
Advanced usage of file load validation node
In advanced use cases where preceding ETL jobs can run concurrently, users must supply an input manifest file to the file load validation node for the identification of the correct files. Another scenario arises when users wish to incorporate multiple partitions alongside the default 'upload_date' partition. The following example combines these two cases.
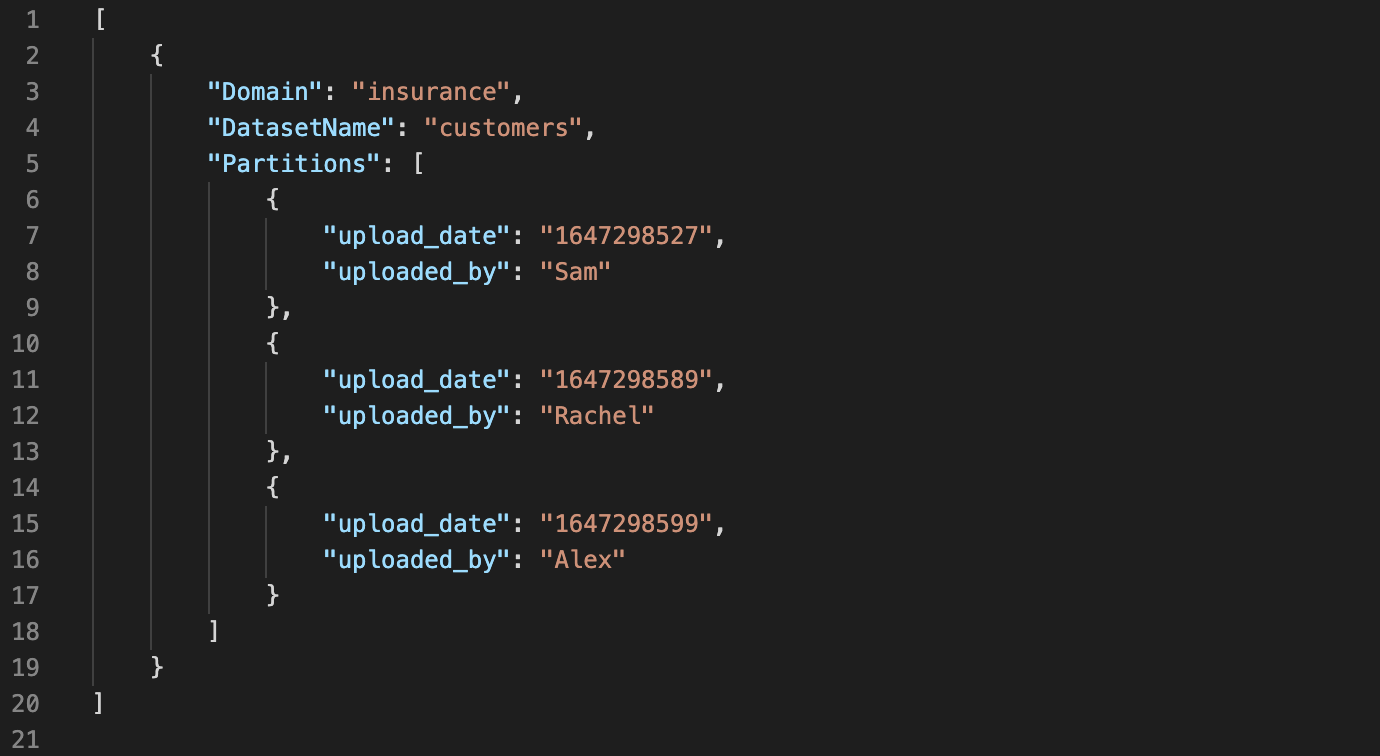
Following are the constraints for a valid input manifest file:
- File should be of type json
- File should contain the schema shown below
[{
"Domain": "string",
"DatasetName": "string",
"Partitions": [
{"upload_date": "string", "custom_partition": "string",......},
{"upload_date": "string", "custom_partition": "string",......},
......
