
Files
Files helps you with the management of files that contain actual data for datasets. It allows you to view the files associated with the datasets and their respective statuses. The data from the uploaded files will be copied into the tables present at the target location.
You can perform several operations on files, including:
| Properties | Details |
|---|---|
| Upload | You can upload files to datasets based on the selected Update Method. If you want the data in the files to be validated, you can set the Skip LZ (Validation) to 'No'. |
| Truncate | If the target location is either S3 or S3-Athena, you can permanently delete all the files inside the dataset. |
| Delete | If you delete a file from a dataset, it will remain under Deleted files for four weeks before being deleted permanently. |
| Restore | You can restore deleted files if the target location is either S3 or S3-Athena. |
| Restore files from Archive | You can restore files stored in archival storage classes such as Glacier and Deep Archive, either temporarily or permanently. |
Upload
You can add files based on the Update Method selected while creating a dataset. For example, datasets with target locations Redshift have three available update methods. For datasets with target locations S3 and S3-Athena, there are two update methods.
- Reload: When Reload is chosen as the update method, new files will replace the old files every time they are added. After files are uploaded, users can choose to process them or discard them.
- Append / Latest Record: When Append or LatestRecord is selected as update method, the newly added files are appended to the existing files present in the dataset.
You can also custom partition the data. To learn more, see Dataset Custom Partitioning.
If the Skip LZ (Validation) Process is enabled (True/Yes) for a specific dataset, the file upload process will skip the whole validation (LZ) process and the file will be uploaded to the DLZ bucket. This avoids unnecessary S3 copies and validations, as well as auto-disabling the MalwareDetection and IsDataValidationEnabled (for S3Athena and Lake formation datasets) functionality.
This is applicable only to append and update type of datasets.
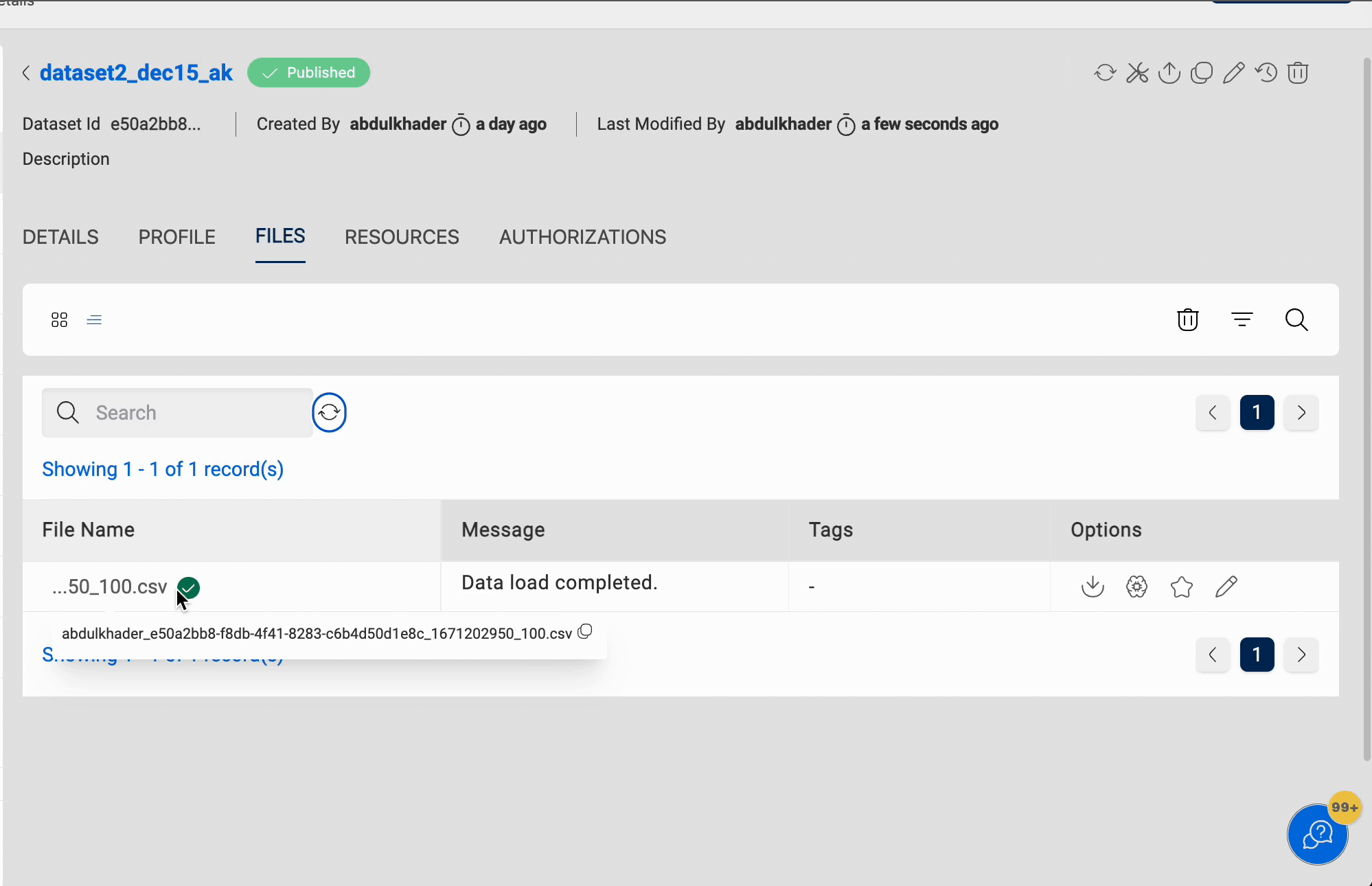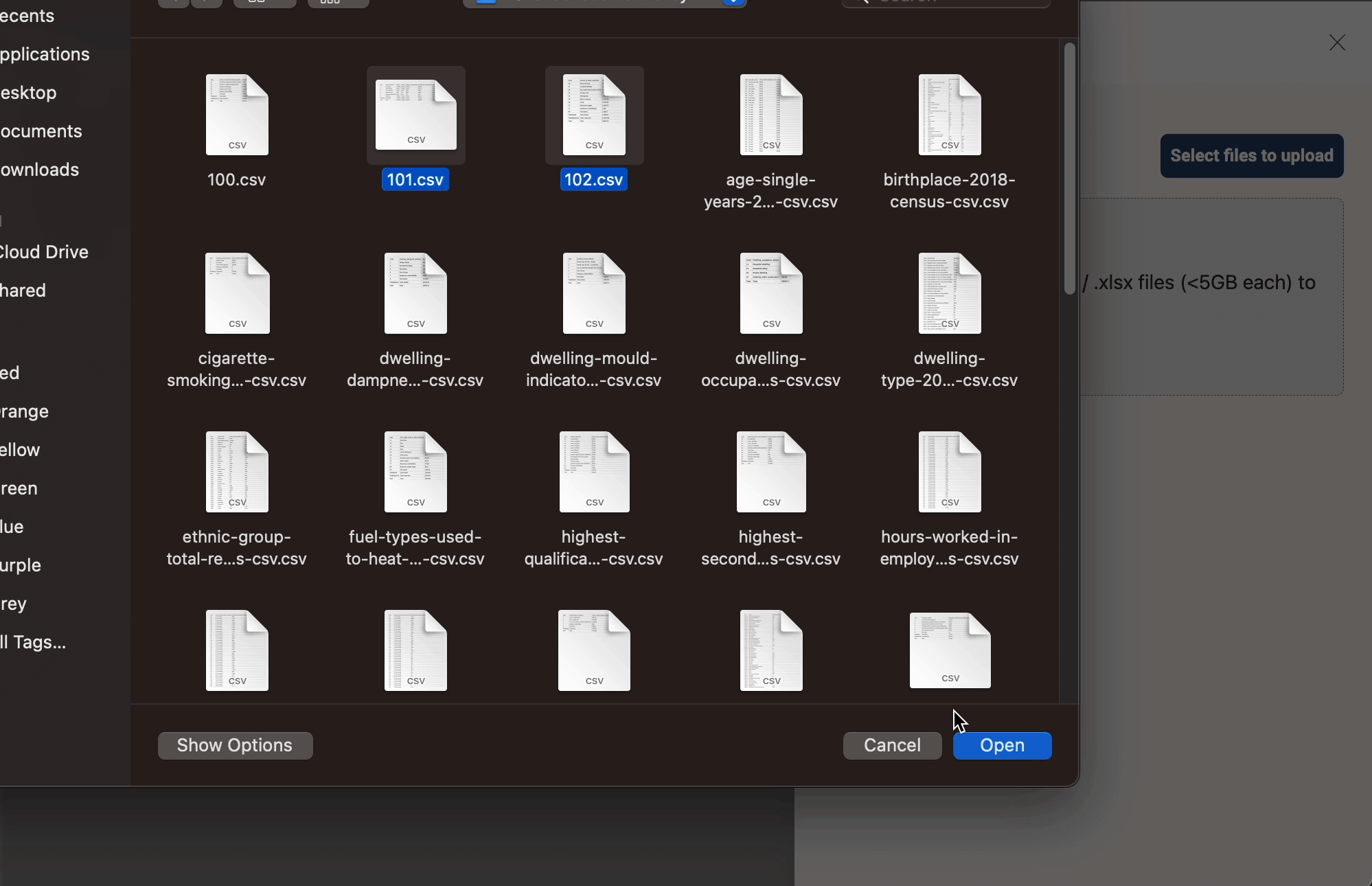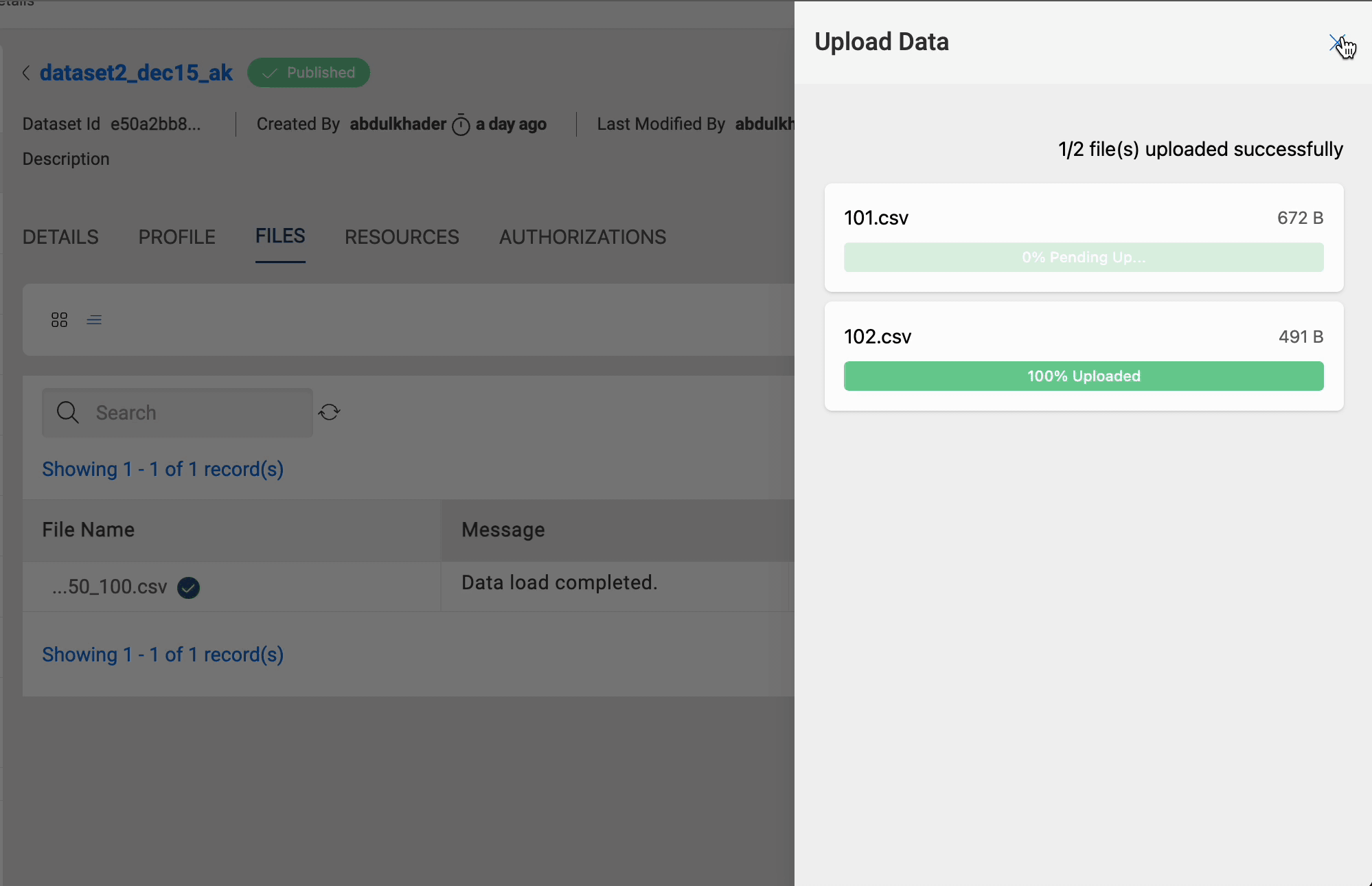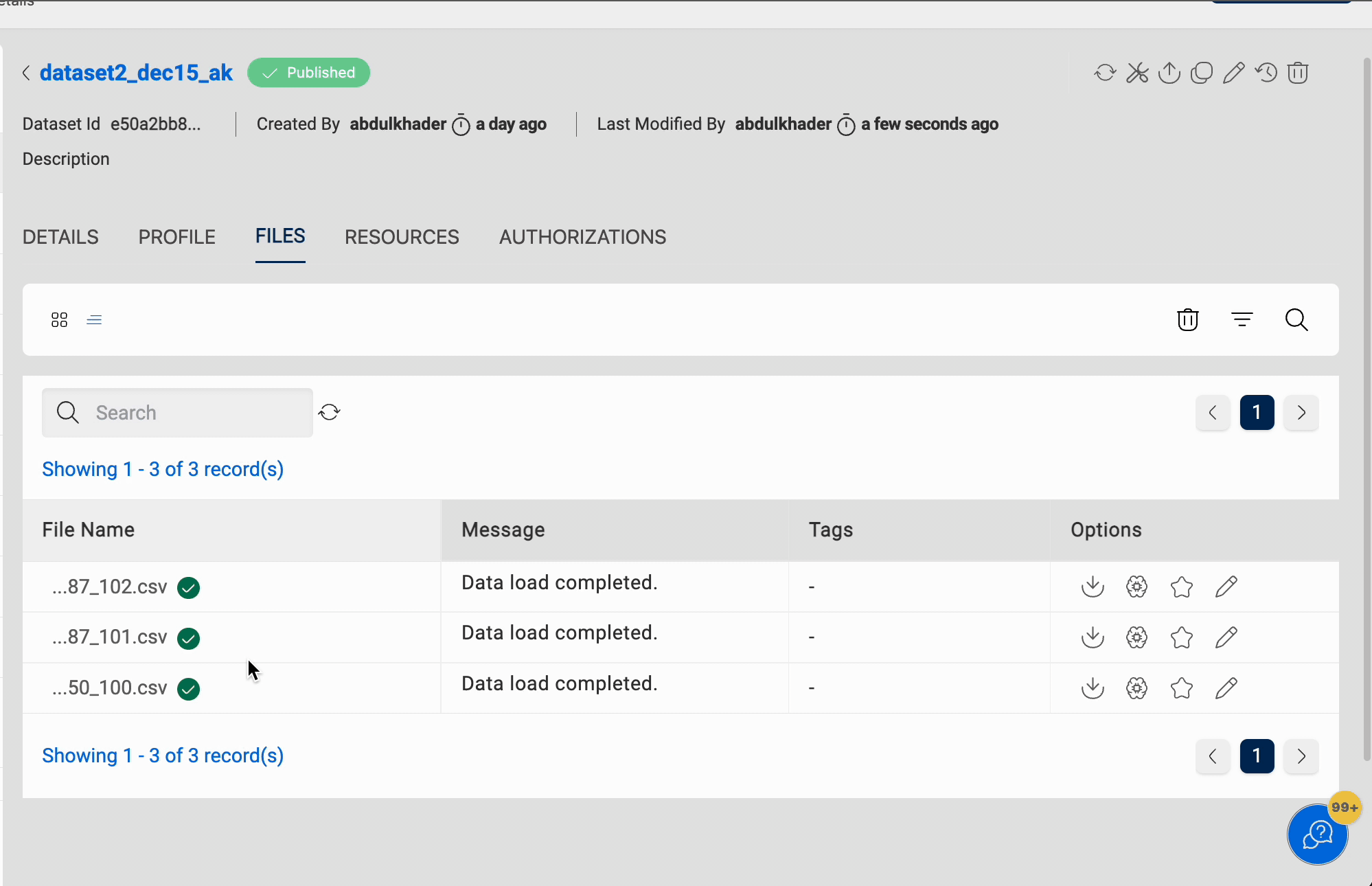
File Details
You can click on the 'View File Details' button next to the file name to view more details about it. The panel that pops up displays the file details, which is a preview of the file and AI/ML transformation details. Currently file preview is supported for the following file types - bmp, gif, ico, jpeg, jpg, png, apng, avif, webp, svg, csv, tsv, m4a, mp3, oga, ogg, wav, mp4, webm, ogv, mov, txt, json, docx, pdf
Truncate
All files in the dataset are deleted when the Truncate option is selected. This functionality is only available for datasets in S3 and S3-Athena locations.
