
Notebooks
Amorphic platform provides a way to host Jupyter/IPython notebooks, which are interactive, web-based environments that allow users to create and share documents that contain live code, equations, visualizations, and narrative text.
Amorphic Notebooks contain the following information:
| Type | Description |
|---|---|
| Notebook Name | ML Notebook Name, which uniquely identifies a Notebook |
| Description | A brief explanation of the notebook |
| Notebook Status | Status of ML Notebook. Ex: Creating, InService, Stopping, Stopped etc. |
| Instance Type | ML compute notebook instance type |
| Volume Size | The size of the ML storage volume attached to the notebook instance(in GB) |
| Notebook URL | URL to connect to the Jupyter server from notebook instance |
| Notebook Lab URL | URL to connect to the Jupyter Lab server from notebook instance |
| Glue Sessions | Flag to identify whether glue sessions are enabled for the notebook instance |
| Auto Stop | Status of the auto-stop. Ex: Enabled, Disabled |
| Remaining Time | Amount of time left for auto-stop(in hr) |
| Auto Stop Time | Time at which the system auto stops the ML Notebook. |
| Internet Access | Sets whether SageMaker provides internet access to the notebook instance |
| Lifecycle Configuration | Name of the lifecycle configuration attached to the notebook instance |
Notebook Operations
Amorphic ML Notebook provides the following operations for any given notebook.
| Operation | Description |
|---|---|
| Create Notebook | Create a ML Notebook in AWS Sagemaker. |
| View Notebook | View an existing ML Notebook. |
| Start Notebook | Start a Stopped ML Notebook. |
| Stop Notebook | Stop a Running ML Notebook. |
| Clone Notebook | Clone an existing ML Notebook. |
| Delete Notebook | Delete an existing ML Notebook. |
| Notebook Logs | View logs for ML Notebook. |
How to Create a Notebook?
To create an ML Notebook:
- Click on
+ New Notebook - Fill in the details shown in the table:
| Attribute | Description |
|---|---|
| Notebook Name | Give your Notebook a unique name. |
| Description | Describe the notebook's purpose and relevant details. |
| Instance Type | Choose the type of ML compute instance to launch the notebook instance. |
| Volume Size | ML notebook storage volume size in GB. |
| Datasets Write Access | Select datasets with write access required for the notebook. |
| Datasets Read Access | Select datasets with read access required for the notebook. |
| Domains Write Access | User can select domains with the write access required for the notebook. User will have write access to all the datasets (existing and newly created if any) under the selected domains |
| Domains Read Access | User can select domains with the read access required for the notebook. User will have read access to all the datasets (existing and newly created if any) under the selected domains |
| Enable Internet Access | This setting controls whether the notebook instance can access the internet. If you set it to "Disabled", the notebook instance can only access resources inside your VPC, and will not be able to use Amazon SageMaker training and endpoint services unless you set up a NAT Gateway in your VPC. |
| Glue Sessions | User can select this to enable or disable Glue sessions for the notebook instance |
| Auto Stop | This option allows you to save on resource costs by providing a stop time value. The auto stop process will be triggered every hour, looking for any ML Notebooks that need to be notified or stopped, and sending an email when one of the following criteria is met. |
| Shared Libraries | Select shared libraries required for the notebook using this option. |
| Lifecycle Configuration | Name of the lifecycle configuration to use for the notebook instance. Defaults to N/A for session disabled notebooks and to "enable-glue-sessions" for session enabled notebooks. |
| Views Access | Select views with read access required for the notebook. Only S3-Athena targeted views are supported. |
| Default Code Repository | User can select the amorphic code repository or provide the git repository url |
| Additional Code Repositories | User can select the amorphic code repository or provide the git repository url, only upto 3 additional repositories are supported by a notebook. |
- For getting AI powered code suggestions, user can attach the
enable-code-whispererlifecycle configuration to the notebook. Users can then navigate to the Notebook Lab URL and select the "Resume Suggestions" option from theCode Whispererextension available in the bottom left corner of the Jupyter Lab UI. - If you grant
read-onlyaccess to domains, you won't be able to queryLake Formationdatasets within that domain. However, you'll still have access to the files via S3 APIs. - To utilize GitLab, GitHub, or Bitbucket code repositories in an internet-disabled notebook, it is necessary to whitelist the application proxy with the corresponding repository domains.