]
},
............
]
- File should be written to the following s3 location:
s3://<etl_bucket_name>/<preceding_etl_job_id>/temp/manifest-files/<workflow_name>/workflow_execution_id-input_manifest_file.json
Important thing to note: The multi-partition concept only applies for datasets present in the S3-Athena Target Location
Here are some sample input manifest files:
Input manifest file for etl job writing to a single dataset:
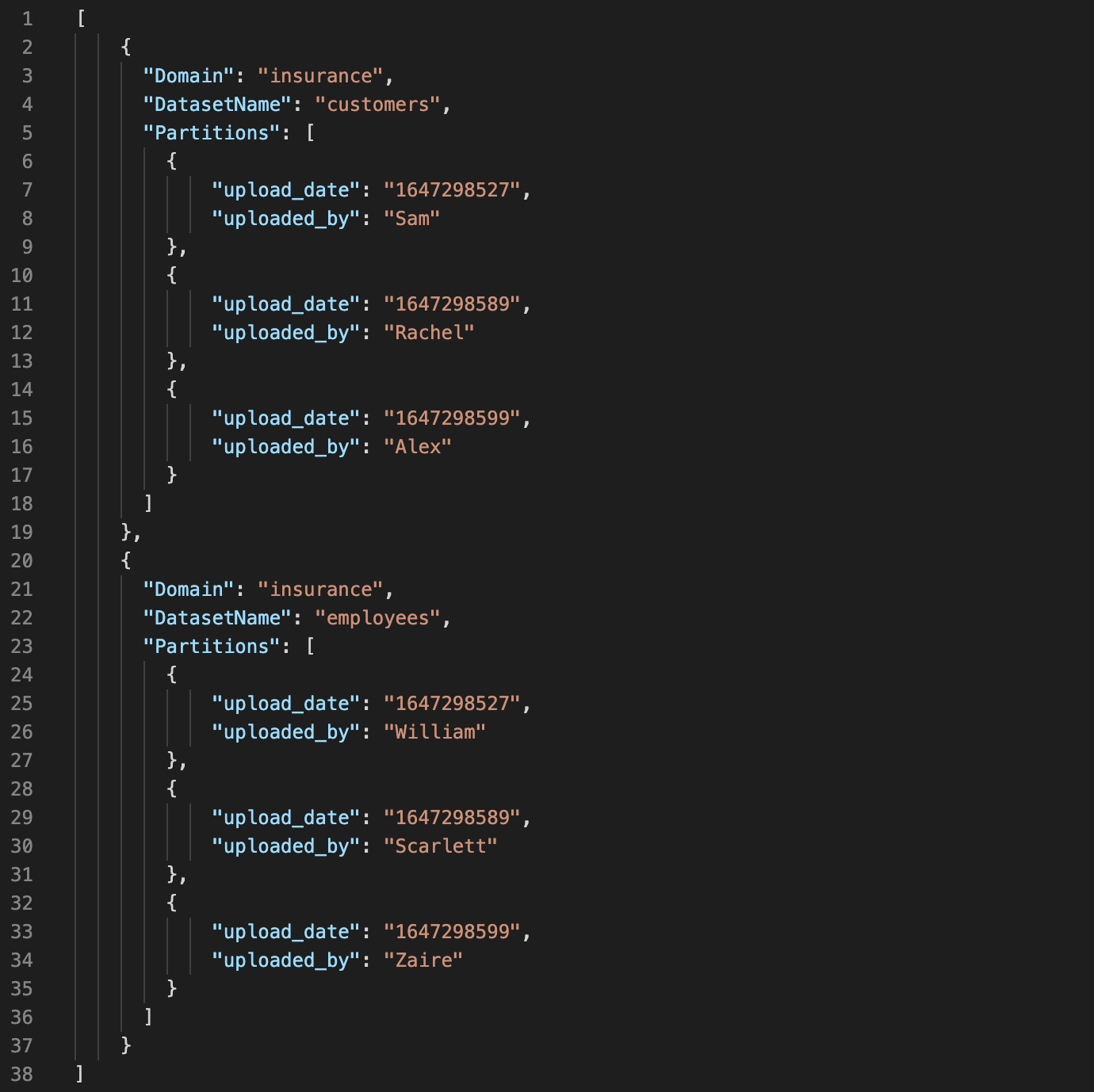
 Input manifest file for etl job writing to multiple datasets:
Input manifest file for etl job writing to multiple datasets:
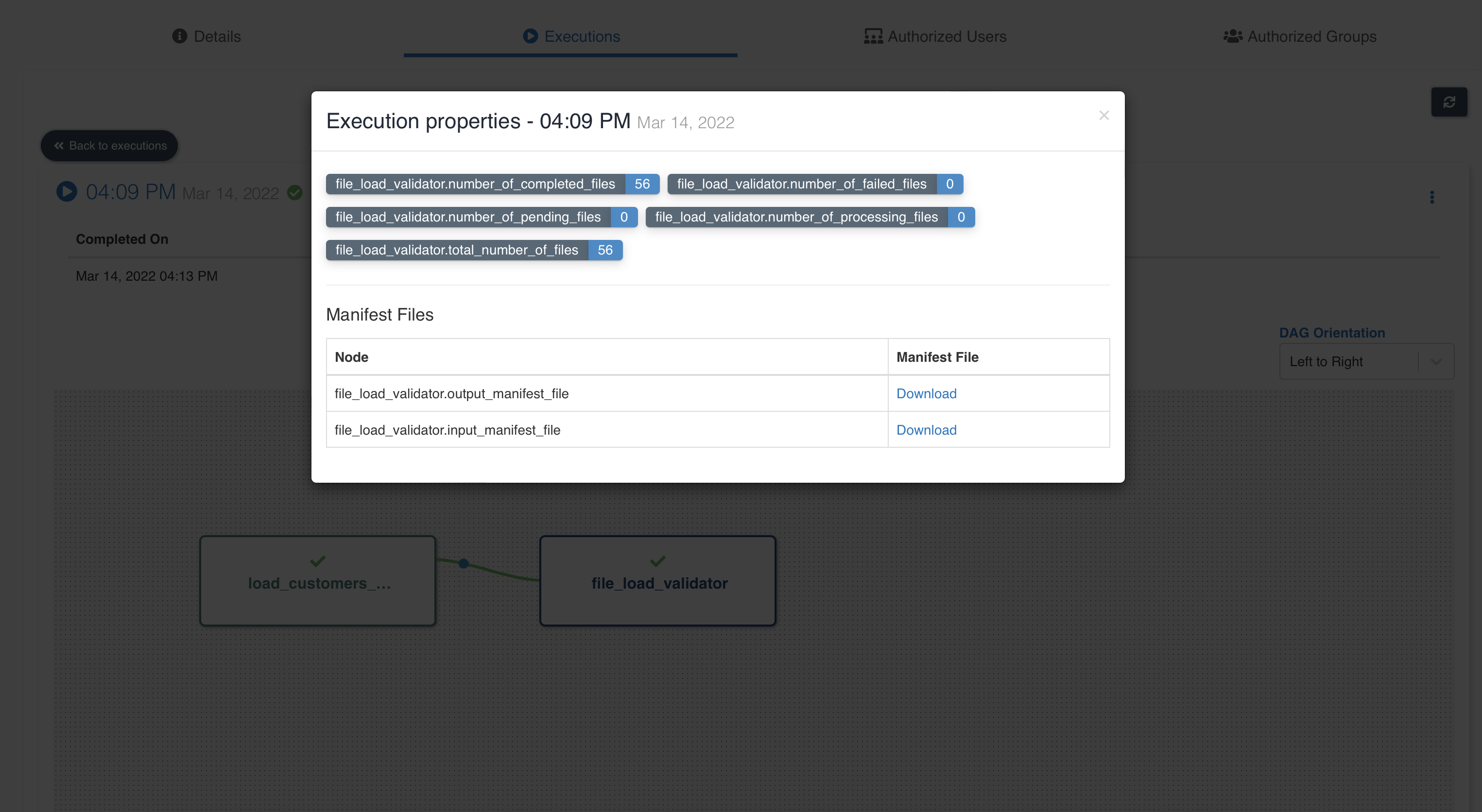
After workflow execution, workflow execution properties of file validation node is shown below:
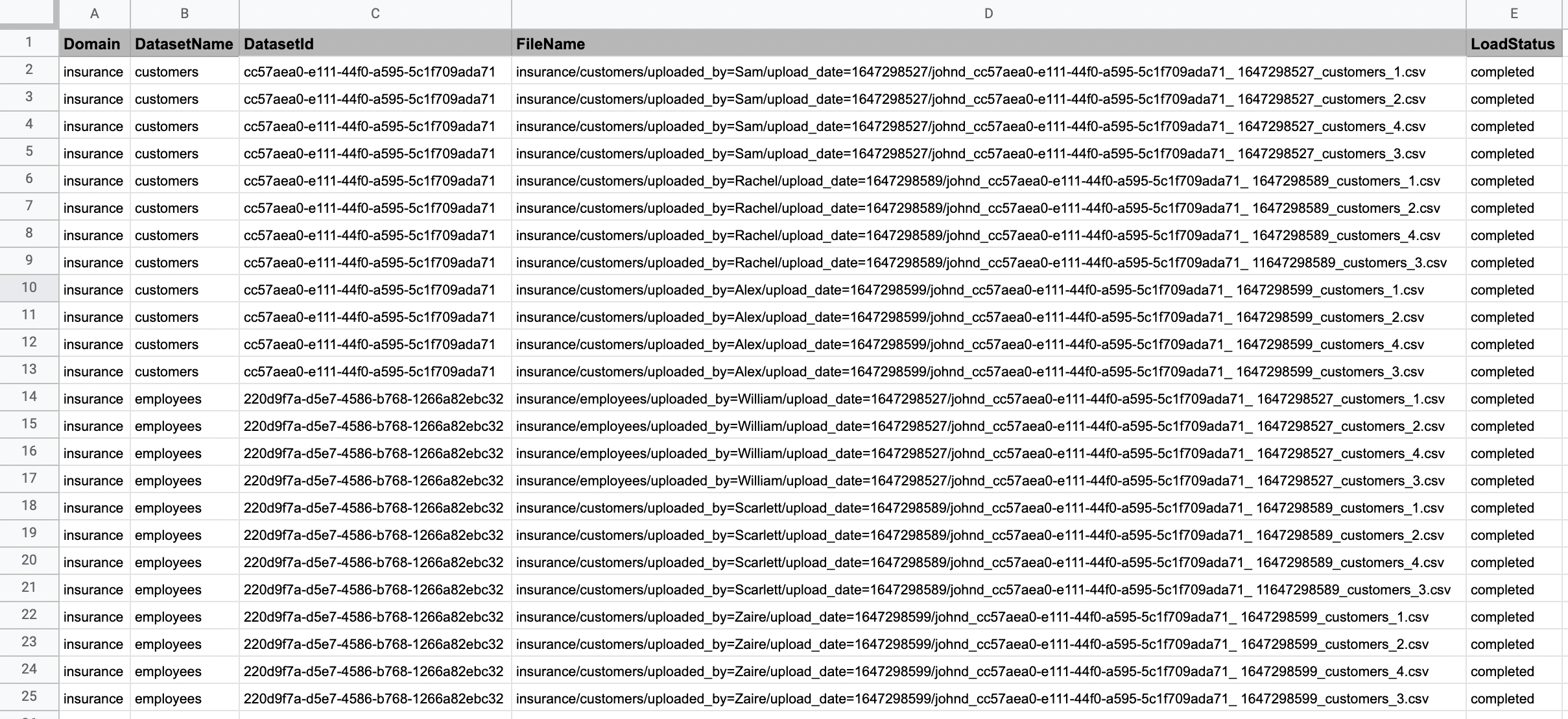
When you click 'Download' button next to output manifest file, you can see details of file load statuses as shown below:
Sample code snippet writing data to multiple datasets with multi-partition:
Data is written to customers dataset in insurance domain
Corresponding partitions of customers dataset are stored in a dict