Below images shows the functionality of truncate dataset:
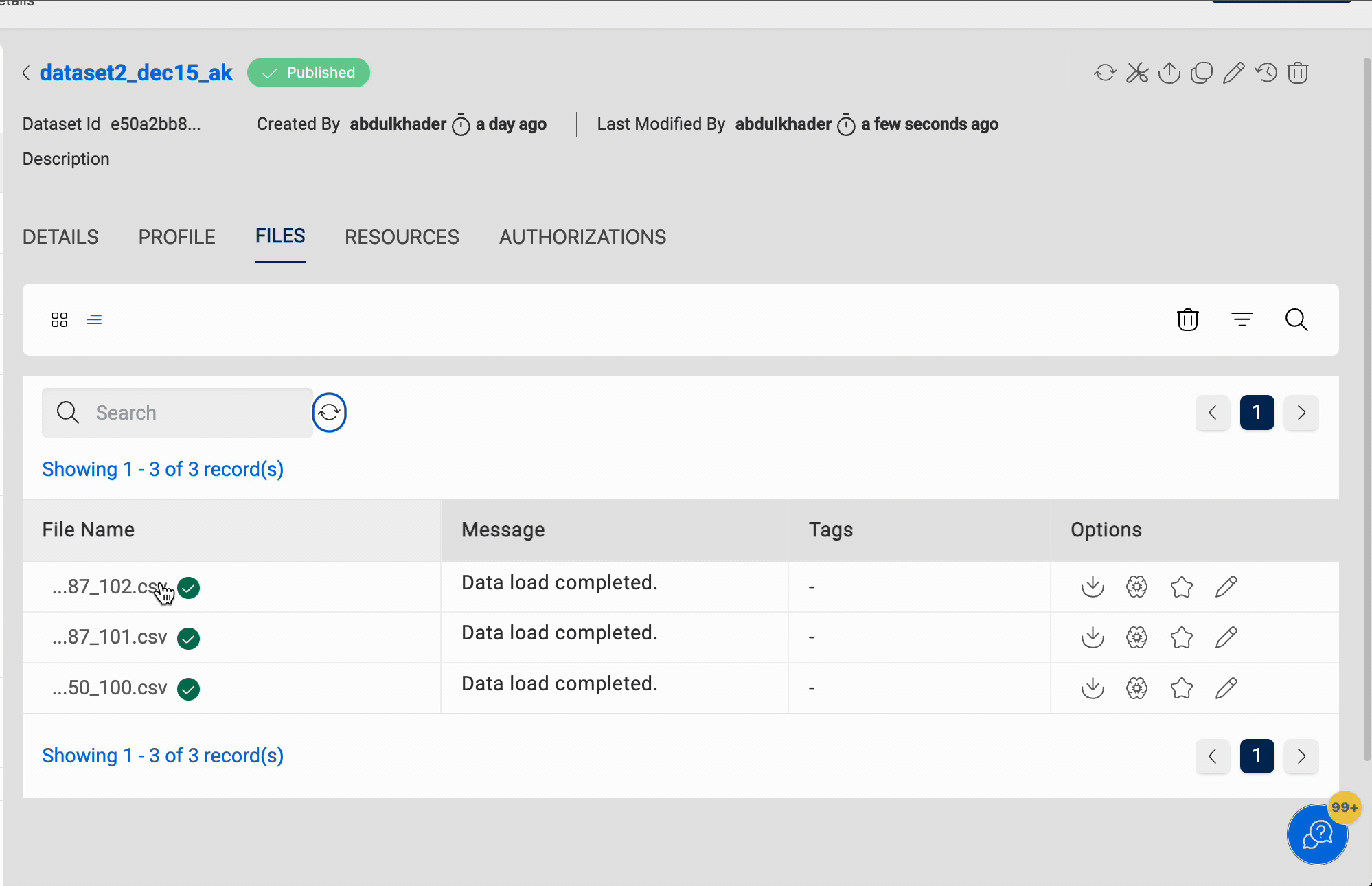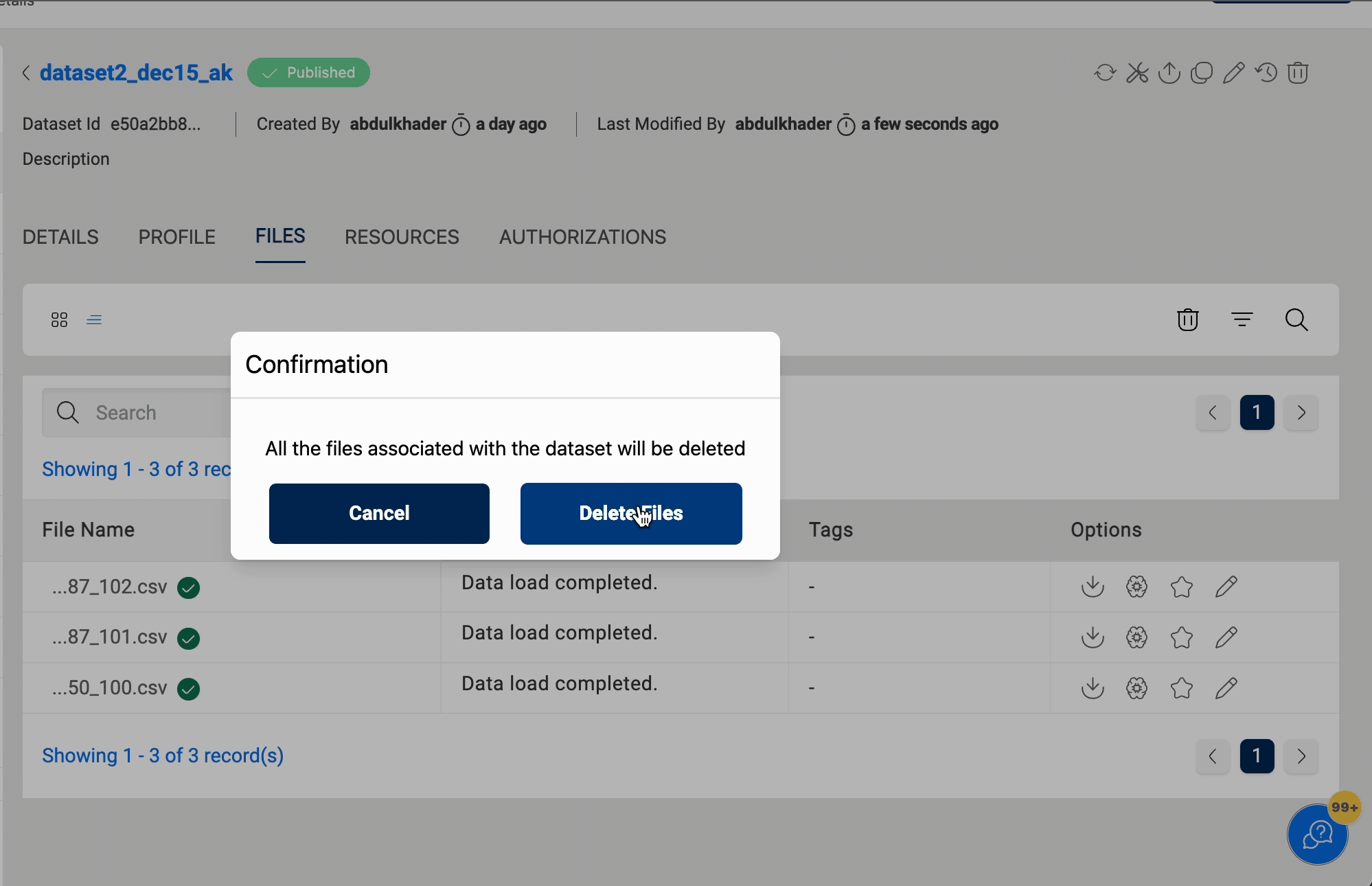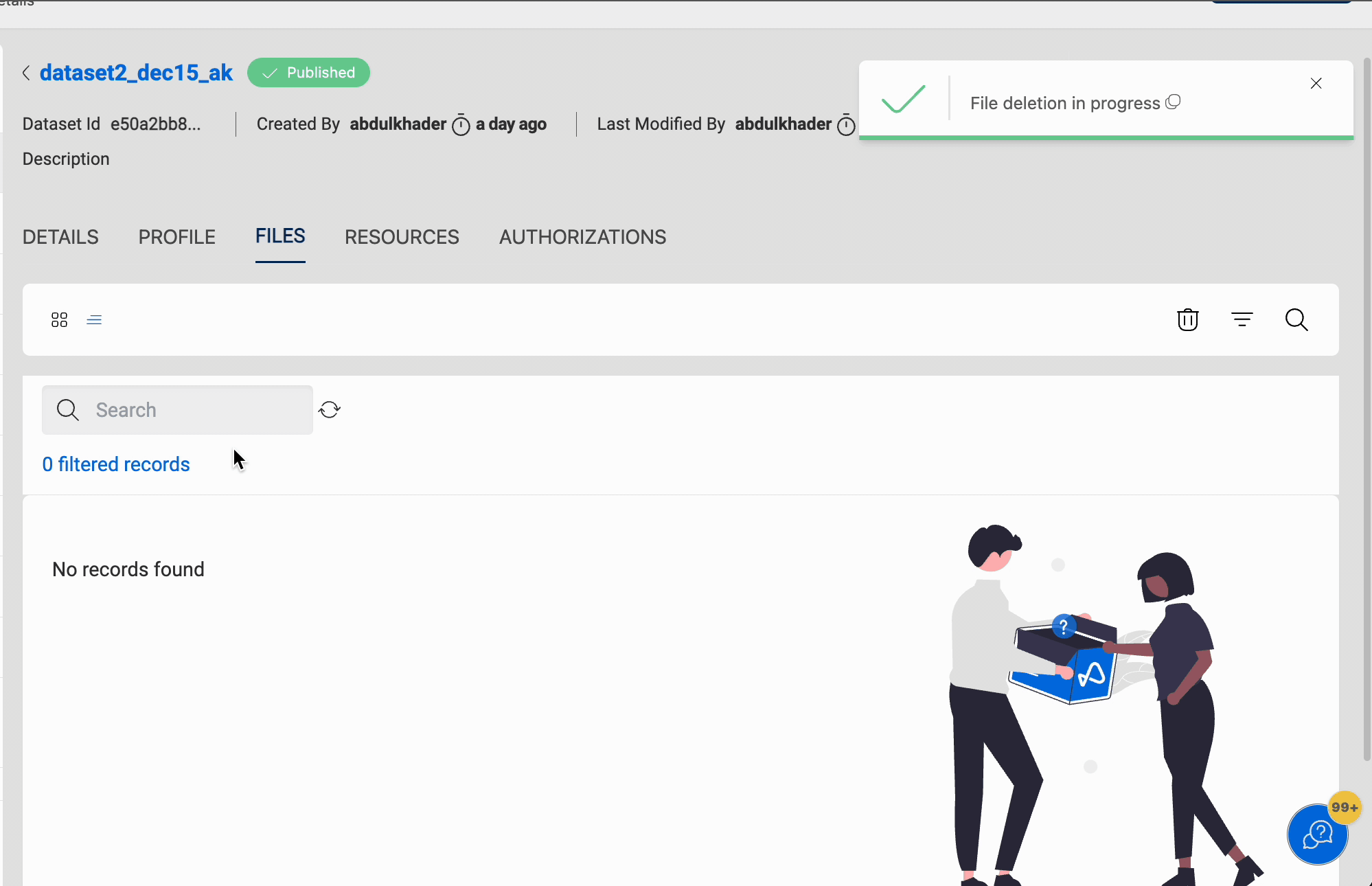