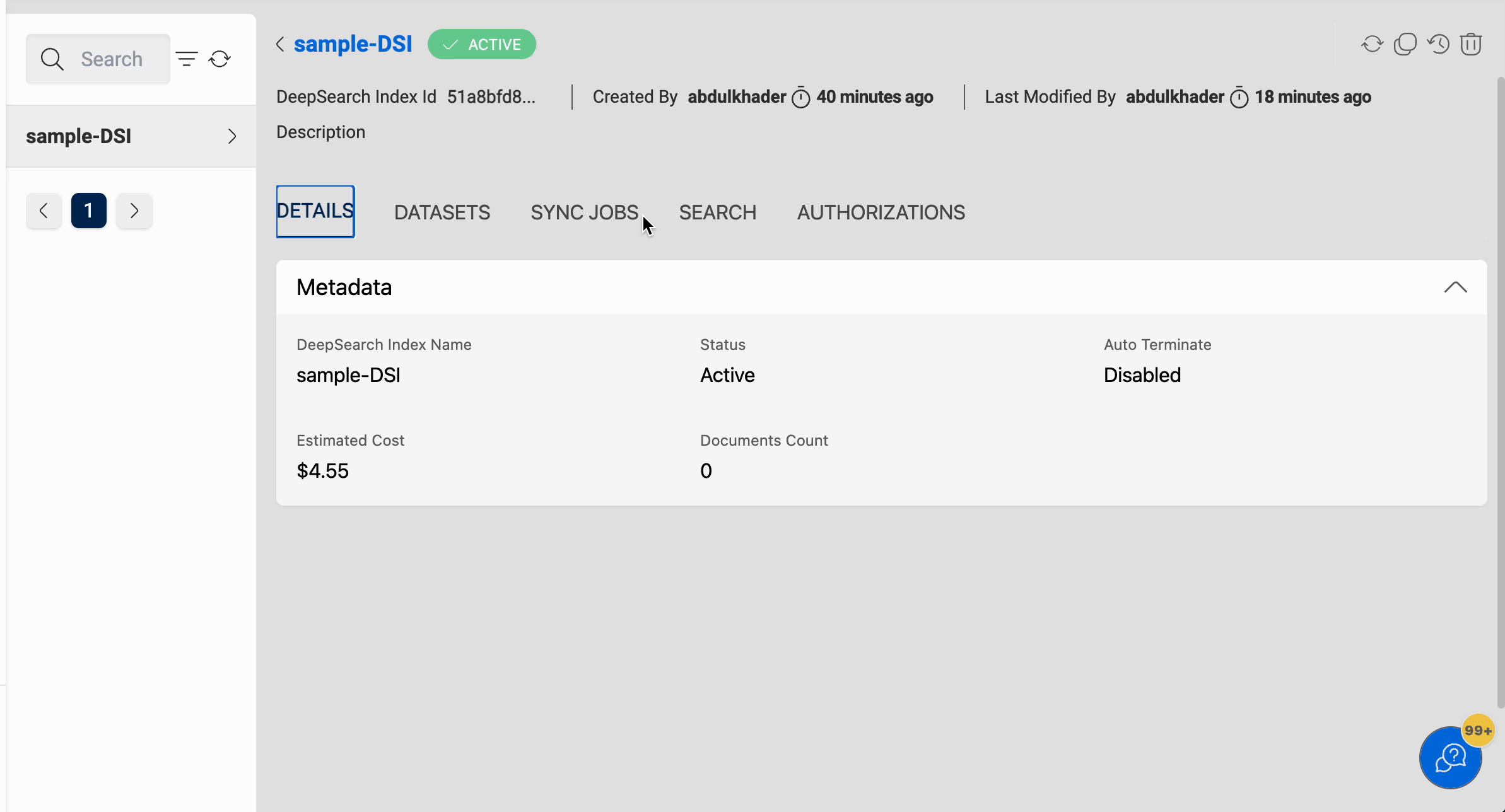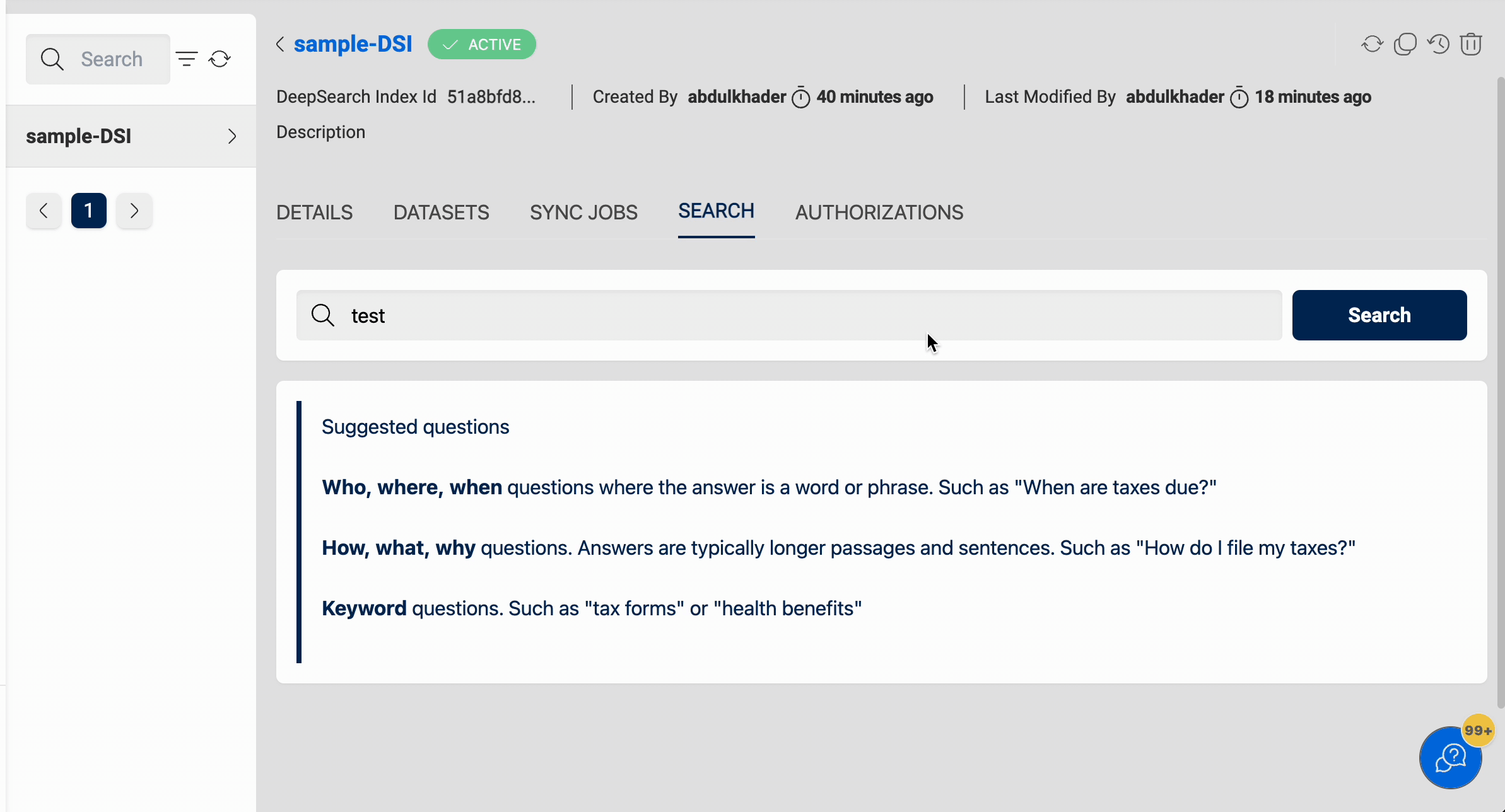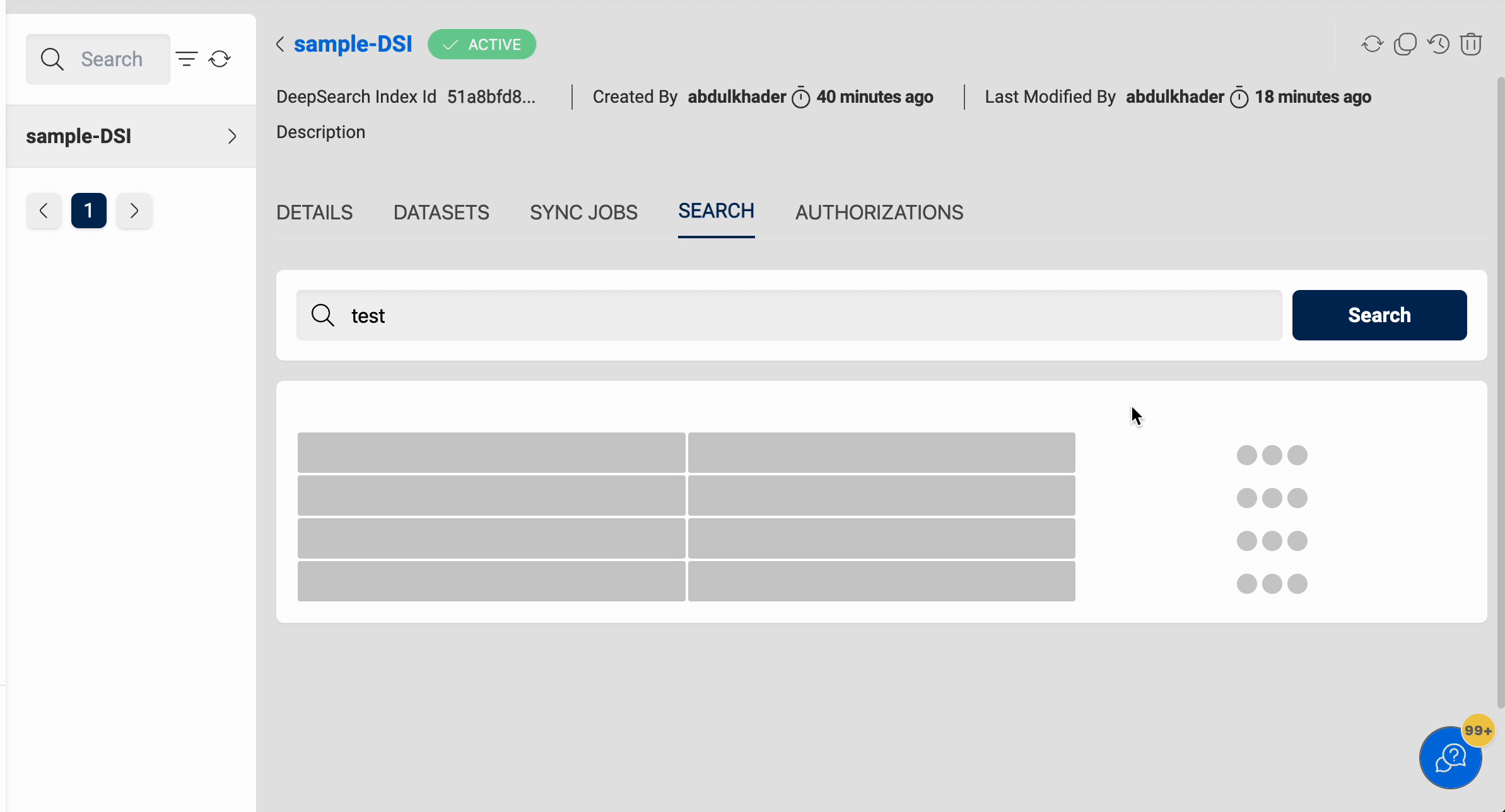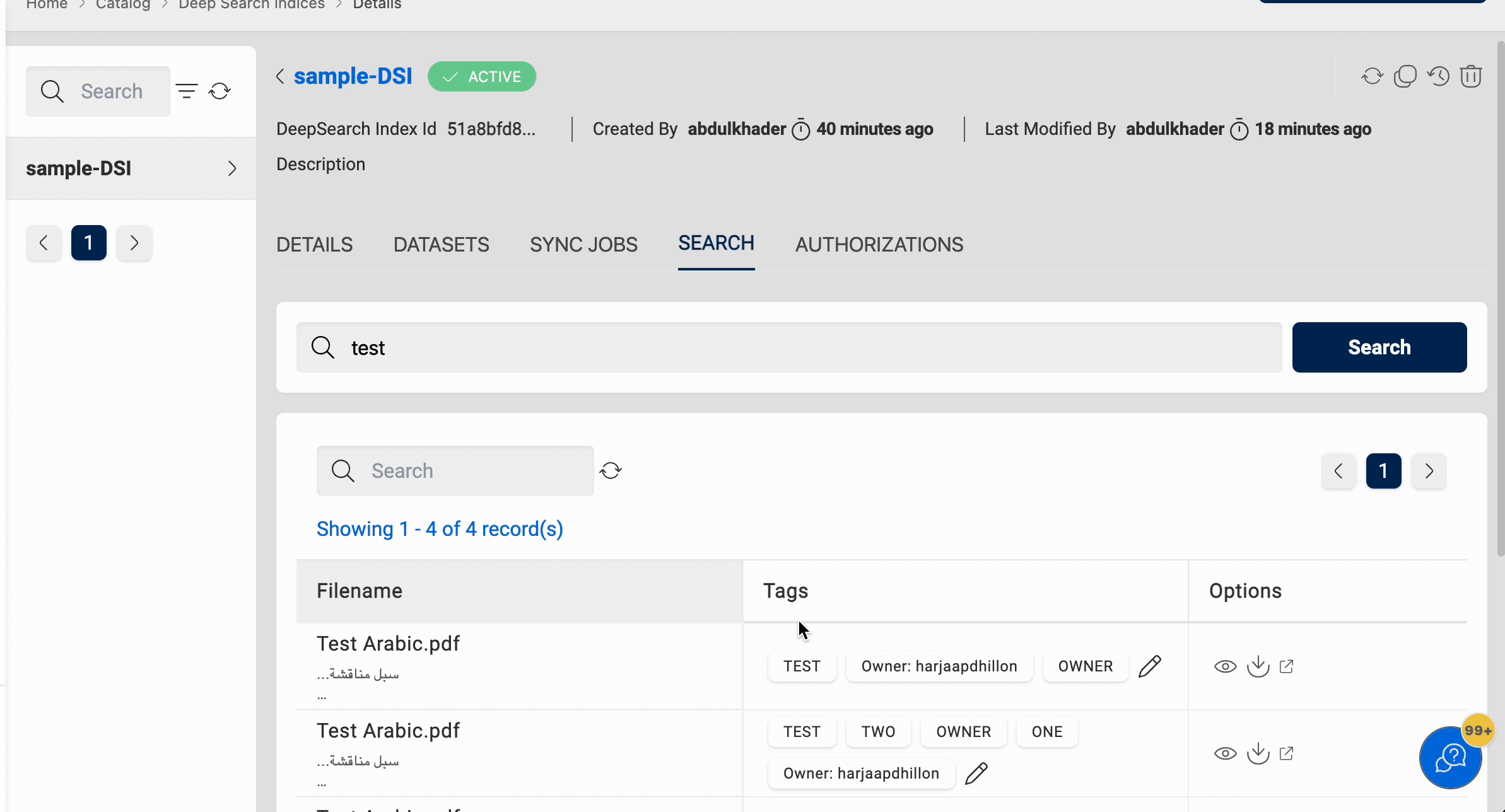
Search
After running the sync-job and indexing documents, you can search for data in the documents using the search bar in the Search tab. Upon entering a keyword, the search will be conducted through all indexed documents and results will be displayed with the following options:
- Add/Remove tags: You can add tags to the files and remove tags from the files.