Data is written to employees dataset in insurance domain
Corresponding partitions of employees are stored in a dict
Partition information of both datasets are written to etl bucket as input_manifest_file
It should be noted that all values written between < > should be replaced with the appropriate values in the below sample code
import os import sys import datetime import boto3 import time from awsglue.utils import getResolvedOptions import pandas as pd from io import StringIO import boto3 import json
def write_csv_dataframe_to_s3(s3_resource, dataframe, bucket, file_path):
"""
writes csv file to s3
"""
csv_buffer = StringIO()
dataframe.to_csv(csv_buffer, index=False)
s3_resource.Object(bucket, file_path).put(Body=csv_buffer.getvalue())
def write_json_manifest_file_to_s3(s3, json_data, file_path):
"""
writes json file to s3
"""
s3object = s3.Object('cdap-<region>-<aws_account_id>-master-etl', file_path)
s3object.put(Body=(bytes(json.dumps(json_data).encode('UTF-8'))))
json_data = []
args = getResolvedOptions(sys.argv, ['WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
s3 = boto3.resource('s3')
domain_name = 'insurance'
dataset_name = 'customers'
epoch_time = int(time.time())
epoch_time_str = str(epoch_time)
data = [['1', 'Alfreds Futterkiste', 'Maria Anders', 'Germany'], ['2', 'Ana Trujillo Emparedados y helados', 'Ana Trujillo', 'Mexico']]
df = pd.DataFrame(data, columns = ['CustomerID', 'CustomerName', 'ContactName', 'Country'])
path='{}/{}/uploaded_by={}/upload_date={}/<valid-amorphic-userID>/csv'.format(domain_name, dataset_name, 'Jeebu', epoch_time_str)
write_csv_dataframe_to_s3(s3, df, 'cdap-<region>-<aws_account_id>-master-lz', '{}/customers_1.csv'.format(path))
# Create a dict for domain, dataset combination and partition information
customers_partition_dict = {"Domain": domain_name, "DatasetName": dataset_name}
partitions = []
partitions.append({"uploaded_by":"Sam", "upload_date": epoch_time_str})
customers_partition_dict.update({"Partitions": partitions})
json_data.append(customers_partition_dict)
domain_name = 'insurance'
dataset_name = 'employees'
epoch_time = int(time.time())
epoch_time_str = str(epoch_time)
data = [['1', 'Alfreds Futterkiste', 'Maria Anders', 'Germany'], ['2', 'Ana Trujillo Emparedados y helados', 'Ana Trujillo', 'Mexico']]
df = pd.DataFrame(data, columns = ['CustomerID', 'CustomerName', 'ContactName', 'Country'])
path='{}/{}/uploaded_by={}/upload_date={}/<valid-amorphic-userID>/csv'.format(domain_name, dataset_name, 'Jeebu', epoch_time_str)
write_csv_dataframe_to_s3(s3, df, 'cdap-<region>-<aws_account_id>-master-lz', '{}/employees_1.csv'.format(path))
# Create a dict for domain, dataset combination and partition information
employees_partition_dict = {"Domain": domain_name, "DatasetName": dataset_name}
partitions = []
partitions.append({"uploaded_by":"Sam", "upload_date": epoch_time_str})
employees_partition_dict.update({"Partitions": partitions})
json_data.append(employees_partition_dict)
# Write json_data as input manifest file
file_path = "<etl_job_id>/temp/manifest-files/{}/{}-input_manifest_file.json".format(workflow_name, workflow_run_id)
write_json_manifest_file_to_s3(s3, json_data, file_path)