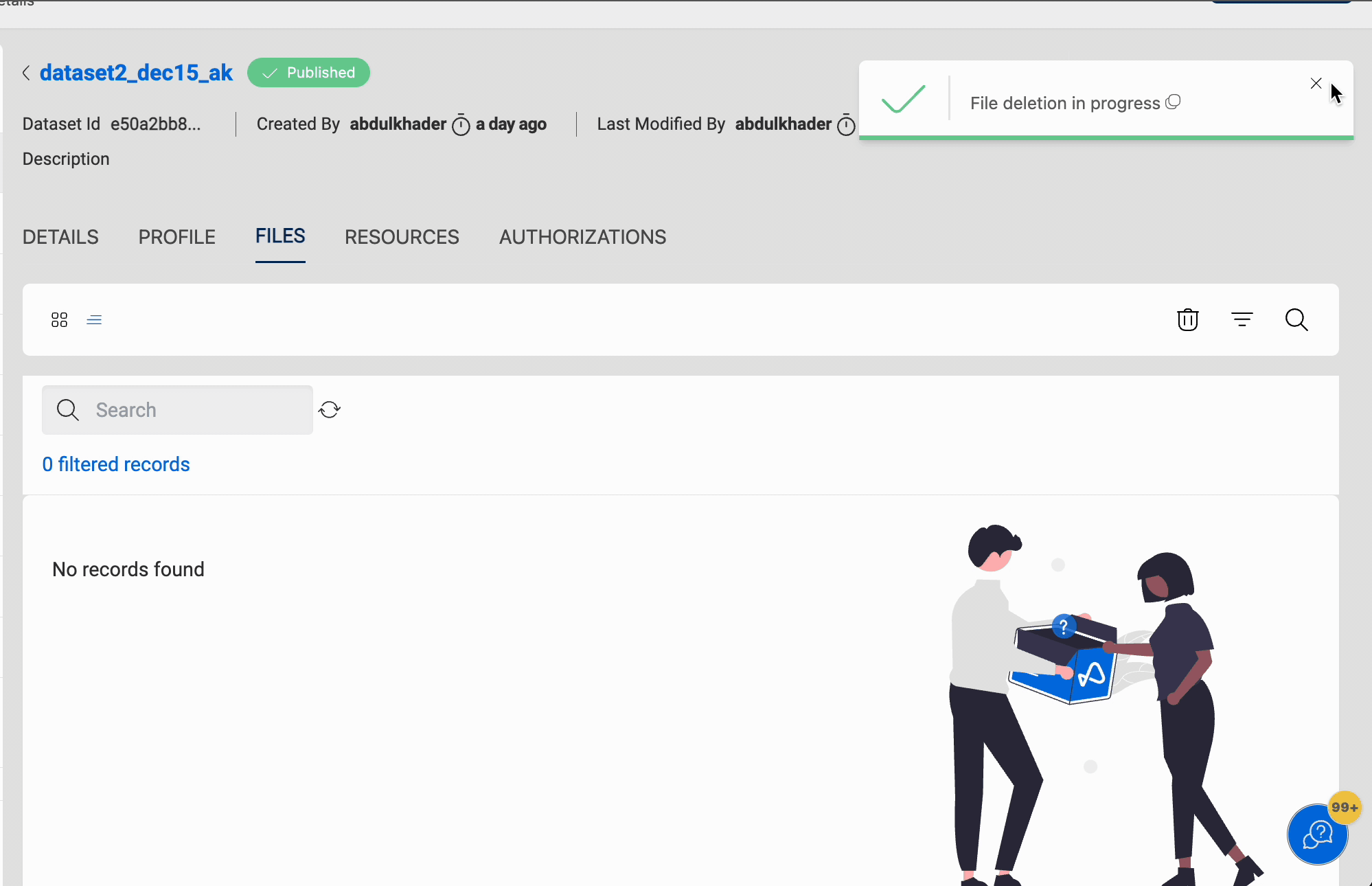
Delete
You can delete files from a dataset, which can be restored using the Restore function. This only applies to datasets in S3 and S3-Athena.