You will receive a notification email when:
- The auto-stop process trigger runs every hour, and the stoppage time is less than 30 minutes.
- The auto-stop process was successfully able to stop the ML Notebook after the stop time.
- The auto-stop process wasn't able to stop the ML notebook due to some fatal errors.
Auto Stop Time: You can set the maximum auto stop time for the ML Notebook to be less than 168 hours (7 days). Once the current time is found to be greater than the stop time, the notebook will be stopped at the next whole hour. You can also modify the stop time with the maximum time set to less than 168 hours (7 days).
- Auto-stop process is scheduled to run every hour on the hour (e.g: 6:00, 7:00, 8:00, 9:00).
- You will receive an email notification only if you are subscribed to alerts. To enable alerts, refer to Alert Preferences.
- When the stoppage time elapses, auto stop process will stop the ML Notebook. You need to manually delete the notebook if needed.
- Stopped Notebooks will still incur costs. Hence, if the notebooks are not needed, delete them.
You can set up or create a new notebook instance and use your IPython notebook to perform model training. You can call Python Sagemaker SDK to create a training job.
Once a training job is created, you can use the S3 model location information to create a model in the Amorphic portal. For accessing the datasets inside the IPython notebooks, you can check the dataset details for the S3 location information. For example, the exhibit above shows the dataset details with the respective dataset S3 location.
For the purpose of creating a Sagemaker model in the notebook, the user can use the ml-temp bucket. Amorphic Notebooks have write access to the ml-temp bucket (for example, s3://cdap-us-west-2-484084523624-develop-ml-temp). Please note that this S3 bucket is almost the same as the dataset S3 path, except for the ml-temp at the end. This ml-temp bucket can be used to create a training job and upload a model tar file. This model file location can then be used to create a model using the "Artifact Location" of Amorphic model (see model creation section).
You can use the S3 location mentioned here to read the files related to the training dataset and save the output Sagemaker model tar file for Amorphic model object creation purpose.
Notebook Details
All the information specified while creating the notebook is displayed in the Details page, including the Notebook URL and Message field. The Message field displays information based on the notebook's status:
- If the notebook status is failed, the Message field displays failure information.
- If you do not have all the datasets, code repositories and views access required for the notebook, the Notebook URL will not be displayed and the Message field will show missing resource access information.
Following details are displayed when you enable auto-stop on the ML Notebook. Remaining Time denotes the amount of time (rounded to nearest upper hour) left for auto-stop.
In below image, the auto stop time is set to
10 July, 2023 7:300 PM but the ML Notebook will
be stopped at 10 July, 2023 8:00 PM
because the stoppage process is scheduled to run at whole hour (UTC)

Starting from version 1.9, Auto stop will be replacing Auto terminate. This process will only stop the notebook instance and will not delete the notebook instance.
In the details page, Estimated Cost of the ML notebook is also displayed to show the approximate cost incurred since the creation/last modified time.
Edit Notebook
The Edit Notebook page is divided into two sections:
- Basic Info: You can use this section to update all the basic details of the notebook.
- Instance Info: You can use this section to update instance details like type, size, auto-stop time etc.
- Code Repository: You can use this section to update the code repositories.
The ML Notebook must be in Stopped state in order to edit it.
