Dataset custom partitioning (Beta)
Dataset partitioning enables the user to ingest the data into custom partitions as they like which further helps in better reading the data and the query performance. In phase-1(v1.11) only S3Athena & LakeFormation are supported targets for the custom partitioning.
While uploading the data(from API), user must specify which partition the data needs to loaded to. Dynamic writes can still be done via ELT jobs on these datasets. As a pre-requisite dataset must be created with partitions to support this feature.
How to create datasets with partitions
Dataset registration can be done either via API or UI. API registration can be done through PostMan or from command line by specifying the dataset and partition schema's. Below is the API and it corresponding method on how to create dataset with partitions followed by an example. As dataset registration is a two-step process one can still perform part-1(Creating metadata) from UI and complete the registration using API.
API → /datasets/{datasetid} & PUT method
{
"DatasetSchema": [{"name": <string>, "type":<string> }, {"name": <string>, "type":<string> }, ....],
"PartitionKeys": [
{
"name": <string> (Name of partition column)
"type": <string> (Datatype of the partition column)
"rank": <int> (Rank/Position of this partition)
}
]
}
Example API call for the above
{"DatasetSchema":[{"name":"Region","type":"varchar(200)"},{"name":"Country","type":"varchar(200)"},{"name":"Item_Type","type":"varchar(200)"},{"name":"Sales_Channel","type":"varchar(200)"},{"name":"Order_Priority","type":"varchar(200)"},{"name":"Order_Date","type":"varchar(200)"},{"name":"Order_ID","type":"bigint"},{"name":"Ship_Date