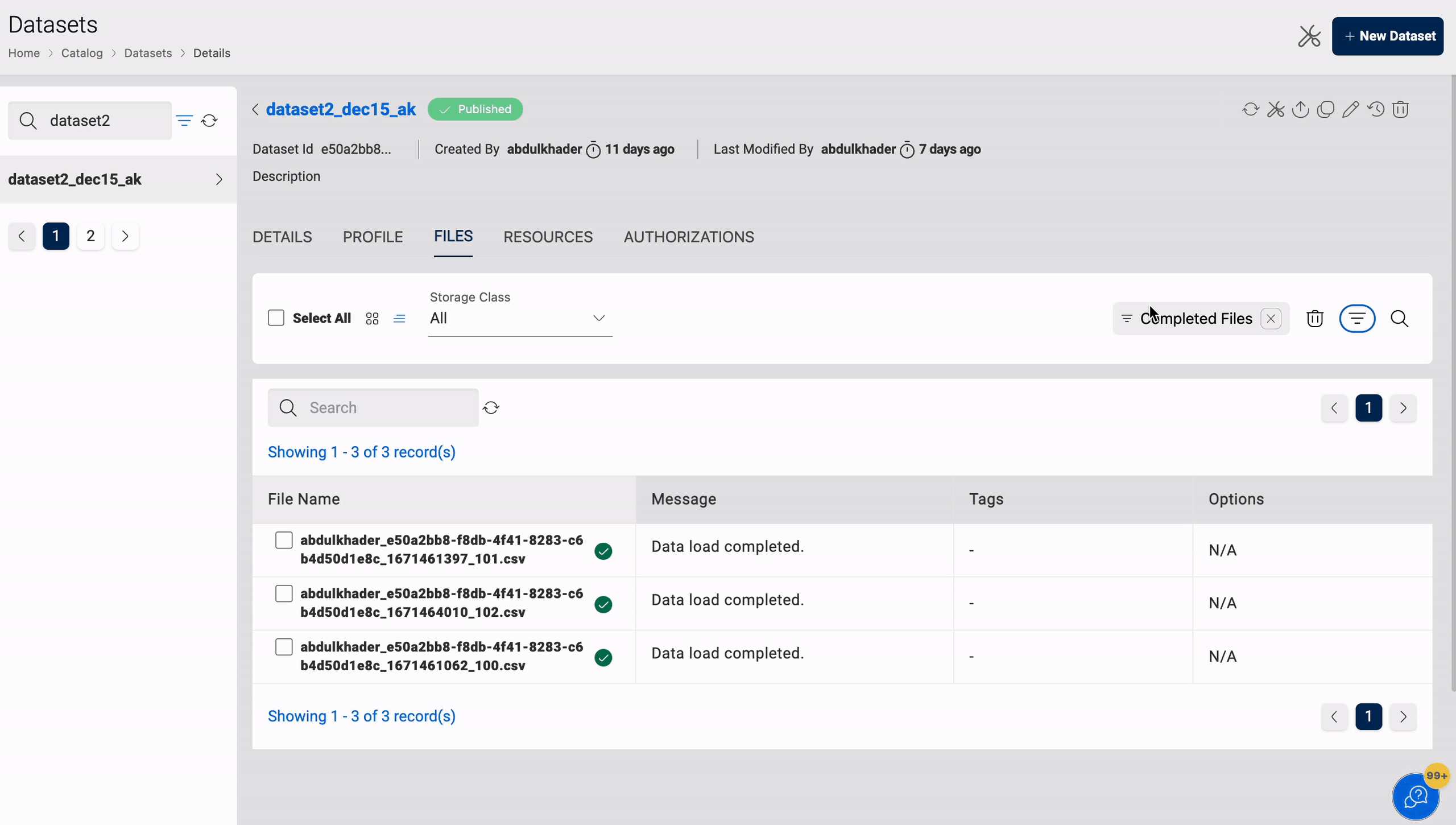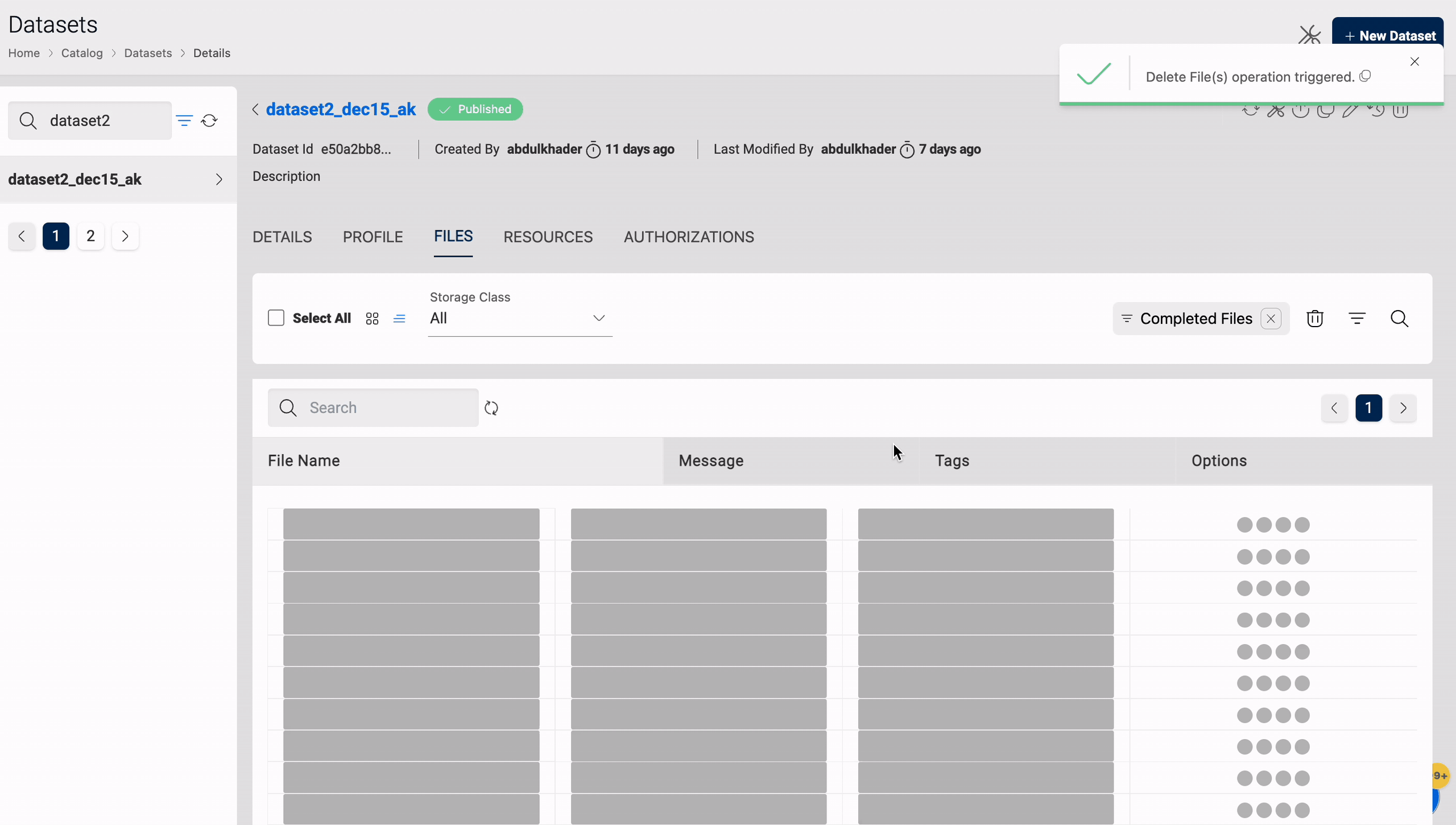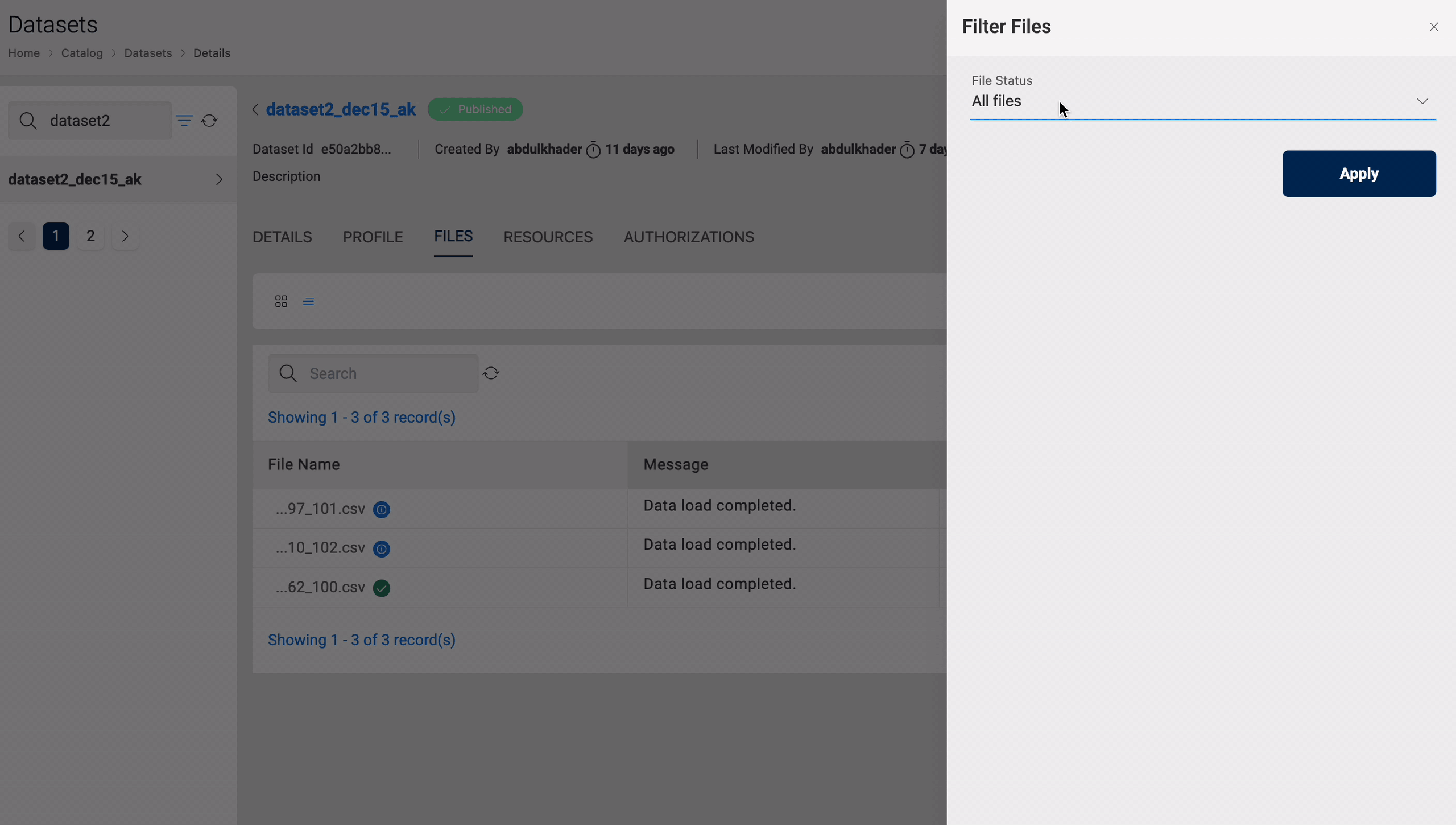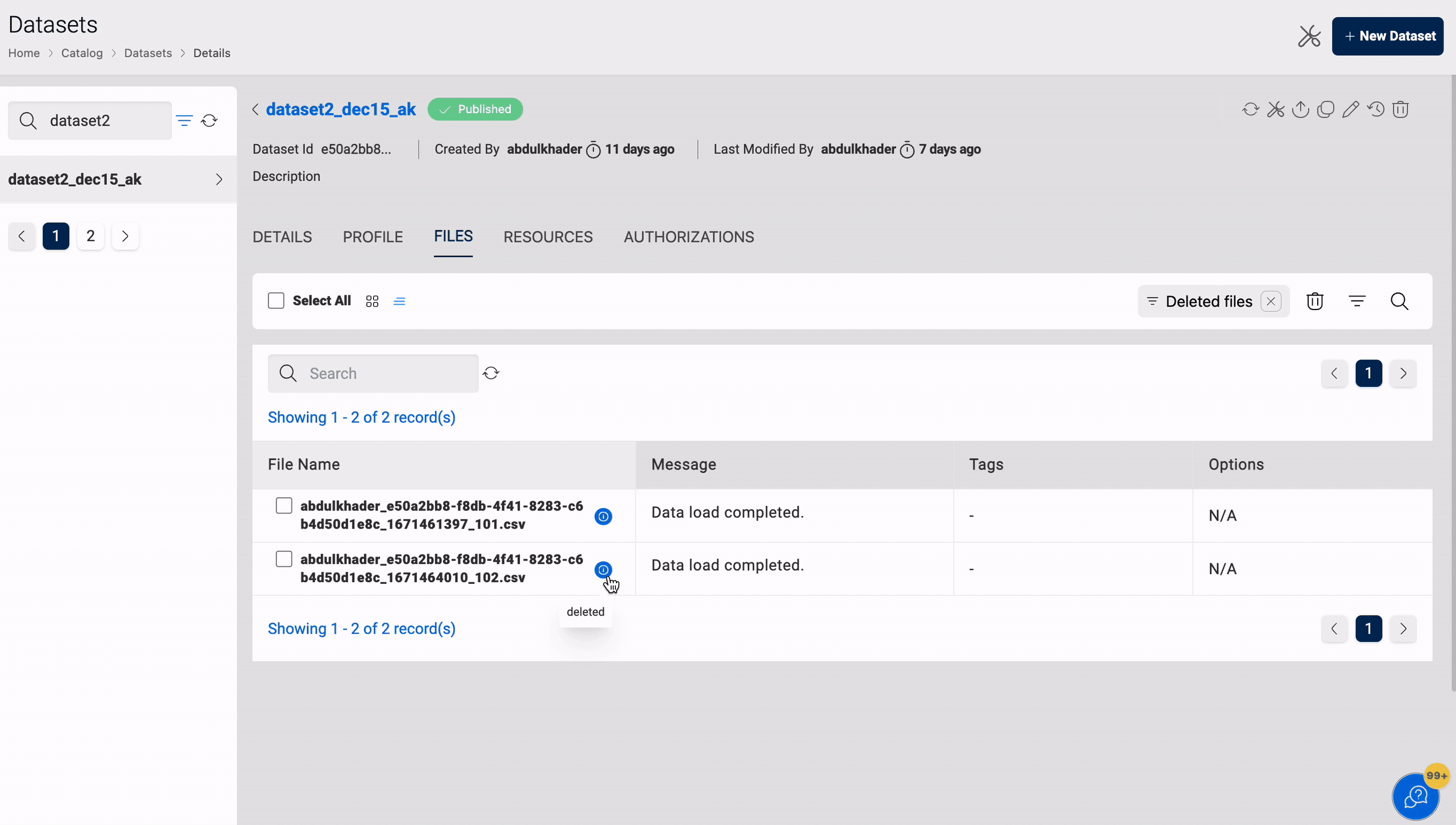
All files marked as deleted will be permanently removed after four weeks, with eventual consistency. This action will delete the file data and its metadata, and this action cannot be reversed. You can view the time remaining for the file in the Deleted Files section to take any necessary action if required.
