
Custom Script
Users can create custom logic for processing file results using a Python script. The script must adhere to the specified template for it to function correctly.
This script should be defined within the DocumentHandler class. While users have the flexibility to define additional methods as per their needs, the primary logic should be implemented within the execute_custom_script method within the class.
To assist users, we have supplied a script template that they can refer to when crafting their script.
Script Template
As mentioned in in the template below, the DocumentHandler class's constructor would initialize the parameters such as file metadata and results returned from the business rules(if any). There are several sample methods mentioned in this template, which provide the following functionalites:
- For retrieving and updating result values.
- For marking a file or a target key for review.
- For marking a file for rejection.
- For suggesting updates to a target key.
- For running textract queries.
- For retrieving Parameters created in the application.
- For invoking a large language model from Bedrock/OpenAI.
import logging
import os
import base64
from typing import Any
import boto3
from botocore.client import Config
from pdf2image import convert_from_path
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.outputs import LLMResult
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import BedrockChat
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
class TokenUsageCallbackHandler(BaseCallbackHandler):
'''Callback Handler that tracks bedrock/openai tokens info.'''
input_tokens: int = 0
output_tokens: int = 0
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
'''Collect token usage.'''
if response.llm_output is None:
return None
if 'usage' in response.llm_output:
token_usage = response.llm_output["usage"]
elif 'token_usage' in response.llm_output:
token_usage = response.llm_output["token_usage"]
else:
return None
input_tokens = token_usage.get('prompt_tokens', 0)
output_tokens = token_usage.get('completion_tokens', 0)
self.input_tokens += input_tokens
self.output_tokens += output_tokens
class DocumentHandler:
def __init__(self, metadata, results):
'''Class constructor
Args:
metadata (object): Object containing metadata that can be useful in the script
Sample -> {
'FileKey': <s3_path_of_raw_file>,
'TextractOutputFileKey': <s3_path_of_textract_output_file>, # deprecated, use ModelOutputFileKey
'ModelOutputFileKey': <s3_path_of_model_output_file>,
'AWSRegion': '',
'DataBucketName': <S3_bucket_containing_raw_and_textract_output_files>,
'ConfigBucketName': <S3_bucket_containing_config_file_if_present>,
'ConfigFileKey': <s3_path_of_config_file_if_present>
'ProjectShortName' : '',
'VerticalName' : '',
'AWS_USE_FIPS_ENDPOINT' : <whether FIPS is enabled or not>
}
results (object): Object containing the key-value pairs returned from business rules along with some review details: {
Results: {
<key1>: <value>,
<key2>: <value>,
...
},
'ReviewStatus': 'not-required'/'pending-review' -> Review Status at the file level
'Message': '' -> Add a message at file level
'KeyLevelReviewDetails': {
<key>: {
'FlagForReview': True/False, -> Flag a key for review
'Message': '', -> Add a message at a key level
'FlaggedBy': ''
}
}, -> Review Status at an individual key level
'ReviewDetails' : {
'LastModifiedBy': user_id/model_id,
'Updates': {
<key1>: <value>,
<key2>: <value>,
...
}
} -> Suggestions for the output keys,
}
'''
self.metadata = metadata
self.results = results
self.output_dataset_keys = metadata['OutputDatasetKeys']
self.AWS_REGION = metadata['AWSRegion']
self.DATA_BUCKET_NAME = metadata['DataBucketName']
self.usage_info = {'InputAIU': None, 'OutputAIU': None, 'ModelName': None}
def get_results_object(self):
'''Returns all the key and values in results
Args:
'''
return self.results['Results']
def get_result_value(self, output_key):
'''Returns the value corresponding to a given key
Args:
output_key (string): Key whose value needs to be fetched
'''
if output_key in self.output_dataset_keys:
return self.results['Results'][output_key]
else:
LOGGER.error('The given key does not exist in the result data')
def set_result_value(self, output_key, result_value):
'''Update the value corresponding to the given key
Args:
output_key (string): Key whose value needs to be updated
result_value (string): Updated value corresponding to the given key
'''
if output_key in self.output_dataset_keys:
self.results['Results'][output_key] = result_value
else:
LOGGER.error('The provided key - %s is not a part of the OutputDatasetKeys', output_key)
def flag_file_for_review(self, message = ''):
'''Flag the file for review
Args:
message (str, optional): Message stating the reason for flagging. Defaults to ''.
