
Athena Datasets
Athena Datasets is a feature of Amazon Athena which allows users to store structured data files in Amazon S3 and run SQL queries on the data. Data validation can be enabled to check for corrupt data, and the query engine can be used to run queries on the dataset.
How does it work?
With Athena datasets as the target location, Amorphic provides users the ability to store CSV/TSV/XSLX/JSON files in S3 without the overhead of maintaining a data warehousing solution, for cost effectiveness.
Data Validation is enabled by default for S3Athena target location, but can be enabled/disabled at any time. Each file is partially sampled/read and every column is validated against the schema uploaded to the dataset while registering. This helps users quickly detect and perform data correction on corrupt or invalid data files, though it takes a few extra seconds per file and there is an additional charge per file.
As of now, users can register structured data such as CSV, TSV, XLSX, JSON and Parquet files, and validate data types such as Strings/Varchar, Integers, Double, Boolean, Date and Timestamp. To accommodate complex data structures, we recommend enclosing them in quote chars and registering the column schema as String/Varchar. Once loaded, users can perform ETL atop of the data and cast them appropriately.
The CSV Parser/SerDe recommended by AWS Athena has the following limitations:
- It does not support embedded line breaks in CSV files, nor does it support empty fields in columns defined as a numeric data type.
As per the AWS Documentation, one workaround to achieve this is to import them as string columns and create views on top of it by casting them to the required data types.
For Datasets with JSON file type:
- AWS Limitations
- It uses the OpenX JSON SerDe with the following limitations:
- It expect JSON data to be on a single line (not formatted), with records separated by a new line character.
- Comma character is not allowed at the end of each line.
- The full data in the file should not be enclosed in square brackets.
- Views are not supported on top of S3Athena JSON datasets.
- It uses the OpenX JSON SerDe with the following limitations:
- Amorphic feature limitations (Not Applicable)
- Malware Detection
- Data Profiling
Below is an example of an invalid JSON file:
[
{
"EmailId": "test-cwdl@cloudwick.com",
"IsAdmin": "no",
"UserId": "testuser"
},
{
"EmailId": "test1-cwdl@cloudwick.com",
"IsAdmin": "no",
"UserId": "testuser1"
}
]
Below is an example of a valid JSON file:
{ "EmailId": "test-cwdl1@cloudwick.com", "IsAdmin": "no", "UserId": "testuser1" }
{ "EmailId": "test-cwdl2@cloudwick.com", "IsAdmin": "no", "UserId": "testuser2" }
{ "EmailId": "test-cwdl3@cloudwick.com", "IsAdmin": "yes", "UserId": "testuser3" }
{ "EmailId": "test-cwdl4@cloudwick.com", "IsAdmin": "no", "UserId": "testuser4" }
{ "EmailId": "test-cwdl5@cloudwick.com", "IsAdmin": "yes", "UserId": "testuser5" }
How to Create Athena Datasets?
You can create new Datasets with target location for the datasets as Athena.
Currently, only structured data is supported in the CSV, JSON or XLSX file formats.

Load Athena Datasets
Athena Datasets provides users with a cost-effective solution to store their structured data. All loaded datasets are immediately available for analysis using the Run Query tab in the Amorphic console. The advantage of using Athena datasets is that it provides auto data validation on each file uploaded, without the need for any additional ETL.
Query Datasets
Once we have loaded data into Athena datasets, it is ready for the user to query and analyze directly from the Run Query tab. The following animation demonstrates how a user can run a sample query on Athena datasets.