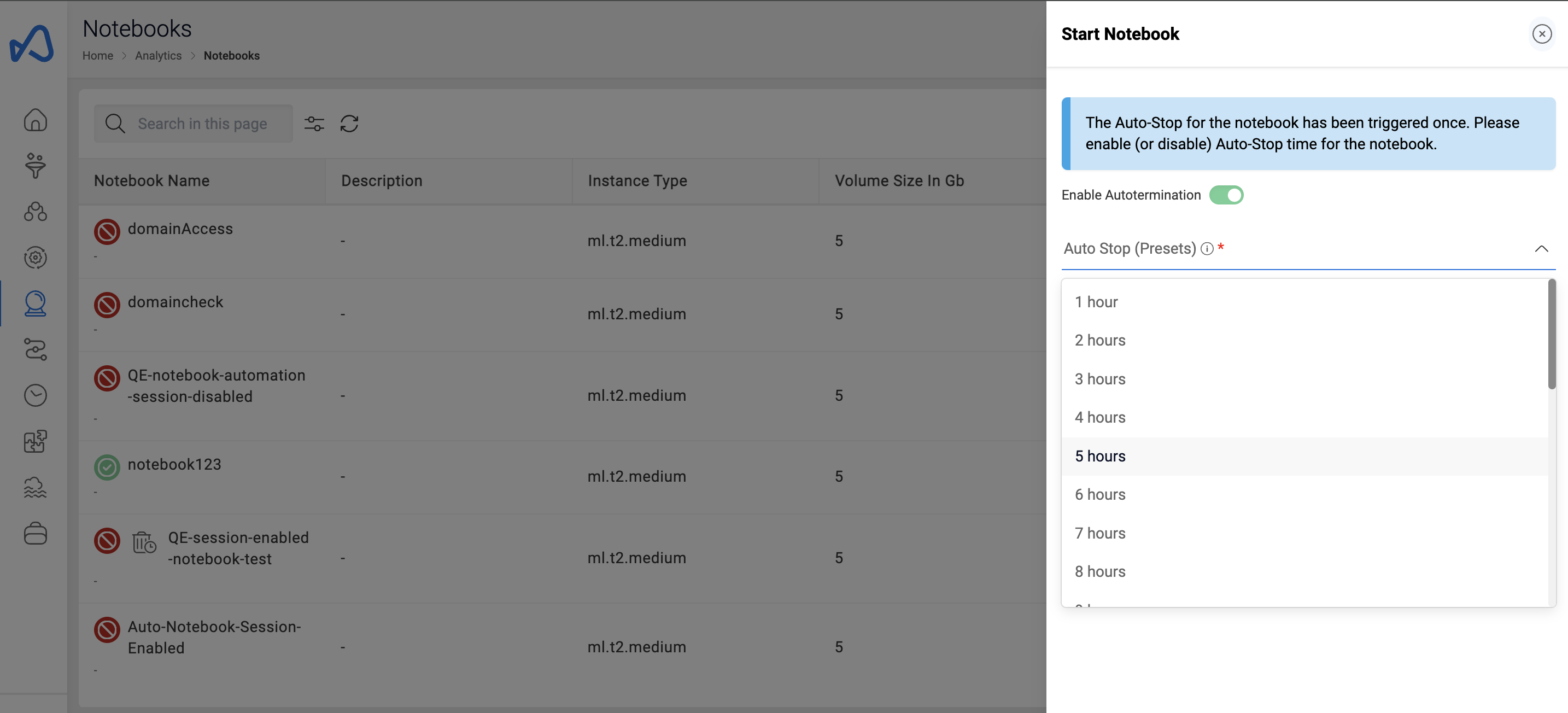
Start Notebook
When an ML Notebook is in the stopped state (stopped either manually or through auto stop), user has an option to resume or start the Notebook again. The option is available in the UI and can be triggered by pressing the play button icon situated beside the Notebook name.
When resuming a stopped ML Notebook, if it was created with Auto Stop and the Auto Stop time has already elapsed, users will have two options; either to disable auto stop and resume the ML Notebook, or to update the auto stop time with a newer one. The example below shows how it is done.

Stop Notebook
If an ML Notebook is in running state, user is provided with the option to stop it. This feature is useful to reduce incurring costs on running Notebooks. The option is available in the UI and can be triggered by pressing the stop button situated beside the Notebook name.
Clone Notebook
To help create Notebooks with similar properties, an option to clone an existing Notebook is available. Be sure that the name is different while going through the metadata. The option is available in the UI and can be triggered by pressing the clone button situated beside the Notebook name.
Delete Notebook
If you have sufficient permissions you can delete an ML Notebook. Deleting an ML Notebook is an asynchronous operation. When triggered, the status will change to deleting and the notebook will be deleted from AWS Sagemaker. Once the notebook is deleted in AWS Sagemaker, the associated metadata will also be removed.
Auto Stop Notebook Feature
From version 2.7, when a notebook is stopped with the auto-stop feature enabled, users have the option to set a custom auto-stop timer when restarting the notebook. This allows users to choose predefined options, such as 1 hour or 2 hours, or set a custom time after which the notebook will automatically stop. This feature helps users manage the cost of running notebooks, especially during business hours, by tailoring the auto-stop time to their specific needs.
