
JDBC Connections
From version 2.2, encryption(in-flight, at-rest) for all jobs and catalog is enabled. All the existing jobs(User created, and also system created) were updated with encryption related settings, and all the newly created jobs will have encryption enabled automatically. Users should upgrade the connections to the latest version.
JDBC (Java Database Connectivity) is a Java API designed to facilitate connections to tabular data in various databases, with a particular focus on relational databases, and to execute queries.
Setting up a JDBC connection in Amorphic will help you migrate data from a JDBC source(s) to Amorphic Data Cloud. Further, you can directly write the data into the Amorphic datasets, using this connection.
How to set up a JDBC connection?

To create a connection, input the below details shown in the table or you can directly upload the JSON data.
Metadata
| Name | Description |
|---|---|
| Connection name | Give the connection a unique name |
| Description | Add connection description |
| Keywords | Add keyword tags to connect it with other Amorphic components. |
Connection configuration
| Connection Configuration | Description |
|---|---|
| Data load type | Select the data load type based on the data size, i.e. For a single table or smaller data size select Normal Load |
| JDBC Connection URL | The data source's JDBC connection url examples: General format: jdbc:protocol://host:port/dbname, jdbc:protocol://host:port;dbname=actual_name, jdbc:oracle:thin:@//HostName:Port/ServiceName(or)SID, jdbc:oracle:thin:@HostName:Port:SID, jdbc:oracle:thin:@HostName:Port/ServiceName(or)SID, jdbc:sqlserver://actual_servername\\actual_instancename:port;databaseName=actual_name, jdbc:mysql:loadbalance://hostname:port/database_name, jdbc:mysql:replication://hostname:port/database_name |
| Username | This is the username of the source database starting with ‘u_’ — For example, “u_Johndoe” |
| Password | The password is of the database from where you are loading data. Note: You can reset the password from profile & settings > reset DHW password |
| Connection Accessibility | Use the private connection if your data warehouse is hosted in an amazon virtual private cloud. |
| SSL | This field only applies to the Normal data load connections and is used when an additional level of security needs to be enforced. |
| Review & Submit | Review the information and submit it to create the connection. |
What Data load types apply to your use case?
In Amorphic, JDBC connections are either Bulk or Normal data loads. Let’s learn about their differences & implementations.
Bulk data load Connections
Bulk load connections are recommended to migrate a significant amount of data. The JDBC URL format varies from database to database. At present, the supported databases with JDBC connection types are:
Oracle, MySQL, PostgreSQL, Microsoft SQL Server, IBM Db2 (LUW), Aurora MySQL
Below is the difference between Bulk Data Load & Bulk Data Load v2.
Bulk Data Load - This connection type is used to create datasets with the same schema as the source. While creating a connection, users can provide metadata to create datasets even before ingesting any data into them. For more details read How to set up bulk data load in Amorphic.
Bulk Data Load v2 - Bulk Data Load v2 - This connection type is used when, from the source, ingestion of multiple tables into a single dataset is required. Only supported in S3 target type of datasets. For more details read How to set up bulk data load (Version 2) in Amorphic.
With this feature, users have the capability to seamlessly ingest any volume of data without encountering any size limitations.
However, in the past, we had faced an issue with a 400KB limit for tasks in v1 type connections when user try to ingest large number of source tables. In response, we've redesigned the task storage system as a solution to this issue.
As a part of this enhancement, if the payload of the total task details exceeds 250KB, users will observe some changes in the user interface at the time of Task-Editing, which are outlined below:
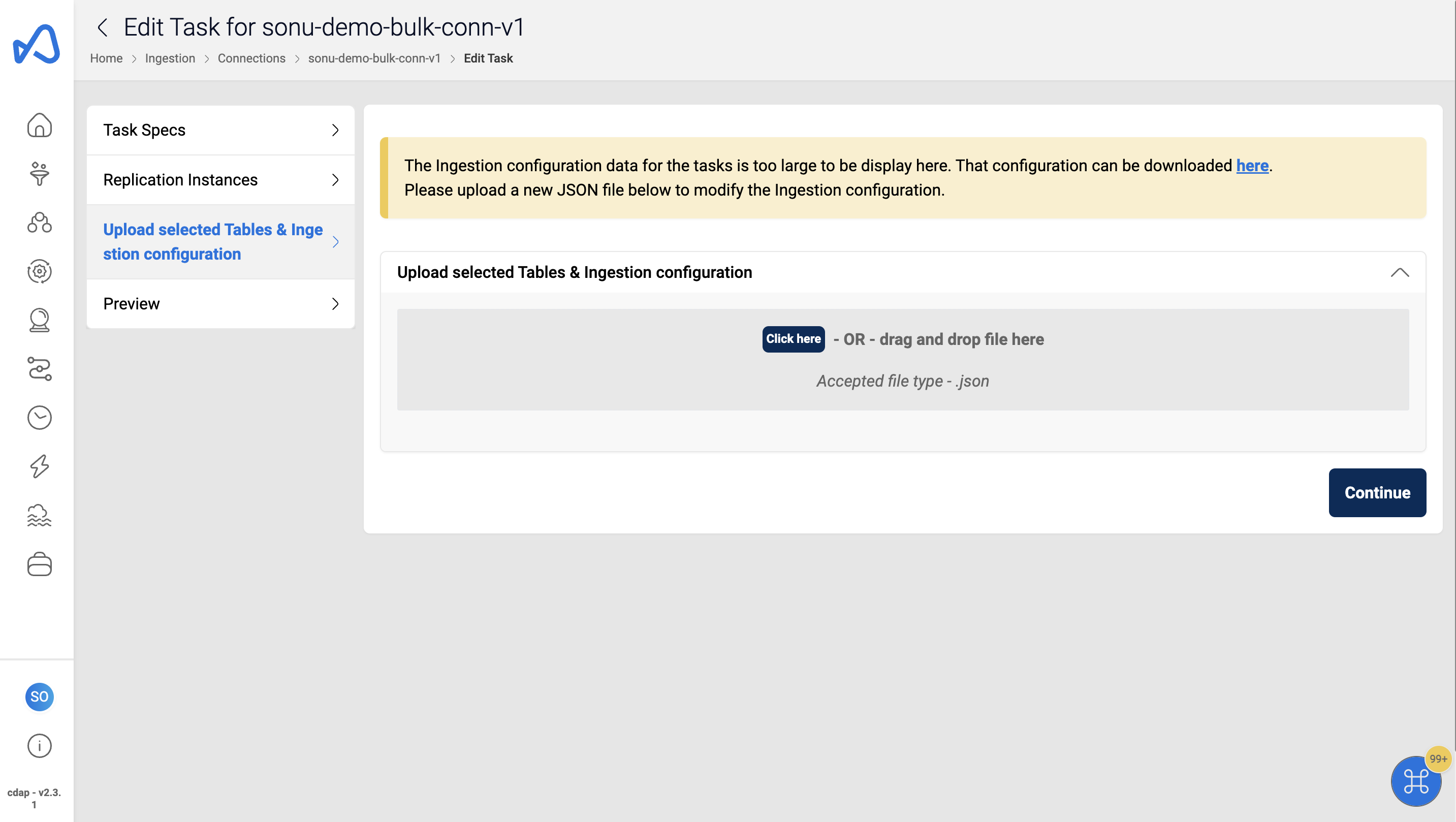
When users try to edit these larger tasks (exceeding 250KB), they can't edit the fields directly from the UI. As illustrated in the image above, an option is provided to download the payload as a JSON file. Users are required to download the file, make the necessary edits to the fields, and then upload the edited JSON file.
For payloads less than 250KB, the user experience remains unchanged, and users can edit these tasks just as they did before.
Normal data load Connections
Normal load connections are best to move one table or a small amount of data. The JDBC URL format changes depending on the database being used. This connection works for all data sources that AWS Glue supports, which you can find here.
Amazon Redshift (Both Provisioned and Serverless), Amazon RDS (Aurora, MS SQL Server, MySQL, Oracle, PostgreSQL), publicly accessible databases (Aurora, MariaDB, MS SQL Server, MySQL, Oracle, PostgreSQL, IBM Db2 (LUW)).
Additionally, the timeout for the ingestion process can be set during connection creation by adding a key IngestionTimeout to ConnectionDetails in the input payload. The value should be between 1 and 2880 and is expected in minutes. If the value is not provided the default value of 480(8hours) would be used. Please note that this feature is available exclusively via API.
{
"ConnectionDetails": {
"JdbcURL": "jdbc:mysql://example.com:3306/mydatabase",
"Username": "dbuser",
"Password": "StrongP@ss!",
"IngestionTimeout": 222
},
}
This timeout can be overridden during schedule creation and schedule run by providing an argument MaxTimeOut.
View connection details