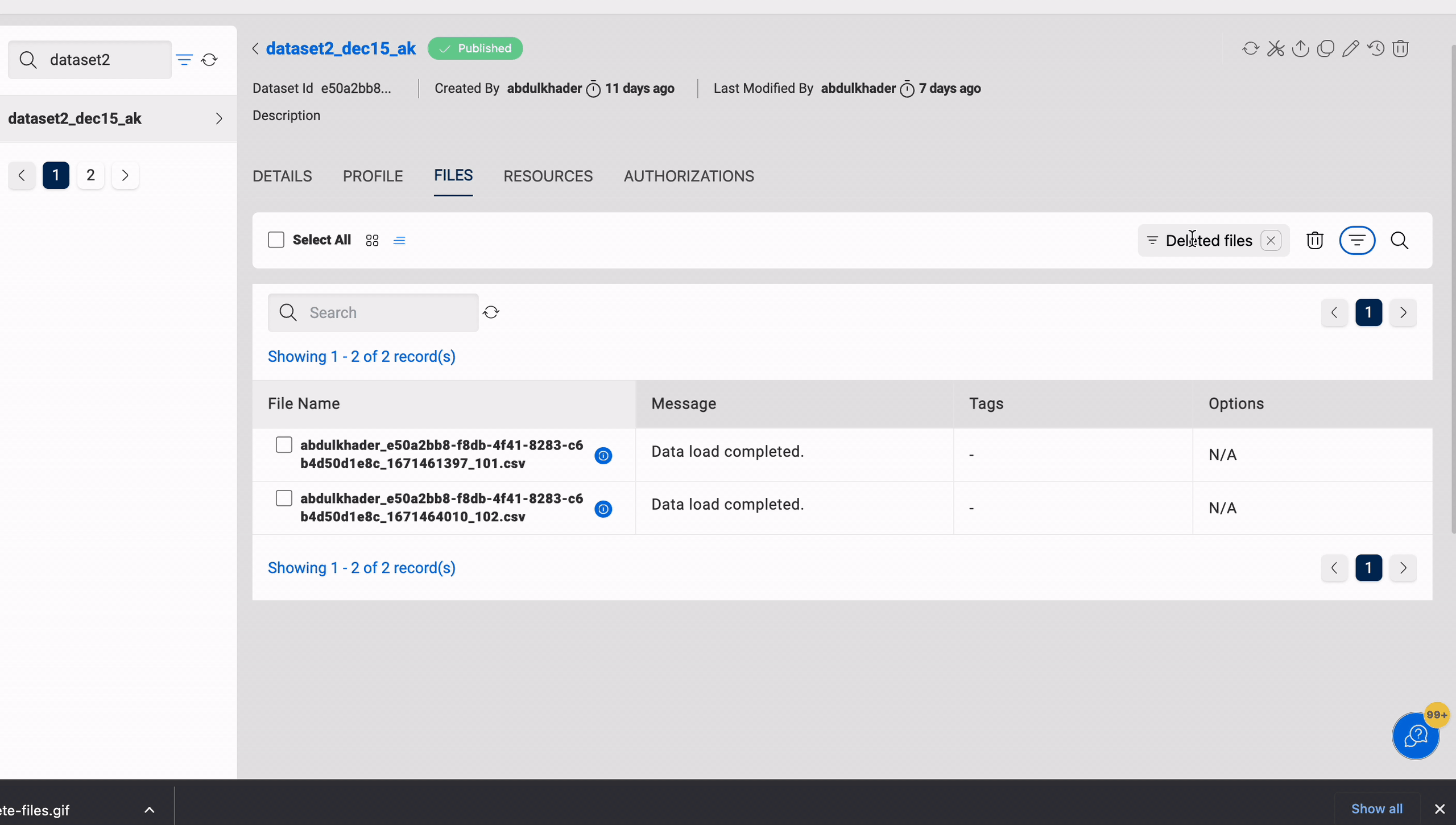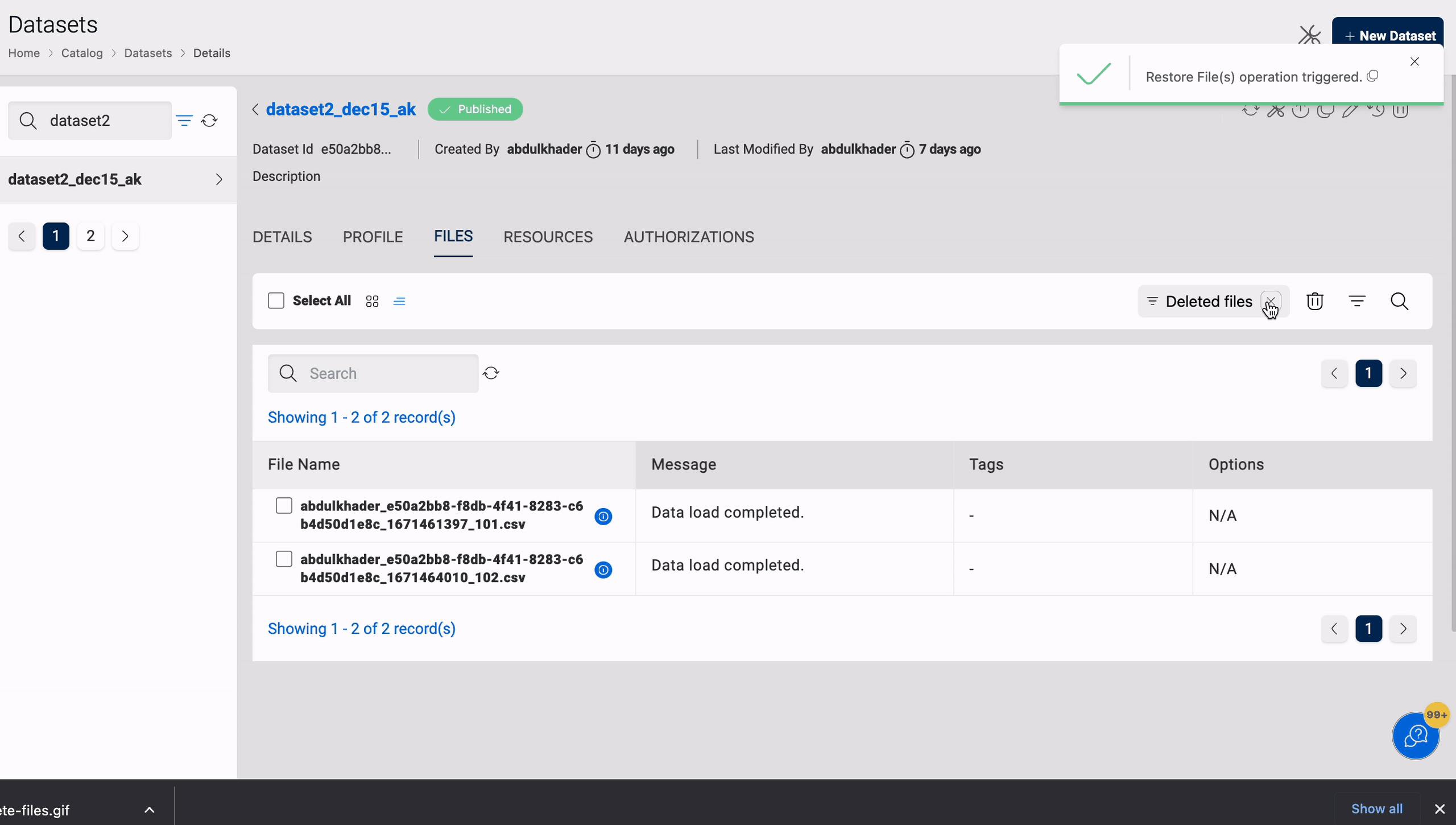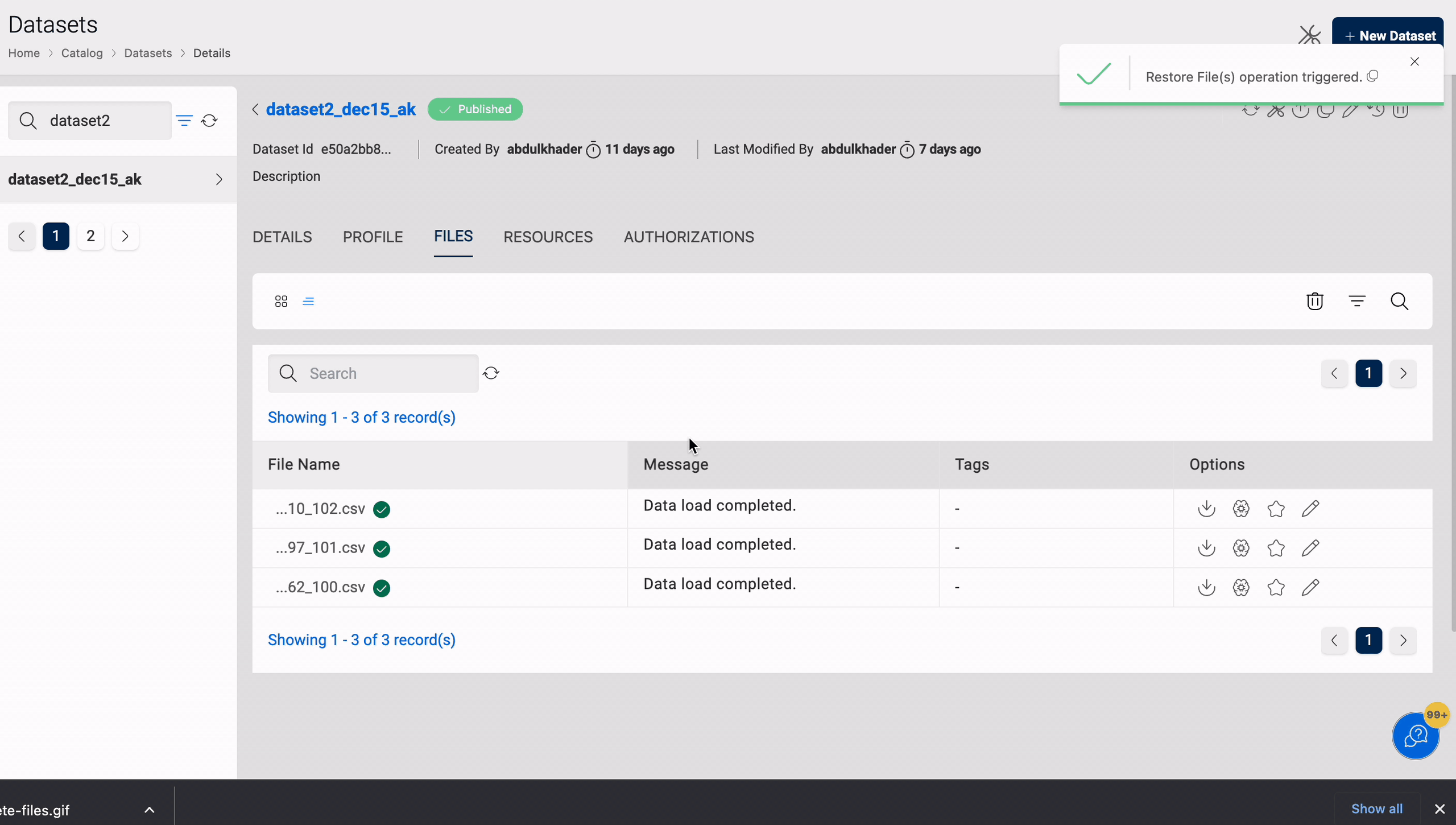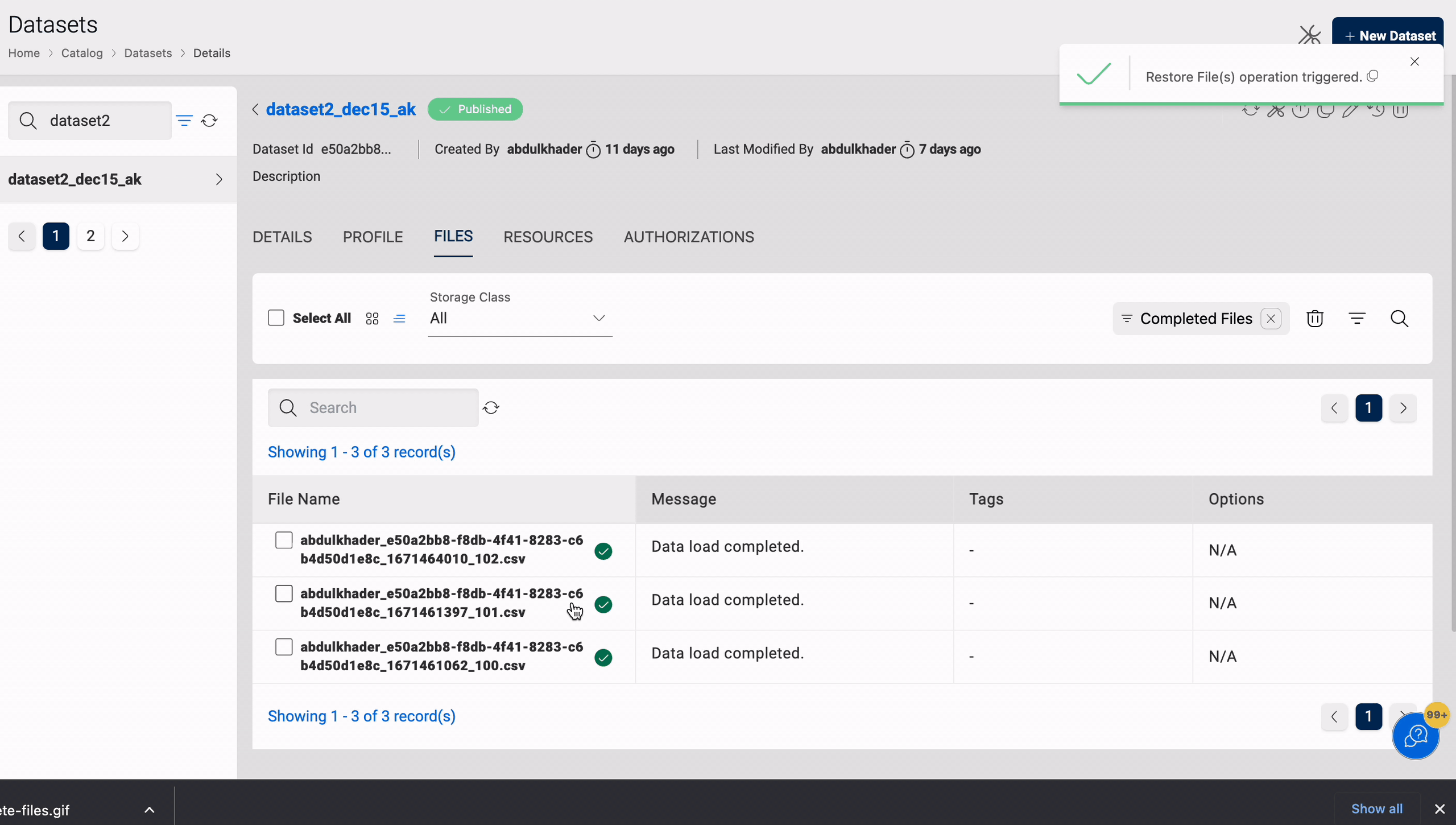
Restore
Restore enables you to restore files that have been deleted from a dataset. It is applicable to datasets in the target locations S3 and S3-Athena.