- Download: You can download the file.
- File Preview: You can preview the file. Supported file formats are txt, json, docx, pdf and html.
- View Dataset: You can navigate to the respective dataset in which the file resides.
Please follow the below animation on how to search for data:
Index Details
If the user has sufficient permissions to view an index then all the index information can be viewed.
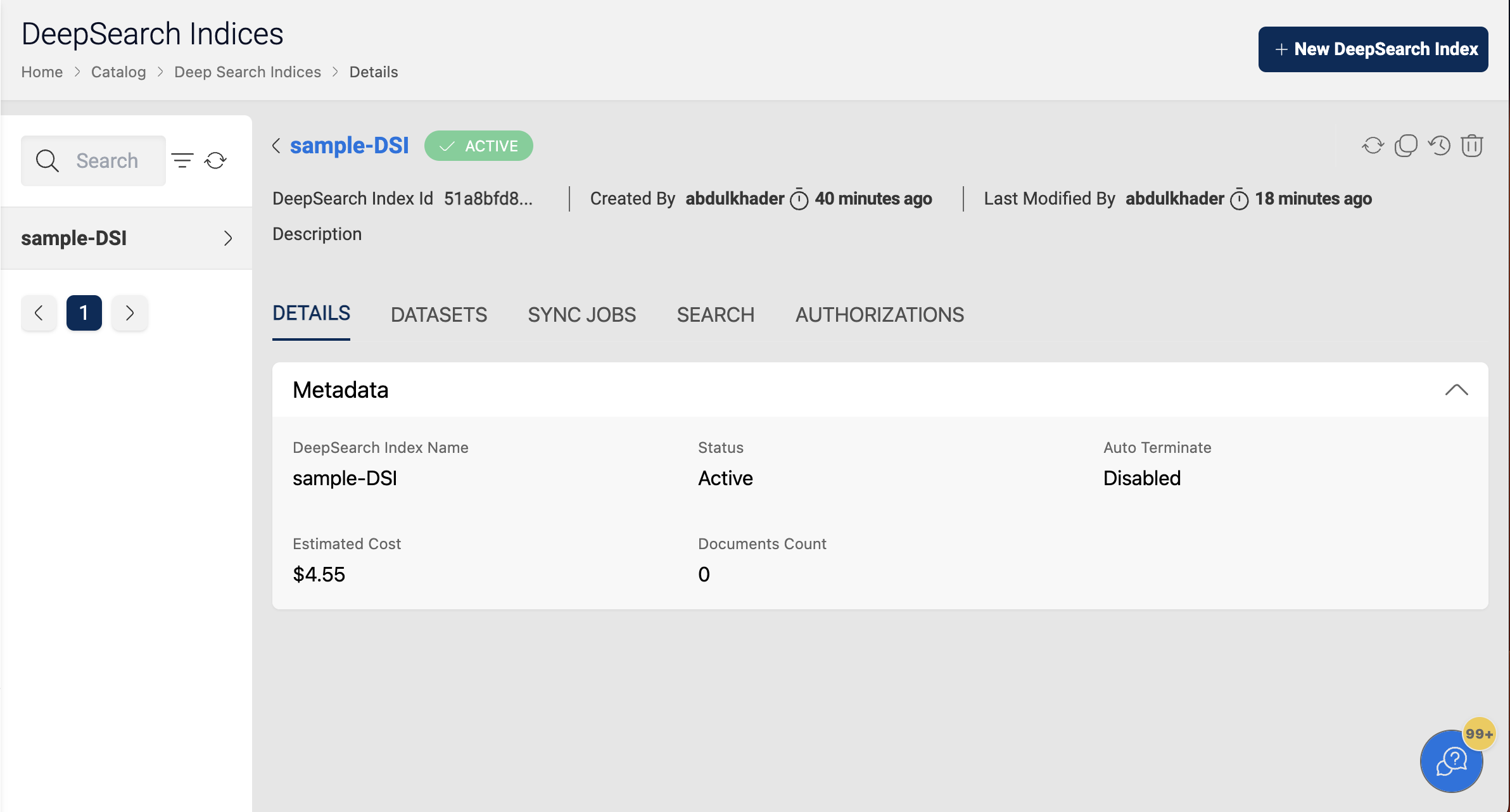
