
Custom Script
Users can write custom logic for handling the file results in a python script. The script should follow the template specified below in order to work. The script needs to be defined in the 'DocumentHandler' class. Users can define other methods according to their requirements but the main logic needs to be defined in the 'execute_custom_script' method in the class. We have provided a script template which the users can take reference from in order to run the script
Script Template
As mentioned in in the template below, the script constructor would initialize the parameters such as file metadata and results returned from the business rules(if any). There are some sample methods for getting and setting result values and also for flagging the file or a target key for review. There are also a couple of methods related to textract-queries which are just added for reference
import logging
import boto3
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
class DocumentHandler:
def __init__(self, metadata, results):
"""Class constructor
Args:
metadata (object): Object containing metadata that can be useful in the script
Sample -> {
"FileKey": <s3_path_of_raw_file>,
"TextractOutputFileKey": <s3_path_of_textract_output_file>,
"AWSRegion": "",
"DataBucketName": <S3_bucket_containing_raw_and_textract_output_files>,
"ConfigBucketName": <S3_bucket_containing_config_file_if_present>,
"ConfigFileKey": <s3_path_of_config_file_if_present>
}
results (object): Object containing the key-value pairs returned from business rules along with some review details: {
Results: {
<key1>: <value>,
<key2>: <value>,
...
},
"ReviewStatus": "not-required"/"pending-review" -> Review Status at the file level
"Message": "" -> Add a message at file level
"KeyLevelReviewDetails": {
<key>: {
"FlagForReview": True/False, -> Flag a key for review
"Message": "", -> Add a message at a key level
"FlaggedBy": ""
}
} - Review Status at an individual key level
}
"""
self.metadata = metadata
self.results = results
self.output_dataset_keys = metadata['OutputDatasetKeys']
self.AWS_REGION = metadata['AWSRegion']
self.DATA_BUCKET_NAME = metadata['DataBucketName']
def get_results_object(self):
"""Returns all the key and values in results
Args:
"""
return self.results['Results']
def get_result_value(self, output_key):
"""Returns the value corresponding to a given key
Args:
output_key (string): Key whose value needs to be fetched
"""
if output_key in self.output_dataset_keys:
return self.results['Results'][output_key]
else:
LOGGER.error("The given key does not exist in the result data")
def set_result_value(self, output_key, result_value):
"""Update the value corresponding to the given key
Args:
output_key (string): Key whose value needs to be updated
result_value (string): Updated value corresponding to the given key
"""
if output_key in self.output_dataset_keys:
self.results['Results'][output_key] = result_value
else:
LOGGER.error("The provided key - %s is not a part of the OutputDatasetKeys", output_key)
def flag_file(self, message = ''):
"""Flag the file for review
Args:
message (str, optional): Message stating the reason for flagging. Defaults to ''.
"""
self.results['ReviewStatus'] = 'pending-review'
if message:
self.results['Message'] = message
def flag_result(self, output_key, message = ''):
"""Flag a particular key for review
Args:
output_key (string): Key that needs to be flagged
message (str, optional): Message stating the reason for flagging. Defaults to ''.
"""
if output_key in self.output_dataset_keys:
self.results['KeyLevelReviewDetails'][output_key]['FlagForReview'] = True
if message:
self.results['KeyLevelReviewDetails'][output_key]['Message'] += f"\n{message}"
else:
LOGGER.error("The provided key - %s is not a part of the OutputDatasetKeys", output_key)
def get_query_result_by_id(self, response, id):
"""Get the value and confidence score for a QUERY_RESULT block with given Id.
Args:
response (json): JSON response returned by textract
id (string): Id for to the query result block
Returns:
object: Value & confidence score if found, otherwise None
"""
for b in response["Blocks"]:
if b["BlockType"] == "QUERY_RESULT" and b["Id"] == id:
return {
"Value": b.get("Text"),
"Confidence": b.get("Confidence")
}
return None
def get_query_results_for_alias(self, response, q_alias):
"""Get a list of query results (value & confidence score) for a given alias
Args:
response (json): JSON response returned by textract
q_alias (string): alias used in query
Returns:
object[]: List of query results for the given alias
[
{
"value": <query_result>,
"confidence": <confidence_score_if_present>
}
]
"""
results = []
for b in response["Blocks"]:
if b["BlockType"] == "QUERY" and b["Query"]["Alias"] == q_alias:
if b.get("Relationships"):
ref_id = b["Relationships"][0]["Ids"][0]
result = self.get_query_result_by_id(response, ref_id)
if result:
results.append(result)
return results
def run_synchronous_textract_queries(self, queries):
"""Run a list of synchronous textract queries for the file and get the response
Note: In case textract query fails due to Throughput Exception, you can define a textract client with custom config with more retries
from botocore.client import Config
max_attempts = <define_according_to_use_case> (default retries is 3)
config = Config(retries = dict(max_attempts=max_attempts, mode="standard"))
TEXTRACT_CLIENT = boto3.client("textract", region_name=AWS_REGION, config=config)
Args:
queries (object[]): List of queries to run
[
{
"Text": "",
"Alias": "" (optional),
"Pages": "" (optional, defaulted to ["1-*"])
}
]
Returns:
(json): json response from textract queries
"""
textract_client = boto3.client('textract', self.AWS_REGION)
queries_config = []
for query in queries:
config = {
'Text': query['Text'],
'Pages': query.get('Pages', ["*"])
}
if query.get("Alias"):
config.update({
'Alias': query['Alias']
})
queries_config.append(config)
file_key = self.metadata['FileKey']
response = textract_client.analyze_document(
Document = {
'S3Object': {
'Bucket': self.DATA_BUCKET_NAME,
'Name': file_key
}
},
FeatureTypes=["QUERIES"],
QueriesConfig = {
'Queries': queries_config
}
)
return response
def execute_custom_script(self):
"""Write the custom code for the given script here
"""
Custom Script Run logs
Whenever a custom script is defined for a process flow and user needs to check if the script is running as expected, they can download the run logs for that particular run. Users can check and download the logs from the details of that run.