'''
self.results['ReviewStatus'] = 'pending-review'
if message:
self.results['Message'] = message
def flag_file_for_rejection(self, message = ''):
'''Flag the file for rejection
Args:
message (str, optional): Message stating the reason for flagging. Defaults to ''.
'''
self.results['ReviewStatus'] = 'pending-rejection'
if message:
self.results['Message'] = message
def flag_result(self, output_key, message = '', key_type = 'top-level'):
'''Flag a particular key for review
Args:
output_key (string): Key that needs to be flagged
message (str, optional): Message stating the reason for flagging. Defaults to ''.
key_type(str, optional): Specifies the type of key - top-level or nested.
If nested, the attribute needs to be represented in dot format, using 0 index.
Eg: For a field like this - "data":[
{
"Key1": "Val1"
},
{
"Key1": "Val1",
"Key2": "Val2"
}
]
data.1.key2 will refer to Key2 at the 1st index of the above item.
'''
if key_type == 'top-level':
if output_key in self.output_dataset_keys:
self.results['KeyLevelReviewDetails'][output_key]['FlagForReview'] = True
if message:
self.results['KeyLevelReviewDetails'][output_key]['Message'] += f'\\n{message}'
else:
LOGGER.error('The provided key - %s is not a part of the OutputDatasetKeys', output_key)
elif key_type == 'nested':
self.results['KeyLevelReviewDetails'][output_key]['FlagForReview'] = True
if message:
self.results['KeyLevelReviewDetails'][output_key]['Message'] += f'\\n{message}'
def suggest_result_value(self, output_key, result_value, modified_by = ''):
'''Suggest a value for a particular key
Args:
output_key (string): Target key for the suggestion
result_value (string): Suggested value corresponding to the given key
'''
if output_key in self.output_dataset_keys:
self.results['ReviewDetails']['LastModifiedBy'] = modified_by
self.results['ReviewDetails']['Updates'][output_key] = result_value
self.results['ReviewStatus'] = 'pending-approval'
else:
LOGGER.error('The provided key - %s is not a part of the OutputDatasetKeys', output_key)
def get_query_result_by_id(self, response, id):
'''Get the value and confidence score for a QUERY_RESULT block with given Id.
Args:
response (json): JSON response returned by textract
id (string): Id for to the query result block
Returns:
object: Value & confidence score if found, otherwise None
'''
for b in response['Blocks']:
if b['BlockType'] == 'QUERY_RESULT' and b['Id'] == id:
return {
'Value': b.get('Text'),
'Confidence': b.get('Confidence')
}
return None
def get_query_results_for_alias(self, response, q_alias):
'''Get a list of query results (value & confidence score) for a given alias
Args:
response (json): JSON response returned by textract
q_alias (string): alias used in query
Returns:
object[]: List of query results for the given alias
[
{
'value': <query_result>,
'confidence': <confidence_score_if_present>
}
]
'''
results = []
for b in response['Blocks']:
if b['BlockType'] == 'QUERY' and b['Query']['Alias'] == q_alias:
if b.get('Relationships'):
ref_id = b['Relationships'][0]['Ids'][0]
result = self.get_query_result_by_id(response, ref_id)
if result:
results.append(result)
return results
def run_synchronous_textract_queries(self, queries):
'''Run a list of synchronous textract queries for the file and get the response
Note: In case textract query fails due to Throughput Exception, you can define a textract client with custom config with more retries
from botocore.client import Config
max_attempts = <define_according_to_use_case> (default retries is 3)
config = Config(retries = dict(max_attempts=max_attempts, mode='standard'))
TEXTRACT_CLIENT = boto3.client('textract', region_name=AWS_REGION, config=config)
Args:
queries (object[]): List of queries to run
[
{
'Text': '',
'Alias': '' (optional),
'Pages': '' (optional, defaulted to ['1-*'])
}
]
Returns:
(json): json response from textract queries
'''
textract_client = boto3.client('textract', self.AWS_REGION)
queries_config = []
for query in queries:
config = {
'Text': query['Text'],
'Pages': query.get('Pages', ['*'])
}
if query.get('Alias'):
config.update({
'Alias': query['Alias']
})
queries_config.append(config)
file_key = self.metadata['FileKey']
response = textract_client.analyze_document(
Document = {
'S3Object': {
'Bucket': self.DATA_BUCKET_NAME,
'Name': file_key
}
},
FeatureTypes=['QUERIES'],
QueriesConfig = {
'Queries': queries_config
}
)
return response
def get_presigned_url(self, object_key, output_file_key, disposition_type='attachment', **kwargs):
'''
Generate a presigned URL for downloading files from s3
'''