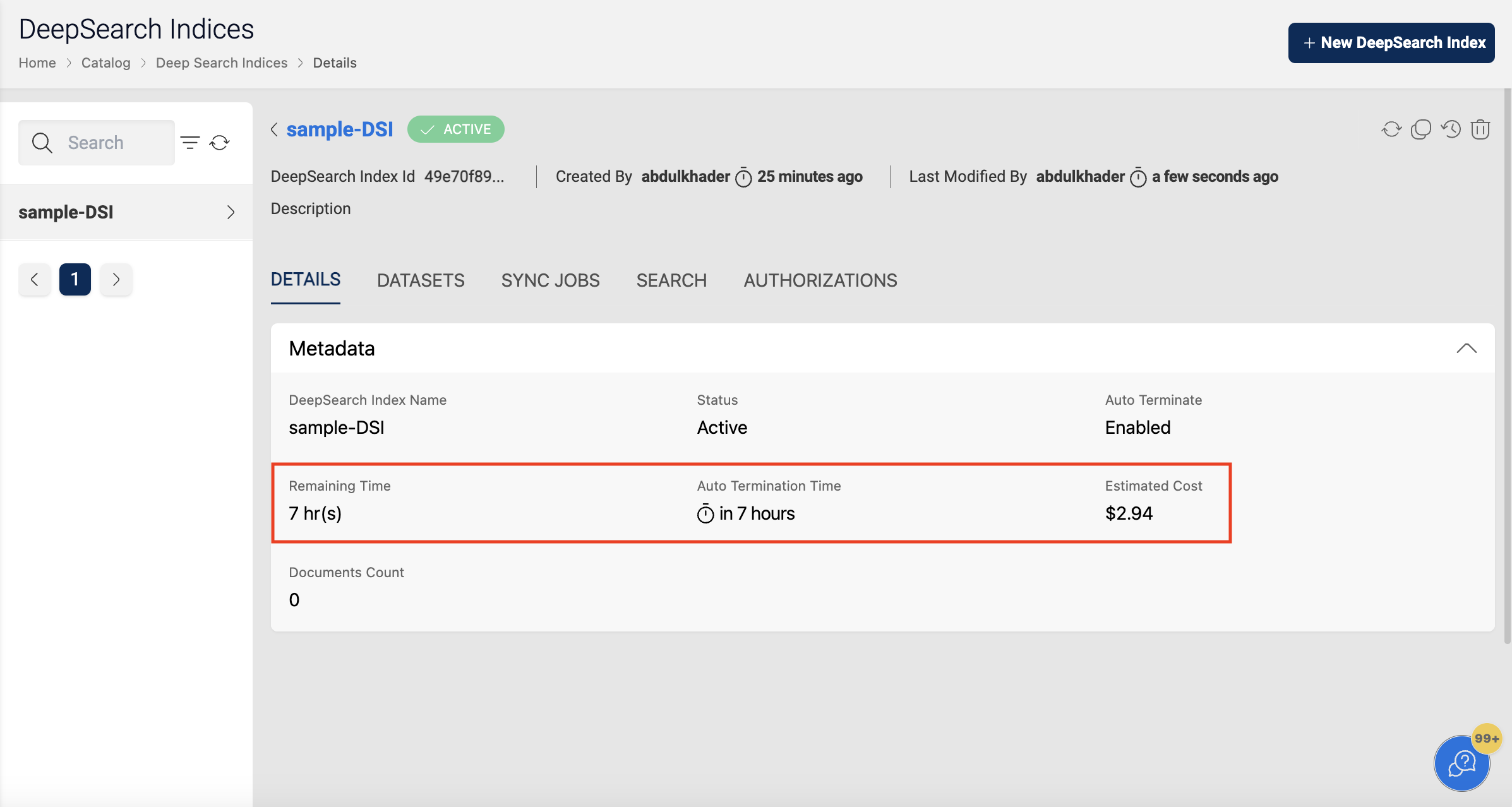
When the user enables auto-termination on the deepsearch index, the following details will be displayed: Remaining Time, which denotes the amount of time (rounded to the nearest upper hour) left for auto-termination.
In the below image, the auto-termination time is set to June-2-2021 18:51, but the deepsearch index will be deleted at 2021-06-02 19:00, as the termination process is scheduled to run at the whole hour.