What are tasks?
Tasks automate the data ingestion process in Amorphic. A task is a set of instructions that defines a data migration or replication process. It allows you to specify the name, migration type, target location, data format and extra connection attributes for the source and target databases. Read How to create a task.
What are instances?
An instance refers to a virtual server or a specific copy of a service that is used to run tasks. It can be used for various purposes such as loading large amounts of data into a database. Shared Instances is a feature that allows multiple tasks to run using a single instance. These instances are specific to a connection and independent of each other. Read How to create a instances
Test Connection
This functionality allows users to quickly verify the connectivity to the specified database. By initiating this test, users can confirm if the connection details provided are accurate and functional, ensuring seamless access to the database.

Version
You can choose which version of the ingestion scripts to use (specific to Amorphic). Whenever a new feature or Glue version is added to the underlying ingestion script, a new version will be added to Amorphic.
Upgrade
You can upgrade your connection if new versions are available. It will also update the underlying Glue version and the data ingestion script with new features.
Downgrade
You can downgrade a connection to previous version if you think the upgrade is not serving its purpose. A connection can only be downgraded if it has been upgraded.
Upgrade option is only applicable for jdbc normal load connection
Normal data load connection versions
2.1
In version 2.1, we made code changes to the underlying glue script to support dataset custom partitioning. Data will be loaded into an S3 LZ with a prefix containing the partition key (if specified) for the targets.
For example, if the partition keys are KeyA and KeyB with values ValueA and ValueB respectively, the S3 prefix will be in the format Domain/DatasetName/KeyA=ValueA/KeyB=ValueB/upload_date=YYYY-MM-DD/UserName/FileType/.
3.0
No changes were made to the underlying glue script or design, but the version was updated from 2.1 to 3.0 to match the AWS glue version.
3.1
In this version of the normal data load JDBC connection, we added support for the Skip LZ feature. This feature allows users to directly upload data to the data lake zone without having to go through data validation. For more information, refer to the Skip LZ related documentation.
4.0
No changes were made to the underlying glue script or design, but the version was updated from 3.1 to 4.0 to match the AWS glue version.
4.1
In this version of the normal data load JDBC connection, we made code changes to the glue script in-order to support glue encryption.
4.2
No major changes were made to the underlying glue script or design, but the logging has been enhanced.
4.3
The update in this version is specifically to ensure FIPS compliance, with no changes made to the script.