s3_endpoint_url = f"https://s3.{self.AWS_REGION}.amazonaws.com" if self.metadata['AWS_USE_FIPS_ENDPOINT'] == 'False' else f"https://s3-fips.{self.AWS_REGION}.amazonaws.com"
s3_client = boto3.client('s3', endpoint_url=s3_endpoint_url, region_name=self.AWS_REGION, config=Config(signature_version='s3v4', s3 ={'addressing_style':'virtual'}))
params = {
'Bucket': self.DATA_BUCKET_NAME,
'Key': '{}'.format(object_key),
'ResponseContentDisposition': '{}; filename={}'.format(disposition_type, output_file_key)
}
if kwargs.get('response_content_type'):
params['ResponseContentType'] = kwargs['response_content_type']
url = s3_client.generate_presigned_url(
ClientMethod='get_object',
Params=params
)
LOGGER.info('In commonUtil.get_presigned_url, Successfully generated S3 signed url')
return url
def get_parameter_value(self, parameter_key:str) -> str:
'''
Retrieve a parameter from parameter store
Args:
parameter_key (string): Name of the parameter
Returns:
string: Value of the parameter
'''
ssm_client = boto3.client('ssm', self.AWS_REGION)
project_short_name = self.metadata['ProjectShortName']
vertical_name = self.metadata['VerticalName']
parameter = ssm_client.get_parameter(
Name=f'/{project_short_name}/{vertical_name}/parameters/{parameter_key}',
WithDecryption=True
)
return parameter['Parameter']['Value']
def pdf_to_images(self, pdf_file:str, output_folder:str) -> list:
'''
Convert a PDF file to a series of images and store them in /tmp/output_folder directory
Args:
pdf_file (string): Path to the PDF file
output_folder (string): Name of the output folder where images will be saved
Returns:
list: A list of paths to the converted image files.
'''
directory_path = f'/tmp/{output_folder}'
os.makedirs(directory_path, exist_ok=True)
file_name_with_extension = pdf_file.split('/')[-1]
file_name = file_name_with_extension.split('.')[0]
image_paths = []
images = convert_from_path(pdf_file, dpi=150)
# Save each image as a separate file
for index, image in enumerate(images):
image_path = f'{directory_path}/{file_name}_page_{index+1}.jpg'
image.save(image_path, 'JPEG')
image_paths.append(image_path)
return image_paths
def download_file_from_s3(self, file_key:str, output_folder:str) -> None:
'''
Download a file from s3 to /tmp/output_folder directory
Args:
file_key (string): File Key of the file stored in s3
output_folder (string): Name of the output folder
Returns:
string: Path of the downloaded file
'''
directory_path = f'/tmp/{output_folder}'
file_name = file_key.split('/')[-1]
os.makedirs(directory_path, exist_ok=True)
s3_endpoint_url = f"https://s3.{self.AWS_REGION}.amazonaws.com" if self.metadata['AWS_USE_FIPS_ENDPOINT'] == 'False' else f"https://s3-fips.{self.AWS_REGION}.amazonaws.com"
s3_client = boto3.client('s3', endpoint_url=s3_endpoint_url, region_name=self.AWS_REGION, config=Config(signature_version='s3v4', s3 ={'addressing_style':'virtual'}))
with open(f'{directory_path}/{file_name}', 'wb') as data:
s3_client.download_fileobj(self.DATA_BUCKET_NAME, file_key, data)
return f'{directory_path}/{file_name}'
@staticmethod
def encode_file(file_path:str) -> str:
'''
Base64 encode the given file
Args:
file_path (string): Path to the image file
Returns:
string: Base64 encoded string of the file content
'''
with open(file_path, 'rb') as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_response_from_model(self, user_prompt:str, images_list: list, image_format:str, model_provider: str, model_name: str, openai_api_key:str=None) -> dict:
'''
Invoke a model to extract information from images
Args:
user_prompt (string): User prompt for the model
images_list (list[str]): List of images. Either URLs or base64 encoded strings
image_format (string): Format of the images. Can be url/base64
model_provider (string): Provider of the model. Can be openai/bedrock
model_name (string): Name of the model. Refer openai/bedrock documentation for the exact name
openai_api_key (string): OpenAI API key. Required only if model_provider is openai
Returns:
dict: JSON response returned from model
'''
# Output parser configuration
parser = JsonOutputParser()
# Prompt related configurations
human_messages_list = [
{'type': 'text', 'text': user_prompt},
]
for image in images_list:
content = {
'type': 'image_url',
'image_url': {
'url': f'data:image/jpeg;base64,{image}' if image_format == 'base64' else image
}
}
human_messages_list.append(content)
human_messages_list.append({"type": "text", "text": "Return a JSON object. If there is any comma in between numbers, remove that comma and parse only numbers"})
system_message = """
You are an advanced data entry specialist who can extract key information from a given image with remarkable accuracy and precision.