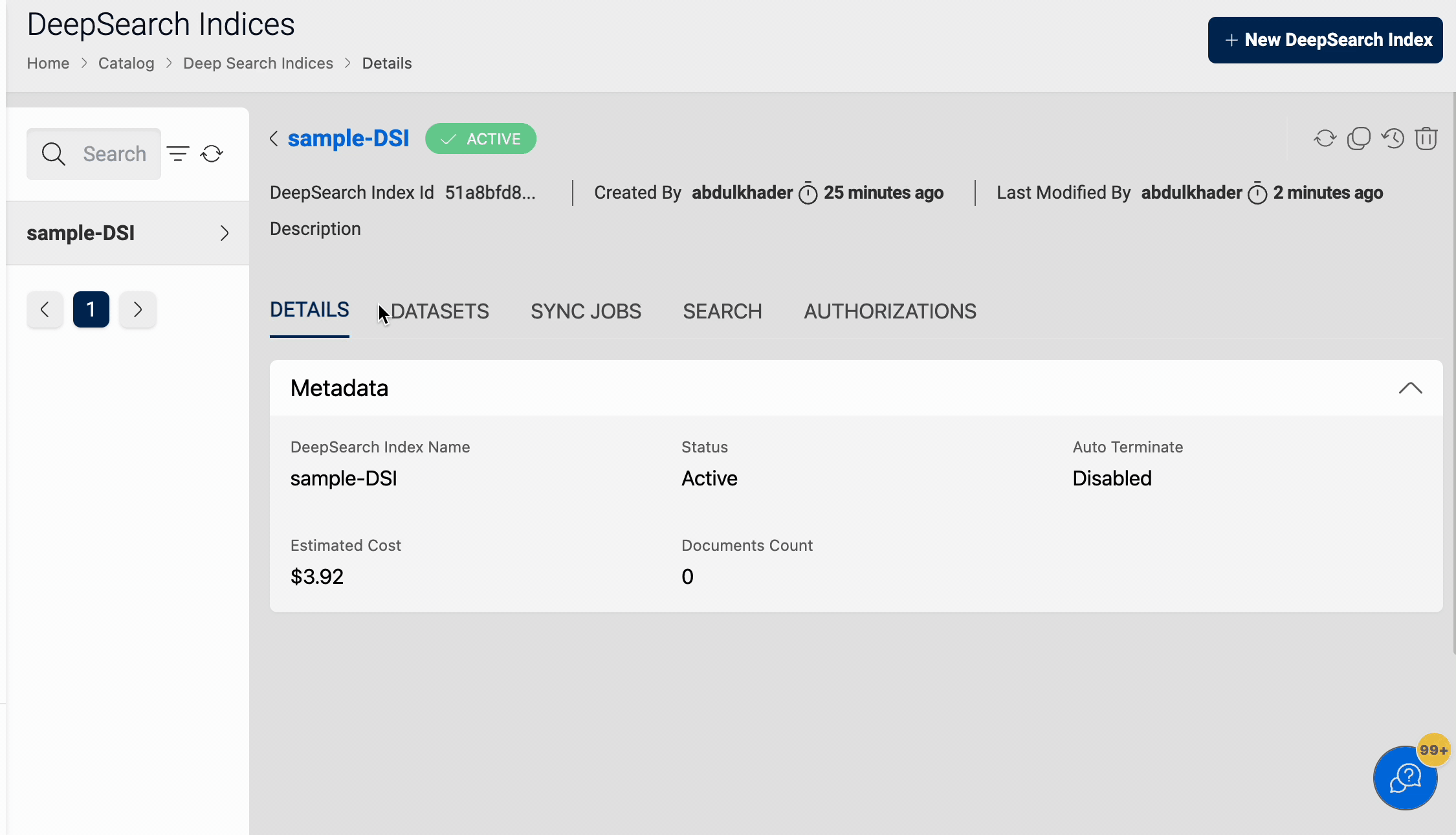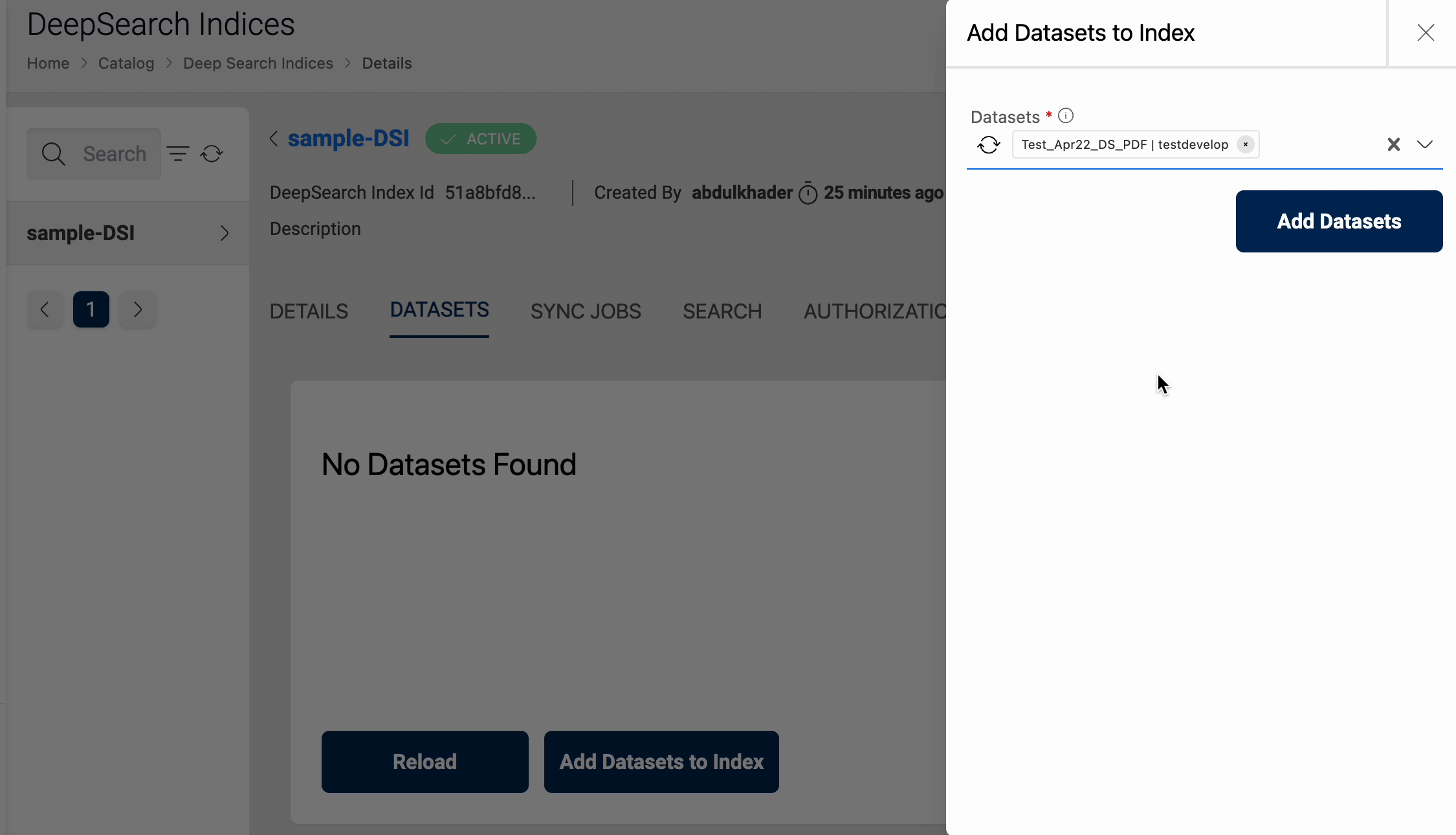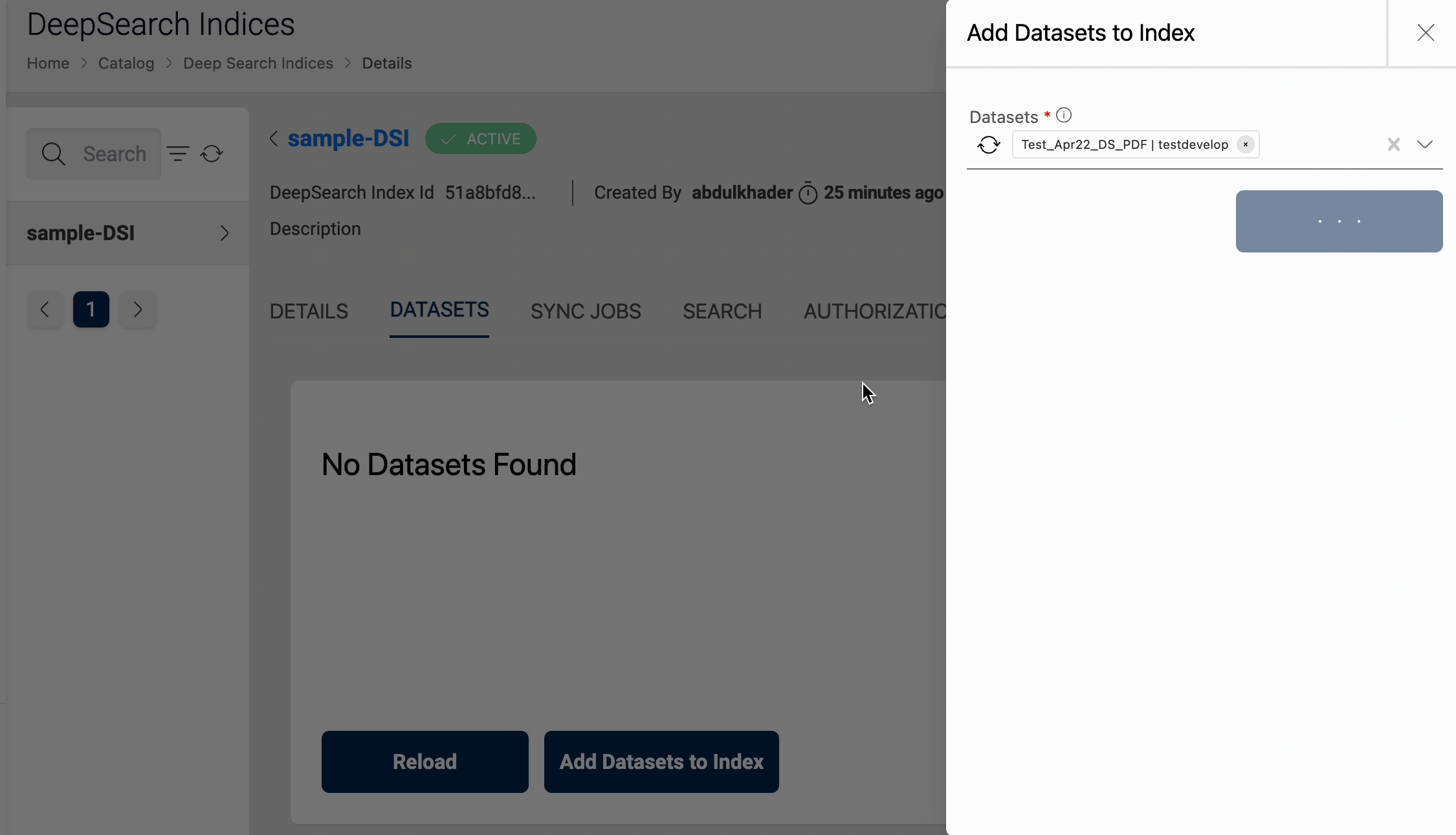