Below image shows how to download the run logs

Custom Script Configuration
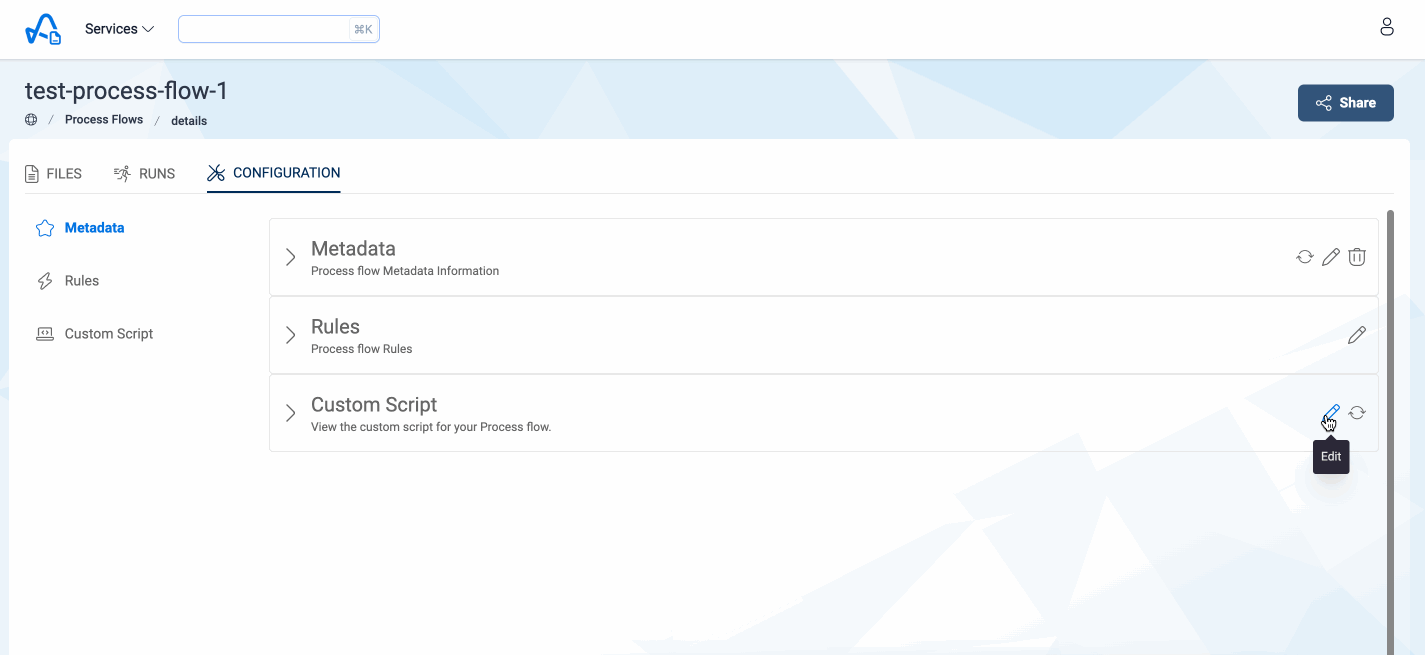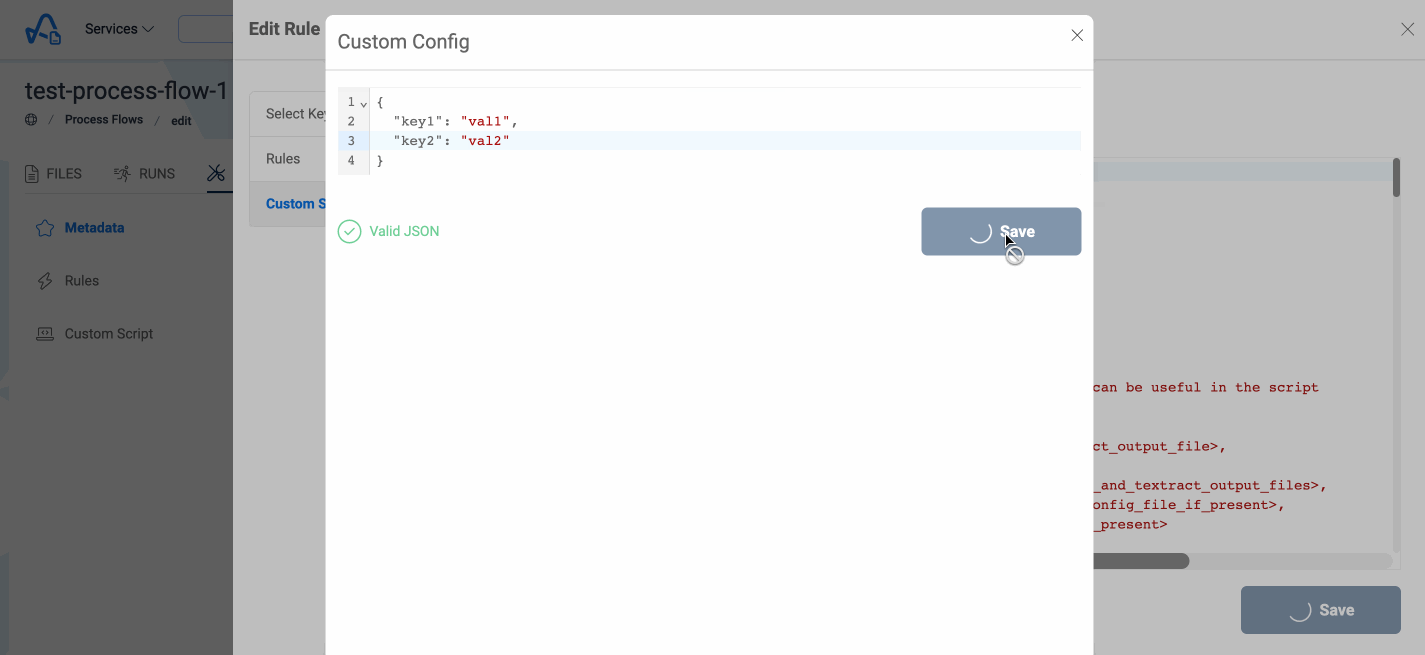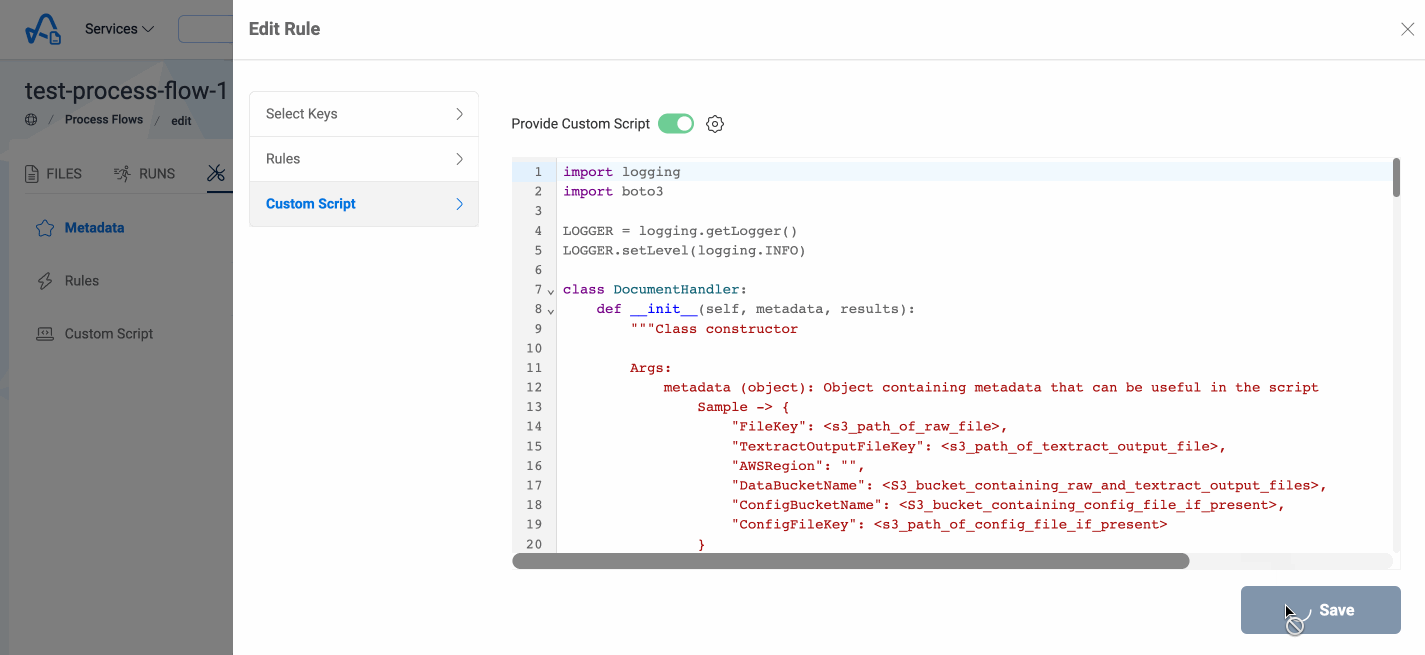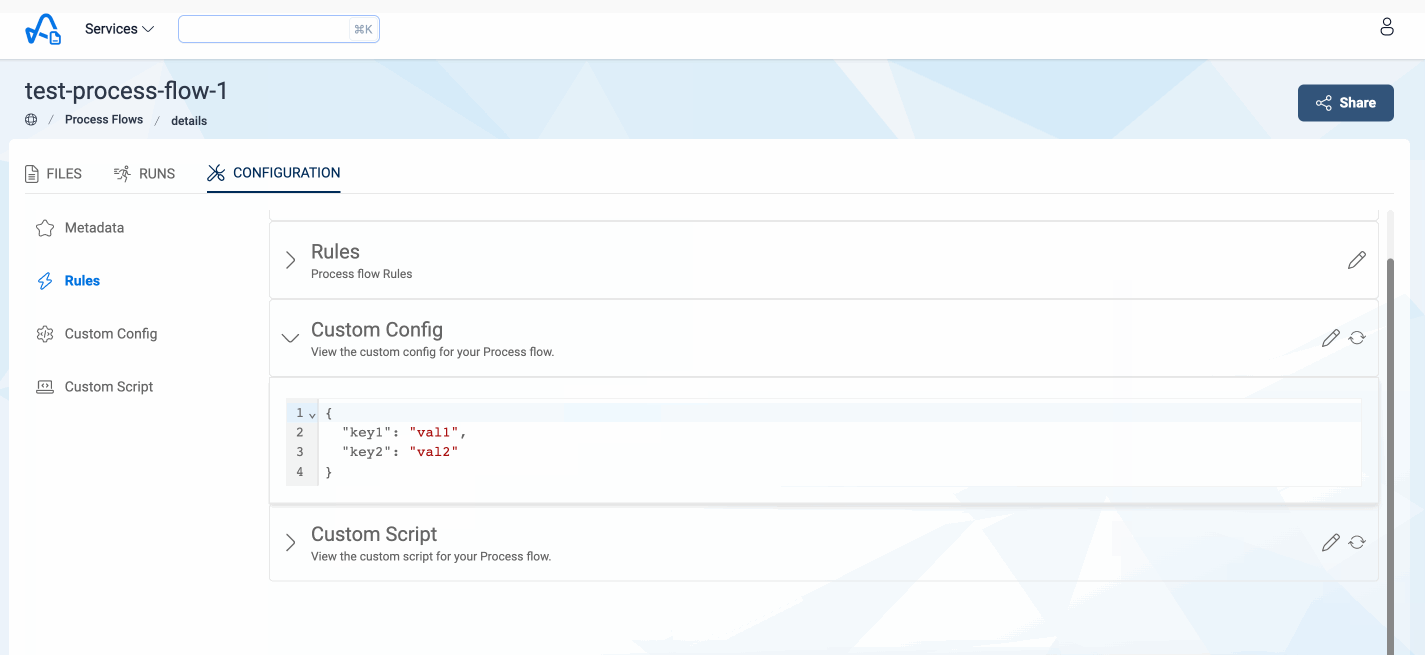
Users can also define a specific json configuration which they want to access in the custom script. They can define it while updating the process flow
and if provided the file would be uploaded to S3. This file can be accessed in the custom script using the ConfigBucketName and the ConfigFileKey properties
present in the metadata object.
Below image shows how to add a configuration for custom script
Sample snippet for accessing the custom configuration in the custom script
def execute_custom_script(self):
"""Write the custom code for the given script
"""
config_bucket_name = self.metadata['ConfigBucketName']
config_file_key = self.metadata['ConfigFileKey']
# Get the S3 object
response = s3_client.get_object(Bucket=config_bucket_name, Key=config_file_key)
# Read the content of the object
object_content = response['Body'].read()
# Parse the JSON content
config_json_data = json.loads(object_content.decode('utf-8'))
# Now you can work with the JSON data as required
print(config_json_data)