You double check every key because a small mistake leads to a direct loss in revenue. Repeated mistakes can possibly lead to you getting fired.
Your job is to extract a JSON object which is clean and can be loaded through json.loads()
- no additional characters or text from your side.'
"""
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(content=system_message),
HumanMessage(content=human_messages_list),
]
)
# Model related configurations
model = None
if model_provider == "openai":
model = ChatOpenAI(
model=model_name,
max_tokens=4096,
openai_api_key=openai_api_key,
)
elif model_provider == "bedrock":
bedrock_runtime_client = boto3.client(
service_name="bedrock-runtime",
region_name=self.AWS_REGION,
)
model_kwargs = {
"max_tokens": 4096
}
model = BedrockChat(
client=bedrock_runtime_client,
model_id=model_name,
model_kwargs=model_kwargs,
)
else:
raise Exception(f"Invalid model provider - {model_provider}")
# Callback config
handler = TokenUsageCallbackHandler()
config = {"callbacks": [handler]}
try:
# Create a LLM chain and invoke it
chain = prompt | model | parser
response = chain.invoke({'user_prompt':user_prompt}, config=config)
except Exception as ex:
LOGGER.error('LLM chain failed due to error: %s', str(ex))
raise Exception(str(ex)) from ex
self.usage_info['InputAIU'] = handler.input_tokens
self.usage_info['OutputAIU'] = handler.output_tokens
self.usage_info['ModelName'] = model_name
return response
def execute_custom_script(self):
'''Write the custom code for the given script
'''`;
Custom Script Run logs
Whenever a custom script is defined for a process flow, and a user wishes to verify if the script is functioning as intended, they can access and download the run logs for that specific run. Users can review and retrieve these logs directly from the details of the corresponding run.
Below image shows how to download the run logs

Custom Script Configuration
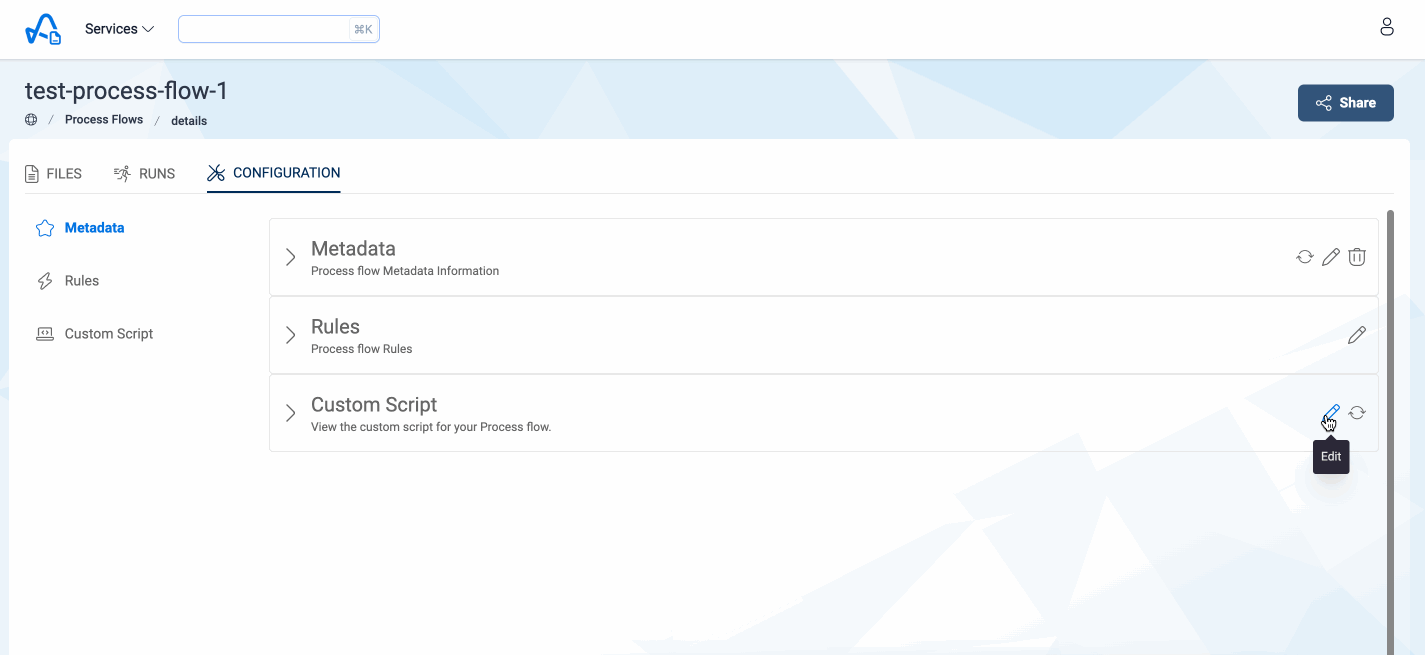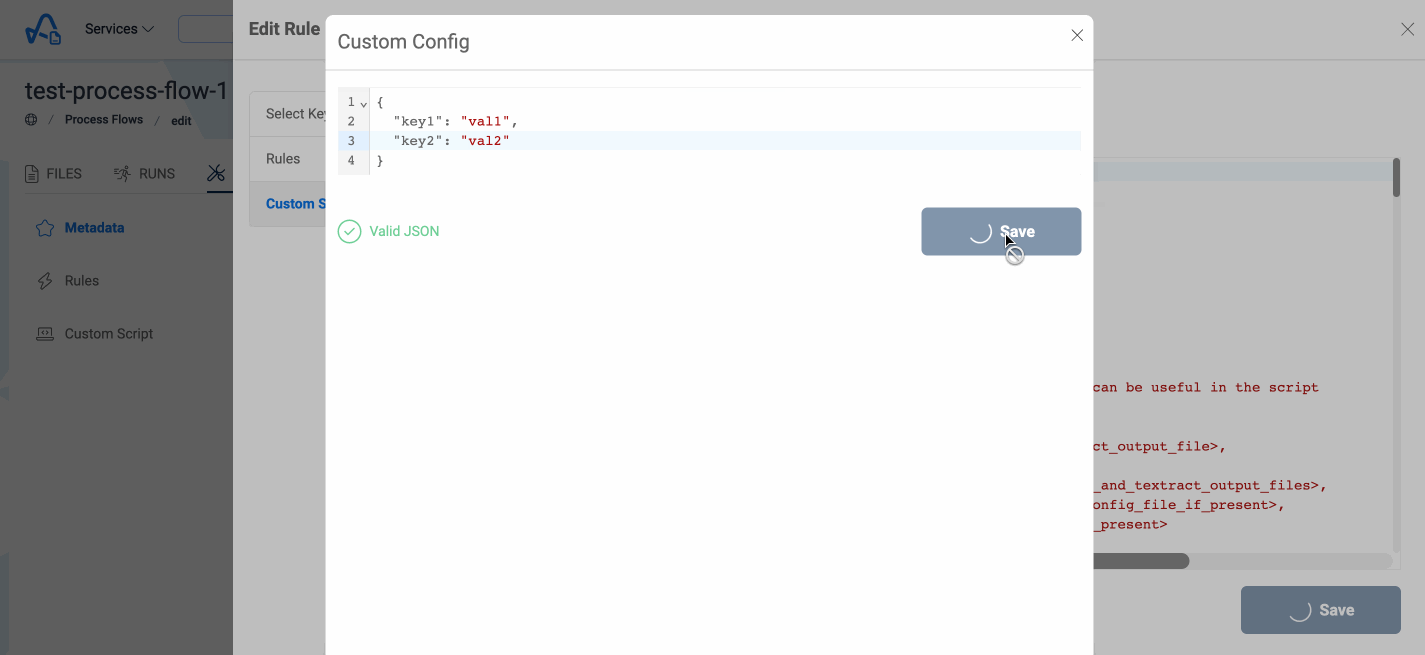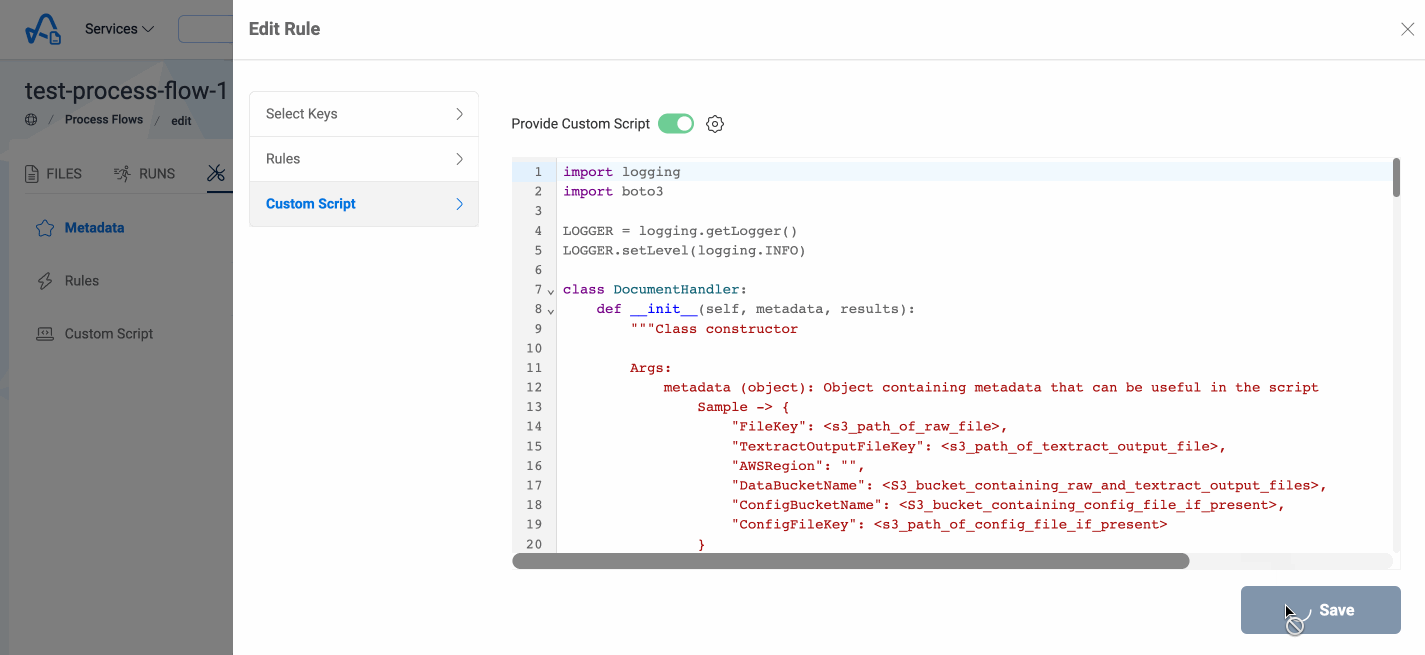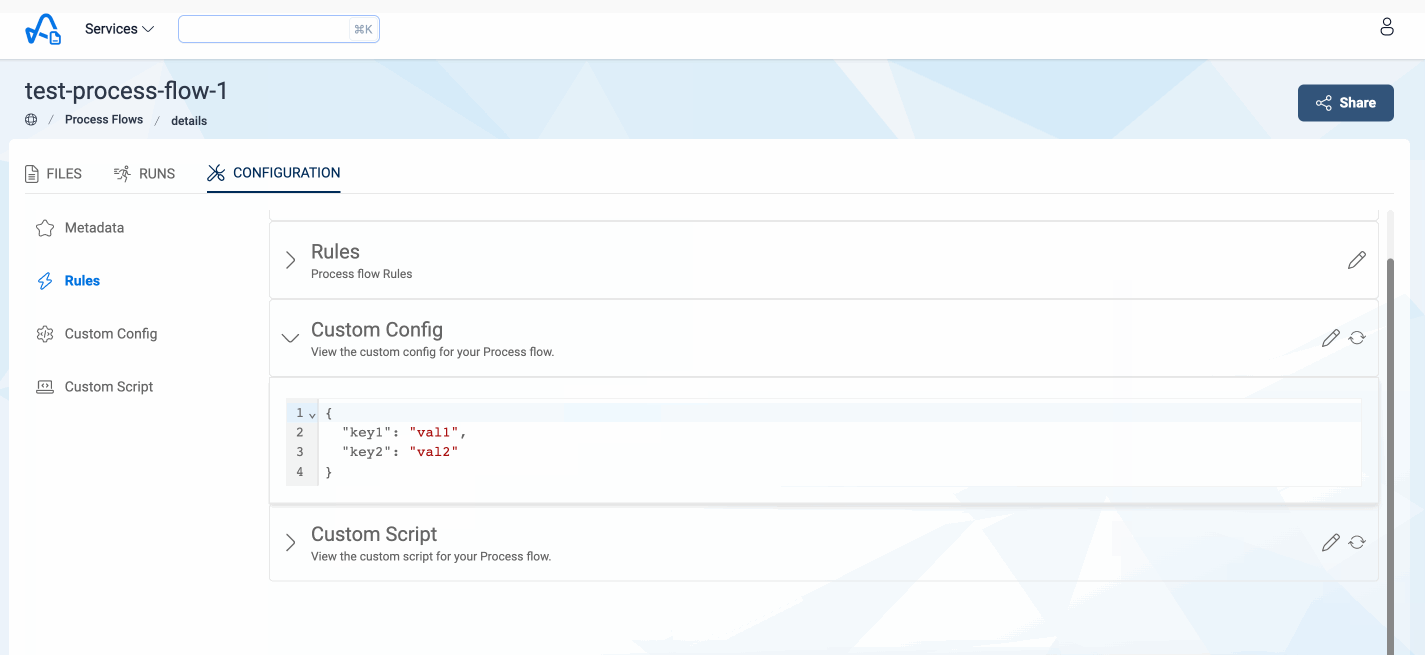