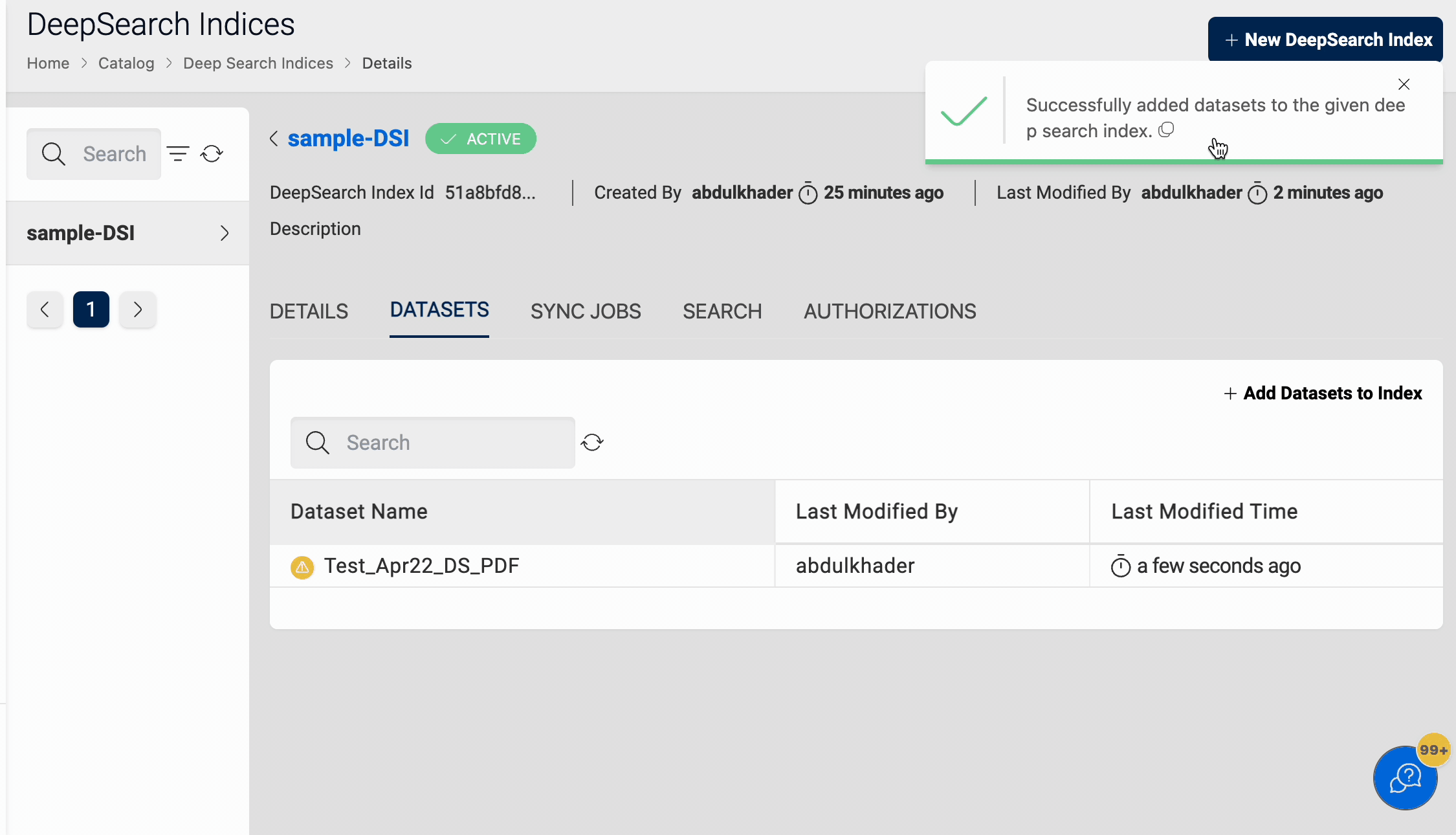
In the details page, the Estimated Cost of the deepsearch index is also displayed, to show the approximate cost incurred since the creation time.