","type":"varchar(200)"},{"name":"Units_Sold","type":"bigint"},{"name":"Unit_Price","type":"double precision"}],
"PartitionKeys": [
{
"name": "partition_one",
"type": "varchar(200)",
"rank": 1
},
{
"name": "partition_two",
"type": "bigint",
"rank": 2
}]}
File upload via API
User must specify which partition the data needs to send to while uploading the file via API. Apart from FileName & DatasetId in the API, partition columns and their corresponding values must be specified. No change for the data loads that doesn't have partition columns.
API → /datasets/file & POST method
{
"FileName": <string>,
"DatasetId": <string>,
"PartitionKeys": {
<string>: <value>,
<string>: <value>,
}
}
Example API call for the above
{
"FileName": "Sales_Records.csv",
"DatasetId": "66b2dae9-b488-4375-9fee-a52859e56fdb",
"PartitionKeys": {
"partition_one": "sales_data",
"partition_two": 20211130105089
}
}
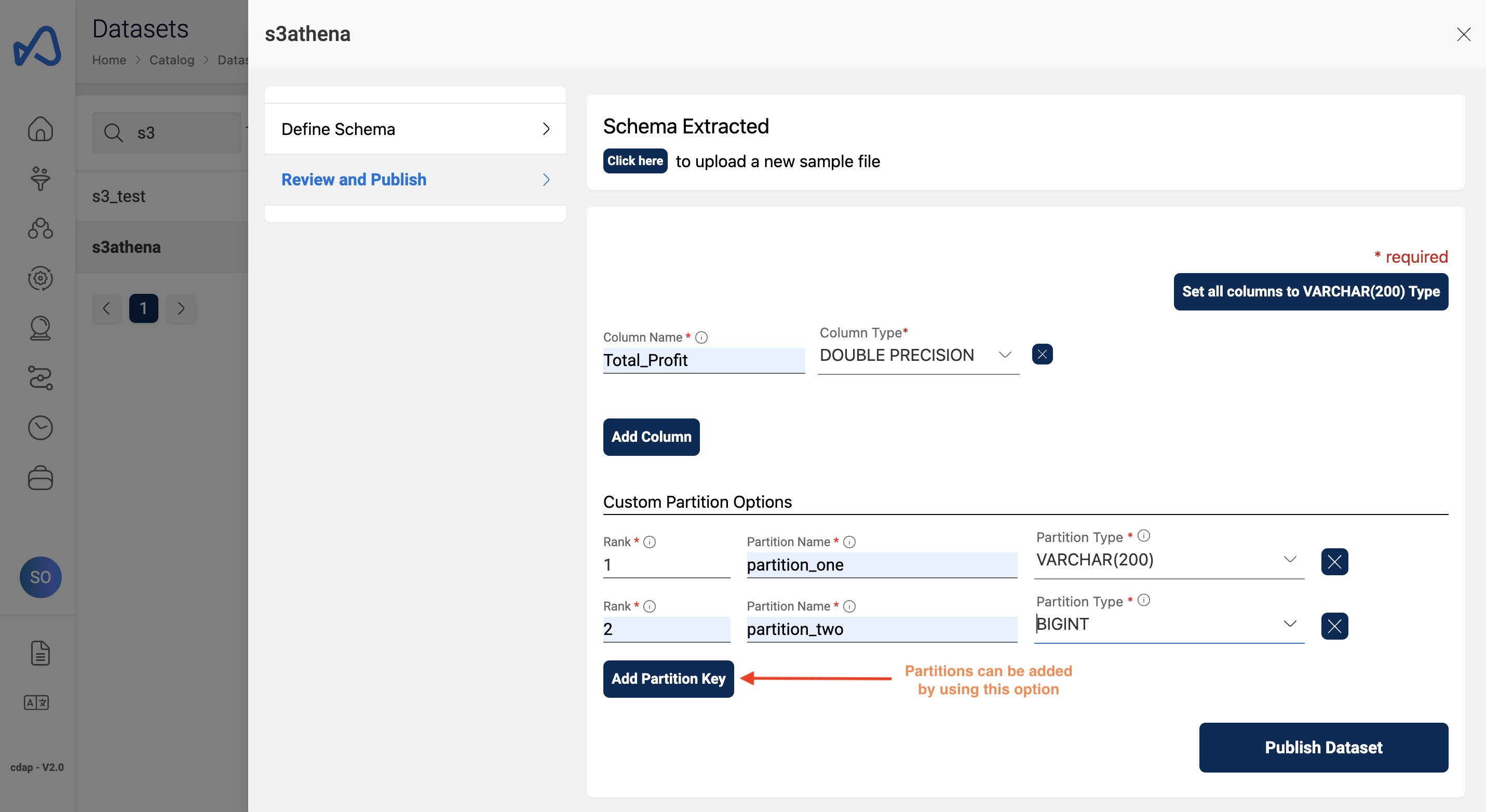
Adding partitions using UI
Partitions can be added to a dataset in the complete registration page, user must provide partition name, rank and the datatype of the partition, this can be done using custom partition options in the UI.