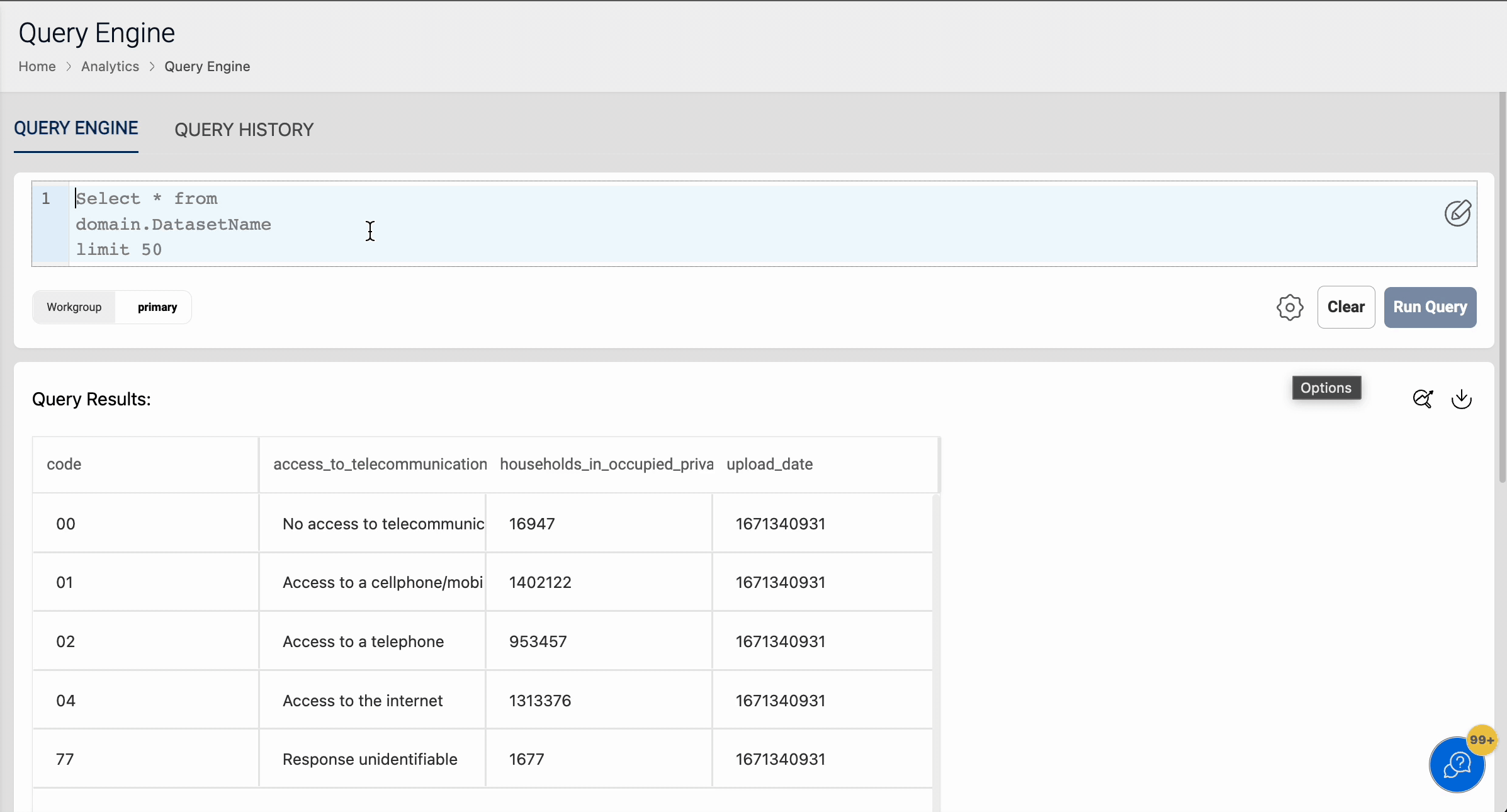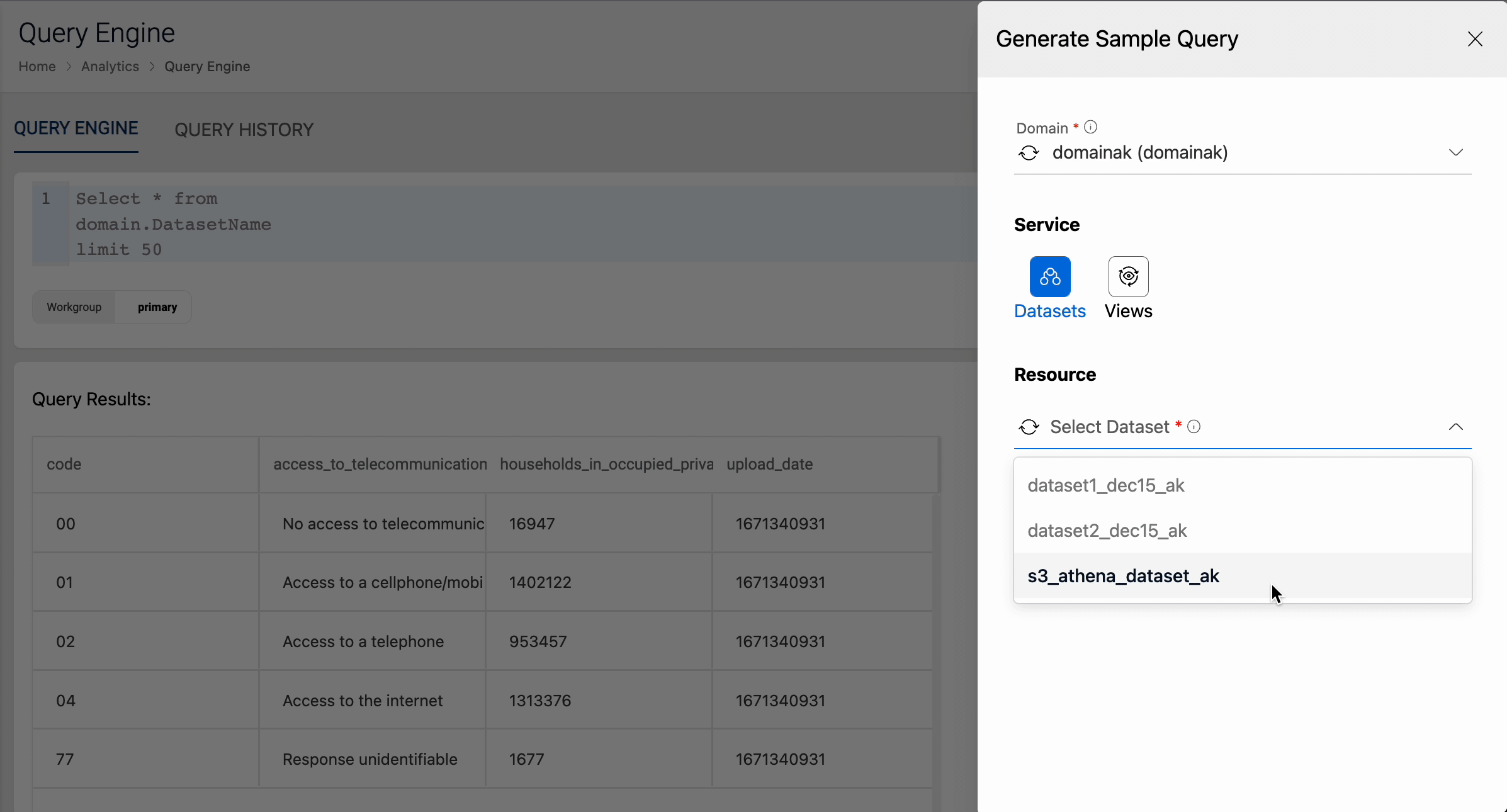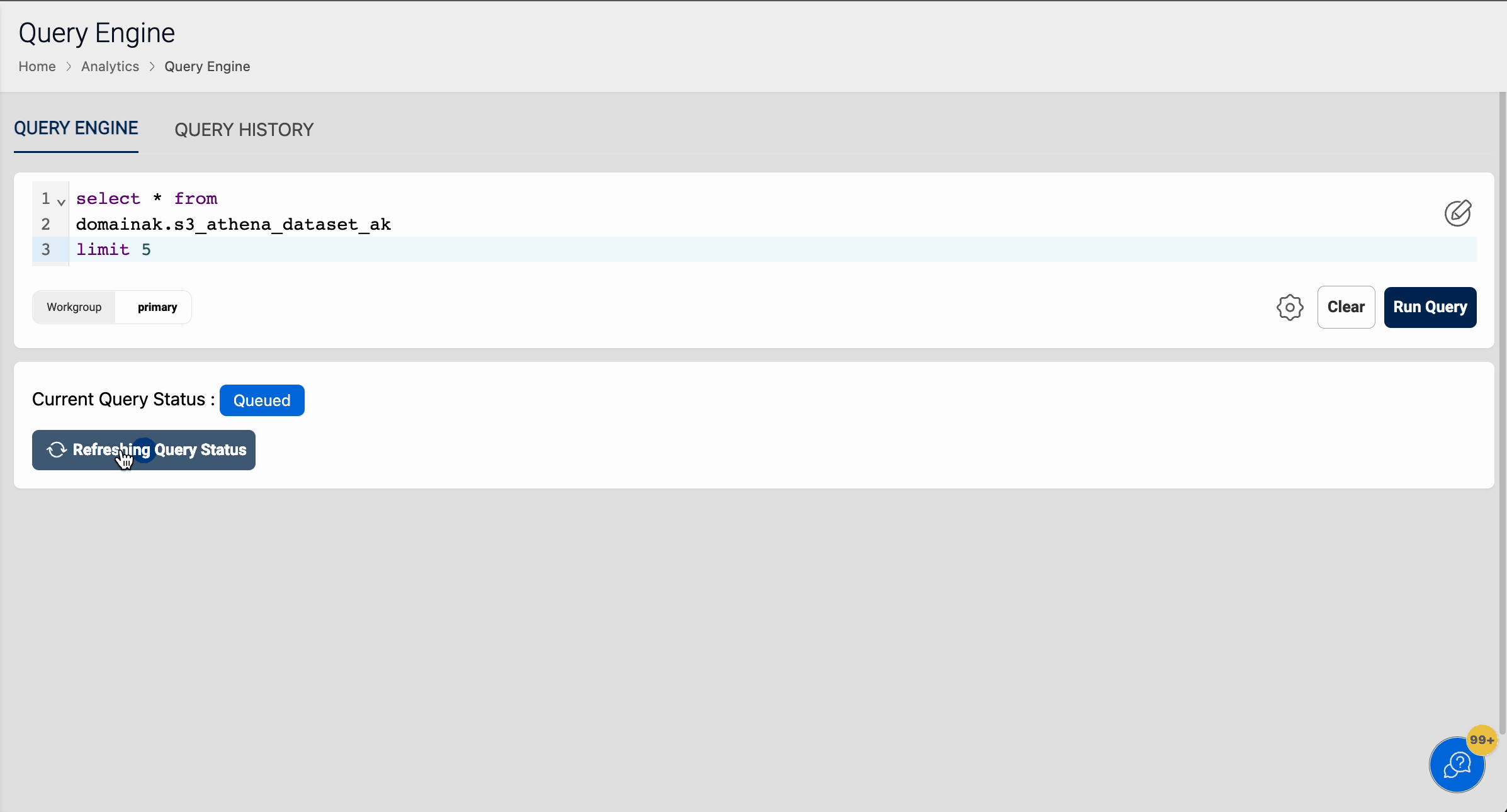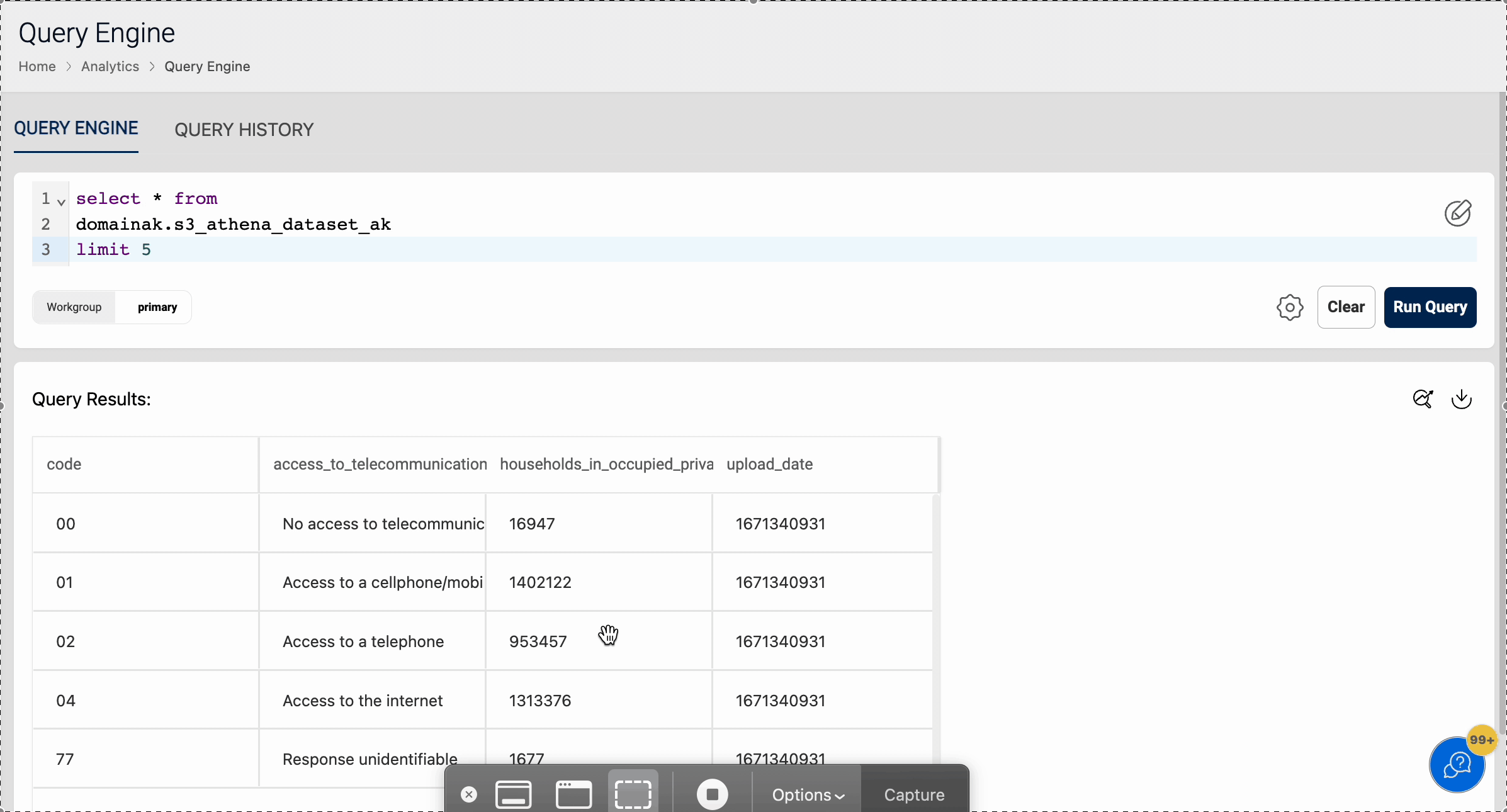
Athena Datasets use case
An example of how to use Athena Datasets is for an e-commerce company that wants to look at customer purchase data.
The company keeps customer purchase details in CSV files in Amazon S3. They use Athena Datasets to register the data as a dataset and use SQL queries to find out useful information, such as the most popular products, the average order value, and the places customers are from. Before looking at the data, they use the data validation feature to check for any bad or wrong data in the files. This helps them quickly find and fix any problems in the data. Once the data is checked, they can use the query engine to analyze the data and make decisions based on the results.
Athena Datasets enables companies to store, validate, and analyze structured data in Amazon S3, aiding them to make better decisions based on data insights.