Restore files from Archive
You can restore the files which are stored in the archival storage classes like Glacier and Deep Archive. Applicable to dataset of target location S3, S3-Athena and Lakeformation.
Below attributes are required to restore the archived files:
| Properties | Details |
|---|---|
| File Copy Type | The type of copy to be restored. |
| Temporary | A temporary copy will be available for a specified number of days (restoration expiration). |
| Permanent | The restored file will be copied permanently to Standard storage class and will always be available. |
| Restore Expiration Days | The number of days for which the temporary copy of the file should be available for use/download. This is only applicable when the File copy type is temporary. |
| Retrieval Option | Options to retrieve when restoring an archived object. The time and cost to restore an archived object depends on the option. For more details, please refer to the Object retrieval options.
|
Temporarily restored objects cannot be queried. To learn more, refer AWS Athena limitations.
Also, a user cannot query or create views on transition related datasets.
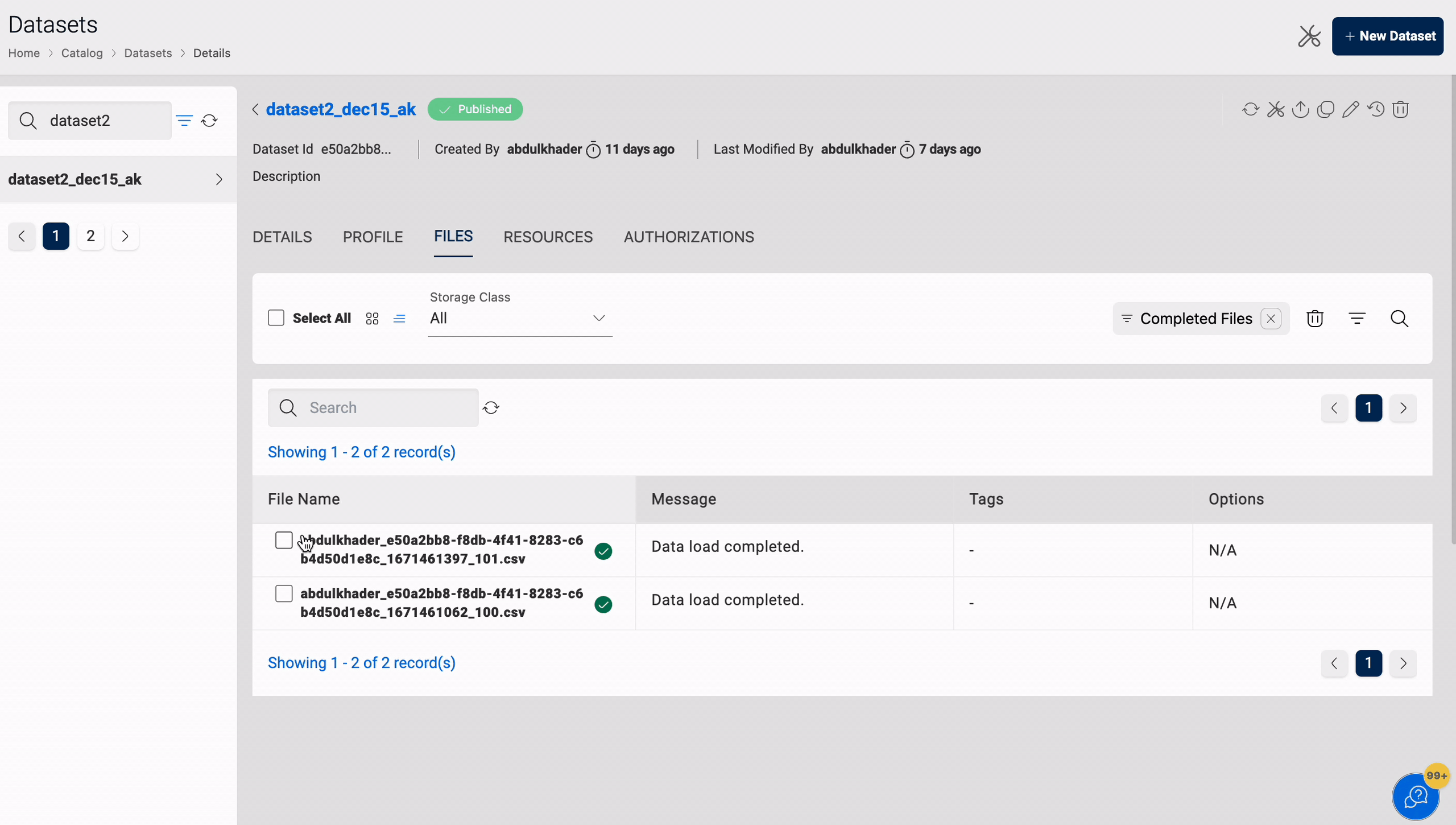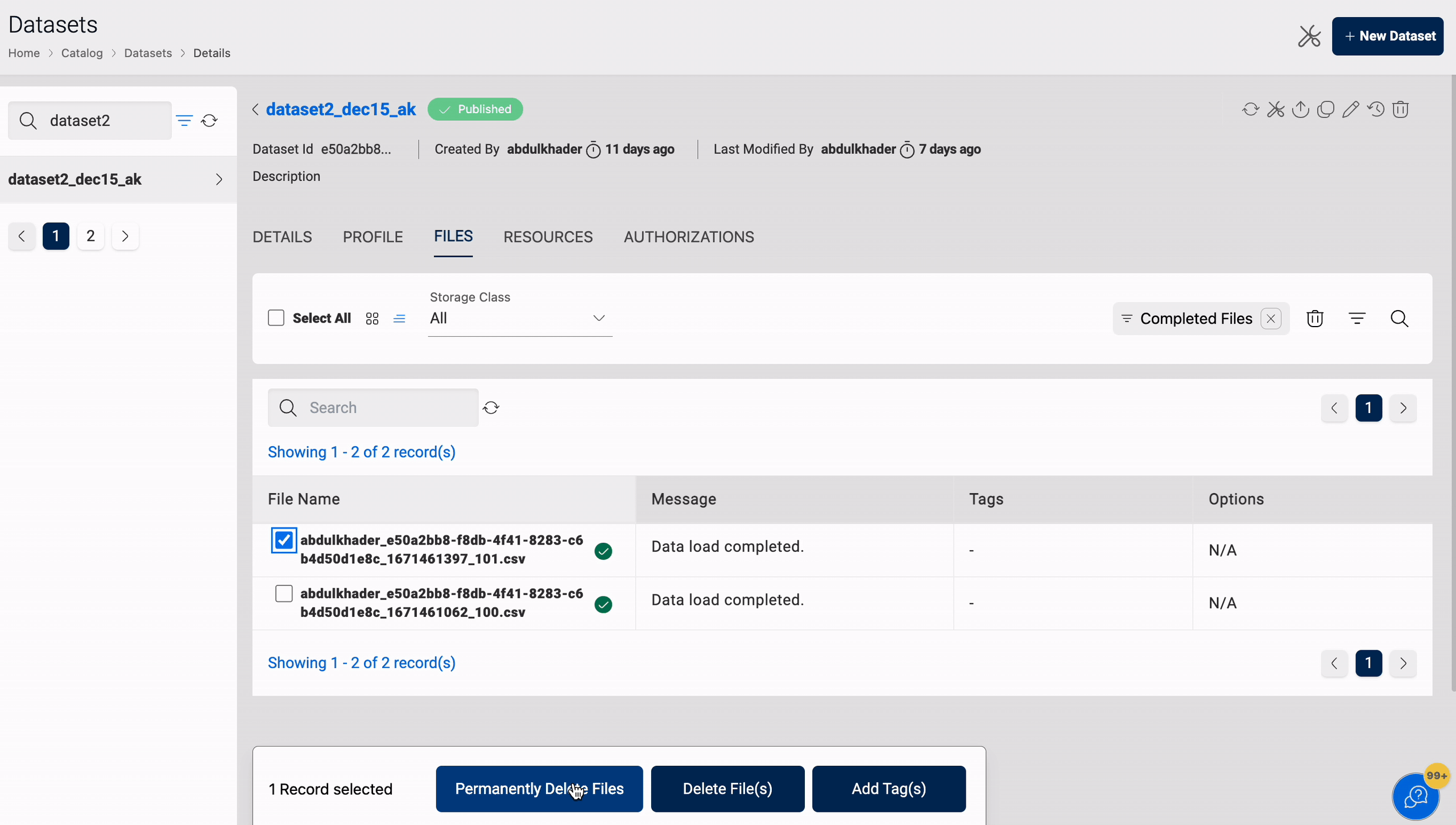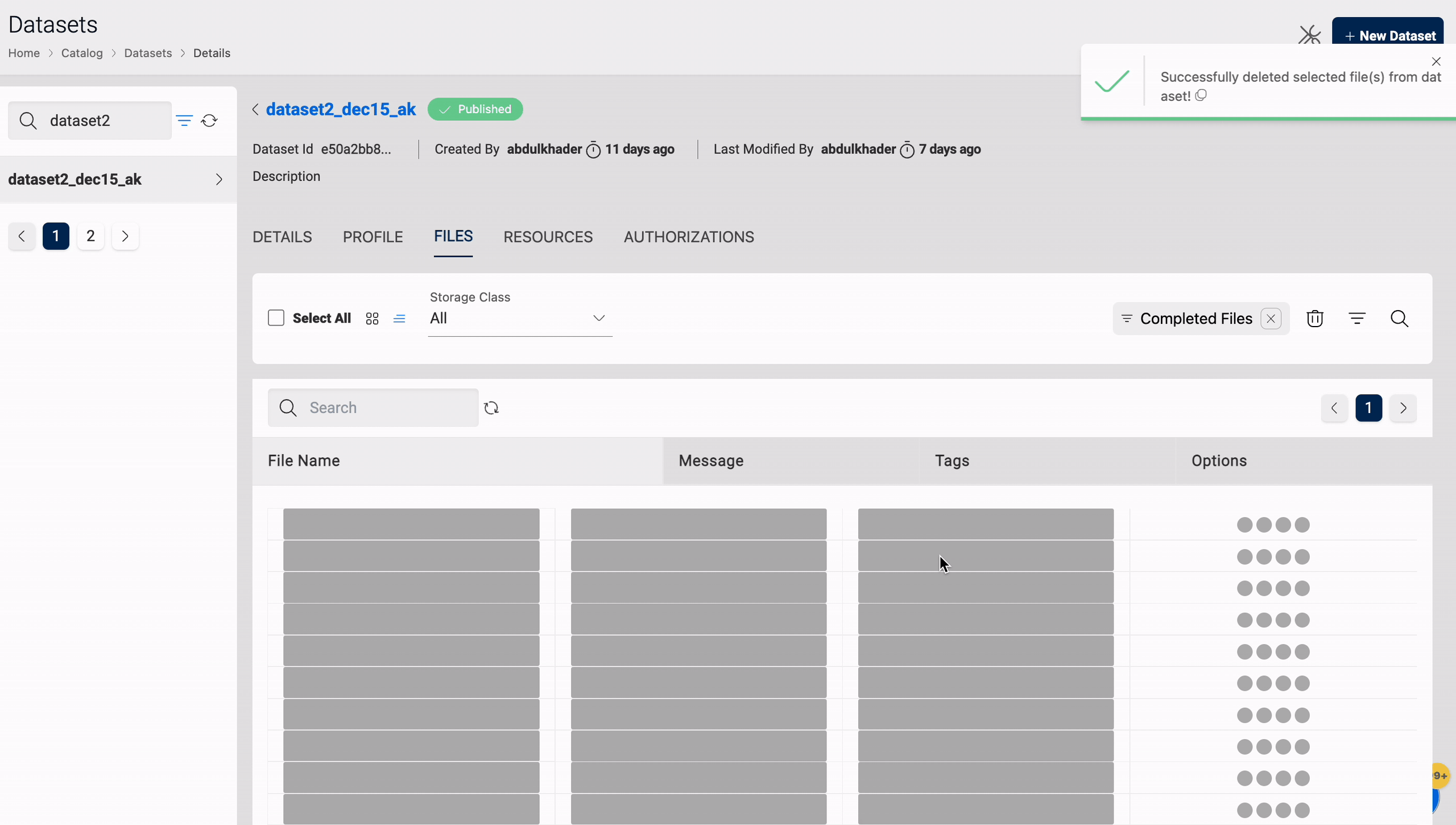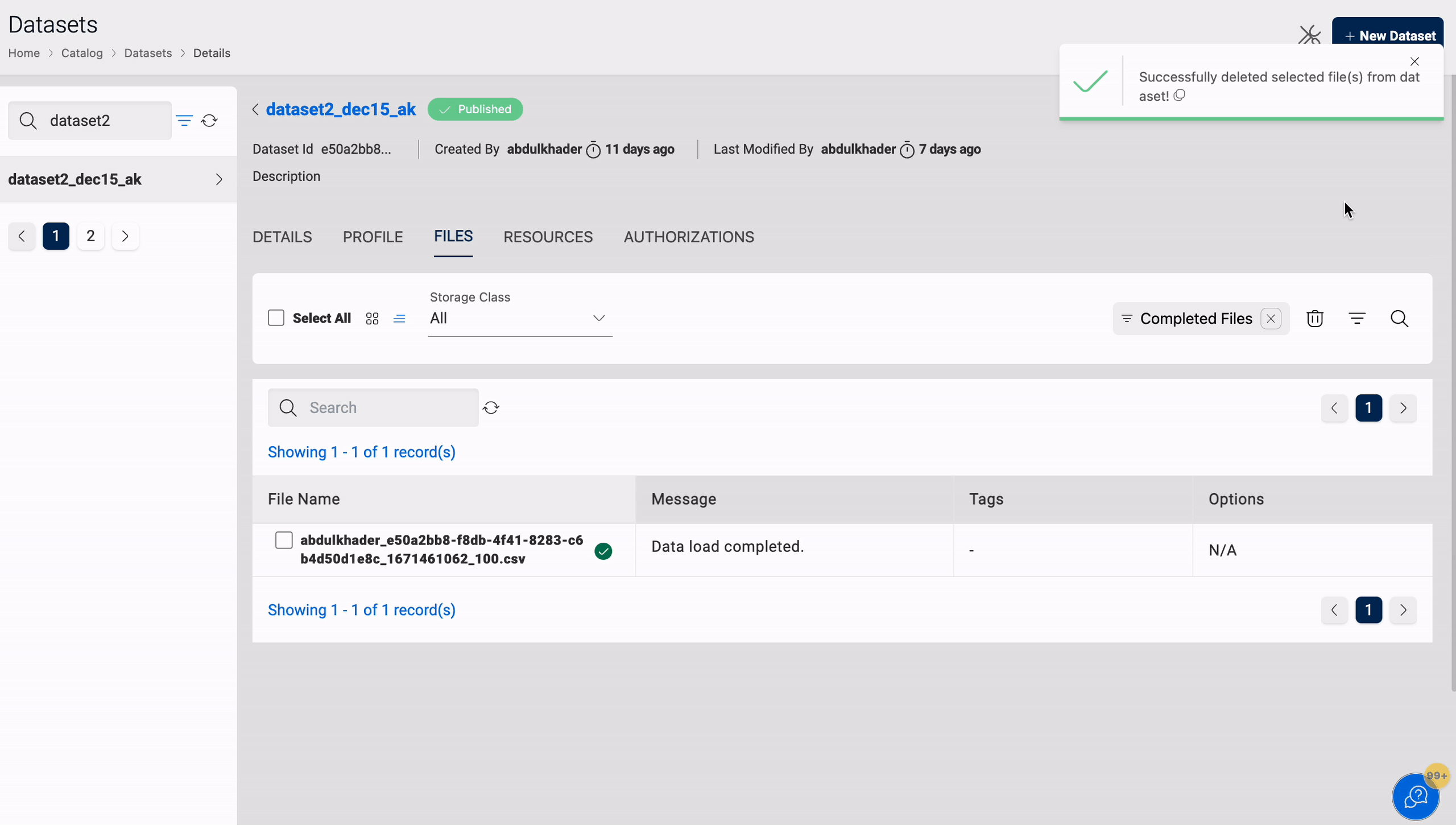
Permanent Delete
You can permanently delete files from the dataset. It is applicable to datasets located in S3 and S3-Athena.
File Level Tagging for TBAC S3 Datasets
Users have the option to add or remove tags from files using the "add tags" feature. By default, all 'Full Access' tags from the dataset are automatically applied to the files. Regarding 'Read-Only' tags, users can choose whether to inherit them or not.
Those with Full Access tag privileges can view all files and execute various actions such as deleting files or updating tags.
Users with only Read-Only access to the dataset can view files, but only if the files are tagged with Read-Only tags from the dataset. Additionally, users can augment files with tags not present in the dataset; to achieve this, they must designate a Read-Only tag from the dataset as the Primary Tag. Access to files is granted to users possessing both the newly added tag and the primary tag.
Furthermore, users with 'Read-Only' access to the dataset can have 'Full Access' to the files, enabling them to perform all actions on the files except 'Truncate Dataset.'
The following GIF illustrates how to update tags for files.
A file can have a maximum of five tags added to it.
Files use case
A company stores customer information in various files. To manage these files, the company does the following:
- The company uploads new files with updated customer information to the dataset, setting Skip LZ (Validation) to 'No' to ensure the data is validated before it is added to the tables.
- The newly added files are appended to the existing files, so the dataset always contains the latest customer information.
- The old files are reloaded, so the dataset is constantly updated with the latest information.
- The company can also truncate the dataset to permanently delete all the files if necessary.
- If a file is accidentally deleted, the company can restore it from the Deleted files or from the Archive, depending on where it is stored.
In this way, the company can effectively manage the customer information in their dataset, ensuring the data is up-to-date and accurate.