Users also have the option to specify a particular JSON configuration that they wish to access within their custom script. This configuration can be defined while updating the process flow, and if provided, the file will be uploaded to S3 for reference in the script.
This file can be accessed in the custom script using the ConfigBucketName and the ConfigFileKey properties
present in the metadata object.
Below image shows how to add a configuration for custom script
Sample snippet for accessing the custom configuration in the custom script
def execute_custom_script(self):
"""Write the custom code for the given script
"""
config_bucket_name = self.metadata['ConfigBucketName']
config_file_key = self.metadata['ConfigFileKey']
# Get the S3 object
response = s3_client.get_object(Bucket=config_bucket_name, Key=config_file_key)
# Read the content of the object
object_content = response['Body'].read()
# Parse the JSON content
config_json_data = json.loads(object_content.decode('utf-8'))
# Now you can work with the JSON data as required
print(config_json_data)
How to install additional packages for use within the custom script?
If a user needs any additional python packages to be used within the custom script, the following steps need to be taken:
- Whitelist following proxy domains from Amorphic under
Management> App Management > Whitelisted Domains: pypi.org , files.pythonhosted.org - Then the following sample snippet can be used in the custom script for installing any python packages:
@staticmethod
def install_and_import_package(package_name):
'''Installs and imports a python package'''
# Install the package using pip
subprocess.call(f'pip install {package_name} -t /tmp/ --no-cache-dir'.split(), stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
sys.path.insert(1, '/tmp/')
# Import the package to make it available
try:
__import__(package_name)
print(f"Successfully installed and imported {package_name}!")
except ImportError:
print(f"Failed to import {package_name}.")
def execute_custom_script(self):
'''Write the custom code for the given script
'''
self.install_and_import_package('package_name')
Custom script execution has a hard limit of 15 minutes. Please keep this in mind when trying to install additional packages.