Below image shows how to add partitions to a dataset.
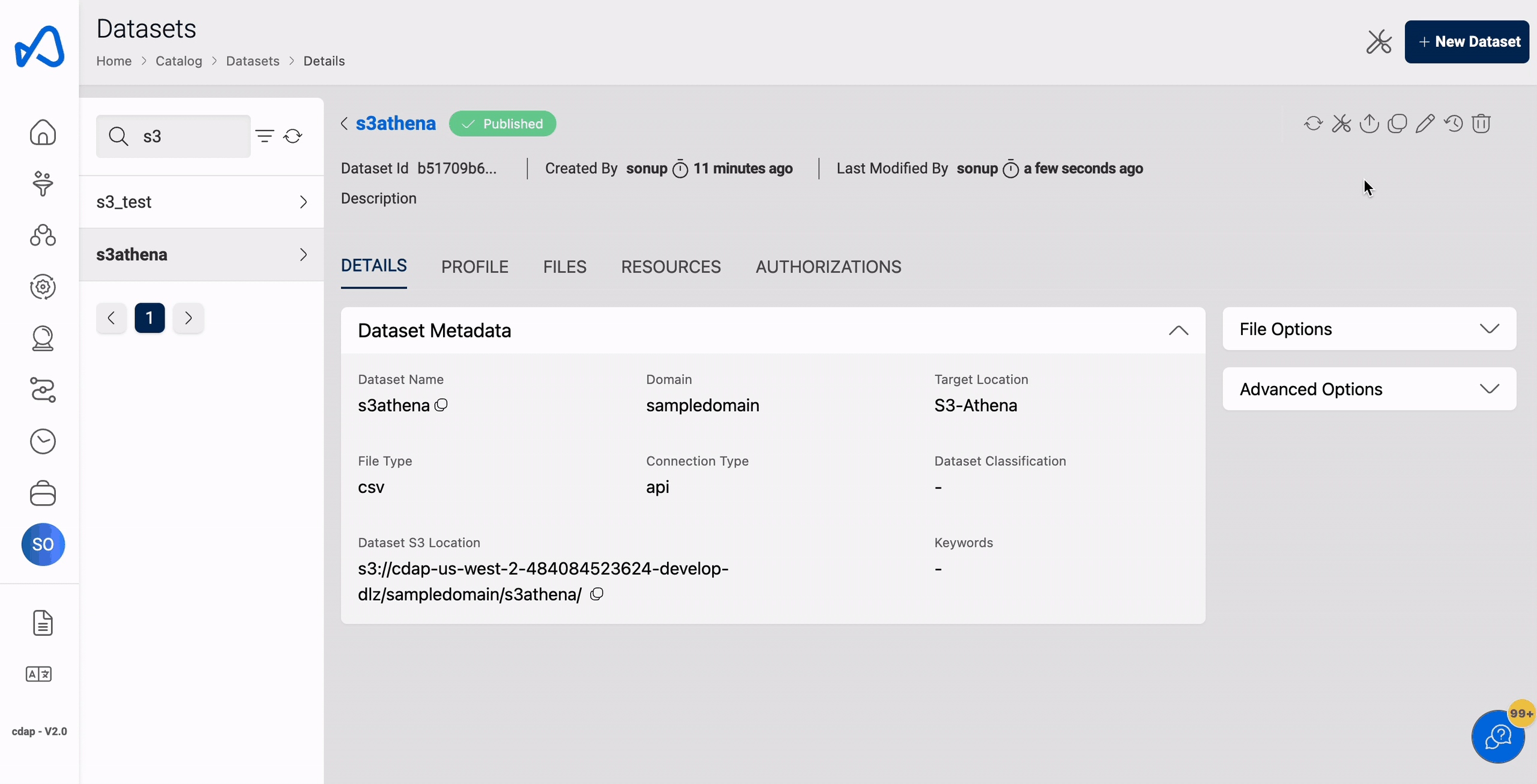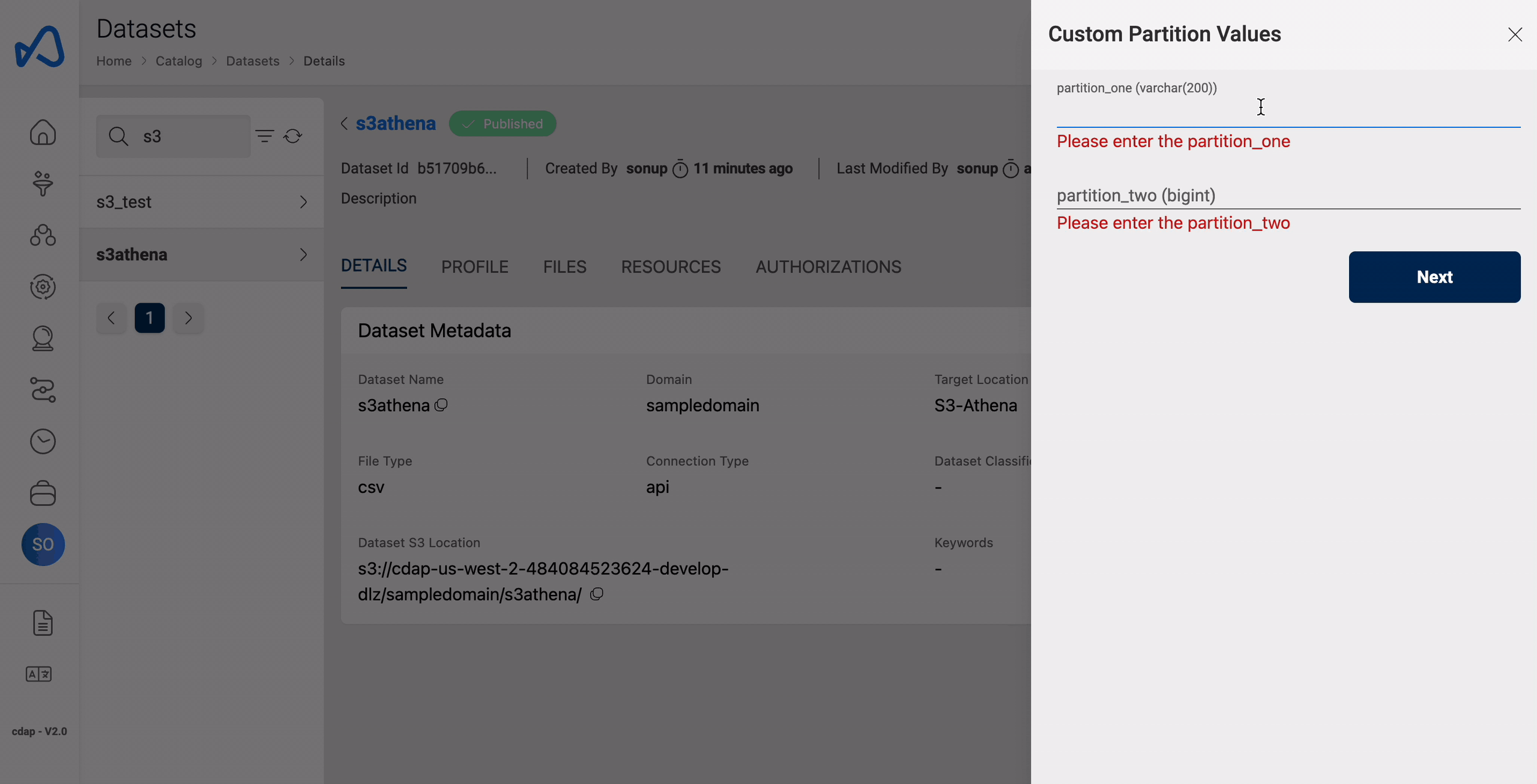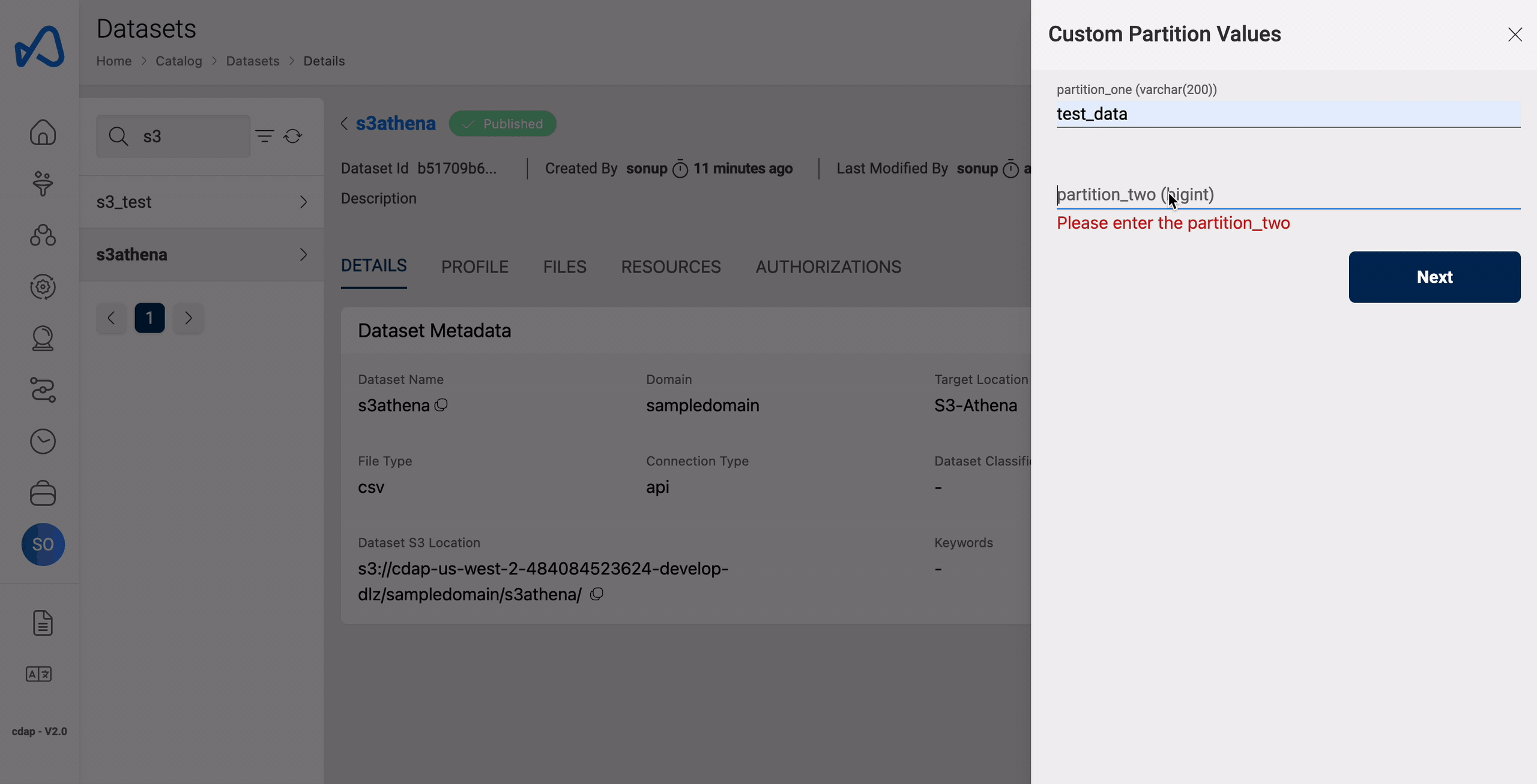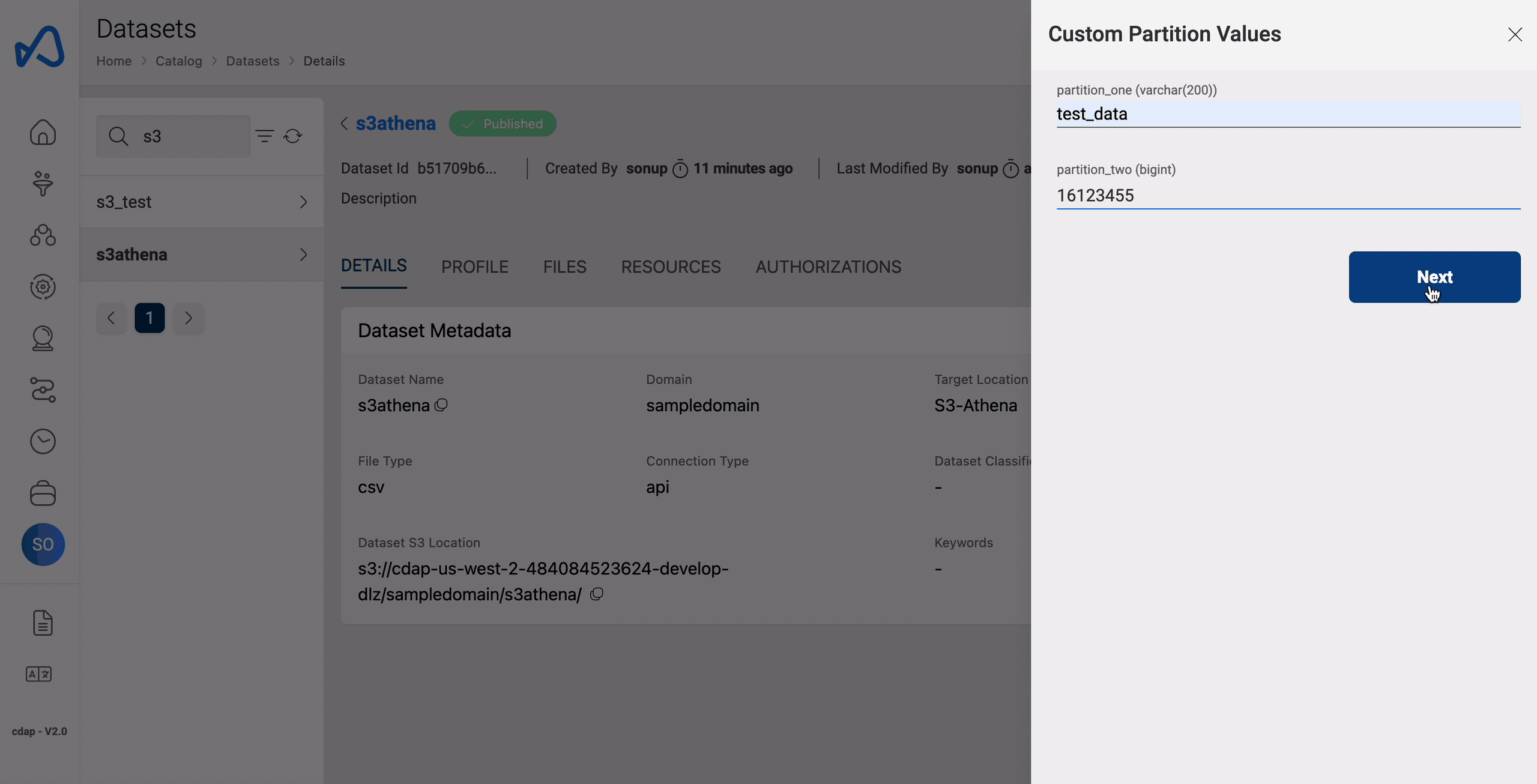
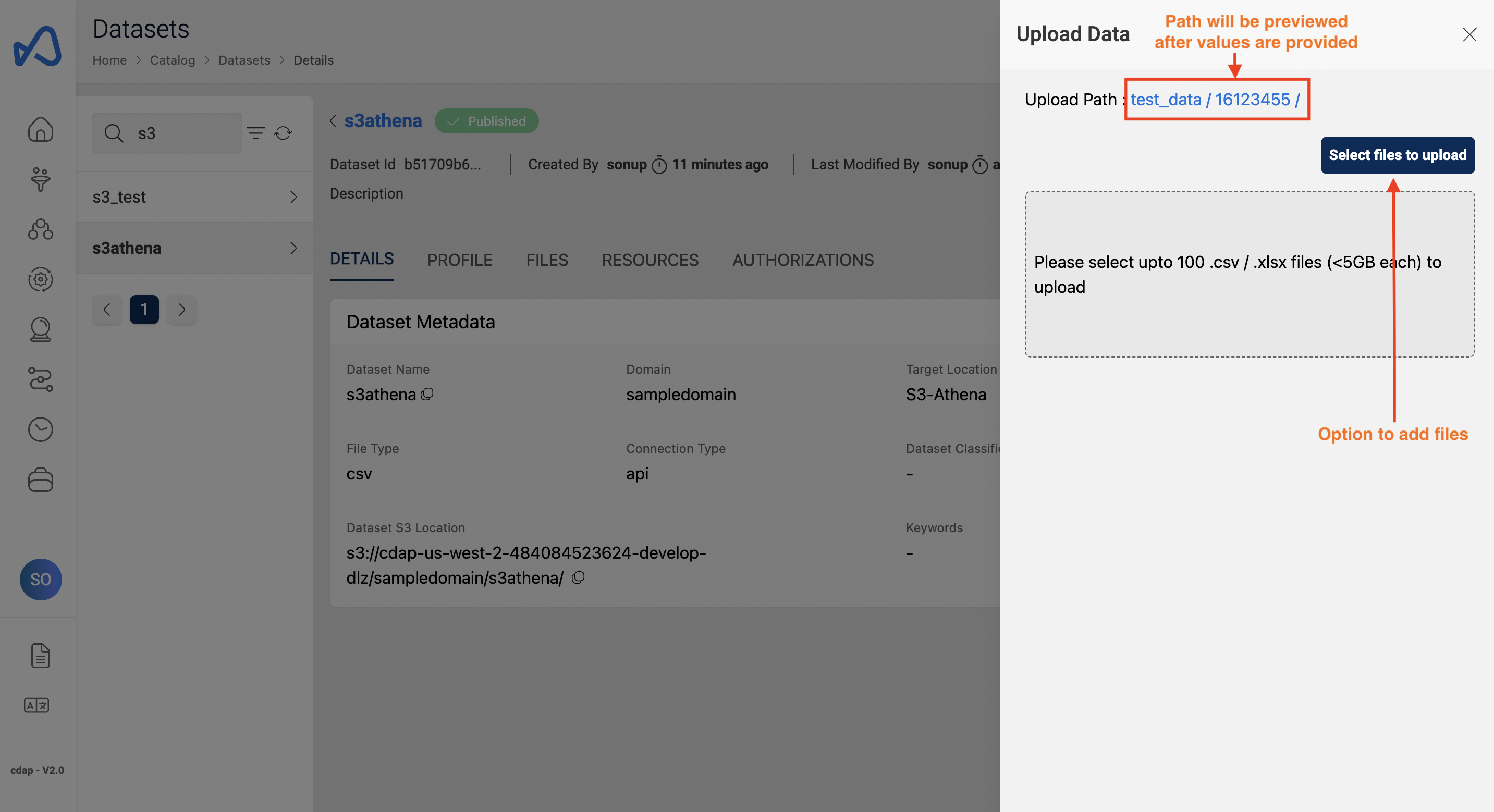
File upload using UI
Upon successful creation of dataset and during file upload, partition values must be specified so that the data will be loaded into that partition and can be used further for querying purposes.
Here is an example of uploading a file to a partition.