The ML Notebook must be in Stopped state in order the delete operation on it.
Notebook Logs
Downloadable logs are now available for Notebooks. There can be one or three different types of logs available, depending on the type of Notebook being used.
For glue-session enabled notebooks, there are three types of logs, Creation Logs, Start Logs and Jupyter Logs. For glue-session disabled notebooks, there is only one type of log, Jupyter Logs.
The following example shows how to access the creation logs for a glue-session enabled Notebook.

Update Resources
Users can provide parameters, datasets, domains and shared libraries to notebook using the 'Update Resources' option from the three dots button on the top right side of the details page.
Update Extra Resource Access
To provide parameter or dataset access to a notebook in large numbers, refer to the documentation on How to provide large number of resources access to an ETL Entity in Amorphic
Manage External Libraries
Users can upload external libraries to glue session enabled notebooks using the 'Manage External Libraries' option from the three dots situated on the top right side of the details page.
Click the '+' sign on the top right & then Click on 'Select files to upload' and then 'Upload Selected Files' button after selecting the files to upload one or more library file(s).
Users can upload .zip, .py, and .jar files to the notebook.
The following example shows how to upload external libraries to glue-session enabled Notebook.

Users can remove the external libraries from the Notebook by selecting the libraries and clicking on the 'Remove selected libraries' button in 'Manage External Libraries'. User can also download the external libraries by clicking on the download button displayed on the right of each uploaded library path.
Glue Session Operations
Amorphic ML Notebook provides operations stated below for a glue sessions enabled notebooks.
| Operation | Description |
|---|---|
| Create Glue Session | Create a Glue session for a Notebook. |
| Stop Glue Session | Stop an existing Glue session for ML Notebook. |
| Delete Glue Session | Delete an existing Glue session for ML Notebook. |
| View & Download Logs for Glue Session | View and download logs of a Glue session for ML Notebook. |
Before initiating a Glue session, users also have the ability to configure spark settings using imperative magic commands provided by AWS. Below are some beneficial magic commands provided for user reference. For more information visit the link
| Magic Command | Type | Description |
|---|---|---|
| %help | shows generic help message with many possible commands and their explanation. | |
| %list_sessions | lists all the glue sessions. | |
| %status | show the current glue session status and configuration. | |
| %stop_session | stops the current glue sessions straight from the notebook. | |
| %number_of_workers | int | The number of workers of a defined worker_type that are allocated when a job runs. worker_type must be set too. The default number_of_workers is 5. |
| %worker_type | int | Standard, G.1X, or G.2X. number_of_workers must be set too. The default worker_type is G.1X. |
| %iam_role | String | Specify an IAM role ARN to execute your session with. Default from ~/.aws/configure |
| %additional_python_modules | List | Comma separated list of additional Python modules to include in your cluster (can be from PyPI or S3). |
| %extra_py_files | List | Comma separated list of additional Python files from Amazon S3. |
| %extra_jars | List | Comma-separated list of additional jars to include in the cluster. |
Create Glue Session

The user must create a notebook instance with Glue Session enabled as described in the steps for creating a notebook.
Once the notebook instance is active (if the notebook status is stopped, the user must start the notebook), the user can find the Notebook URL link or the Jupyter Lab URL link on the details page and on opening one of the links, the user gets redirected to the Jupyter server. The user then has to create a new Jupyter notebook with conda_glue_pyspark kernel.
If the user wants to import external libraries or shared libraries into the notebook, use the below Jupyter magics before starting a glue session:
%extra_py_filesfollowed by comma separated list of s3 locations for python files.%extra_jarsfollowed by comma separated list of s3 locations for jar files.%additional_python_modulesfollowed by comma separated list such as "awswrangler,pandas==1.5.1,pyarrow==10.0.0" for external python packages.
For additional details on the magic commands available the user can run the magic command %help.
Users can copy the S3 locations from the notebook details page and ETL libraries page for external and shared libraries respectively for glue enabled notebooks.
An example for adding extra python shared library to the session is shown below, for the amorphicutils library.
# copy the path from "Home -> Transformation -> ETL Library -> Details -> (hover over package path and click copy - use the version you need)"
%extra_py_files s3://<amorphic-etl-bucket>/common-libs/<library-id>/libs/python/amorphicutils.zip
Amorphic also supports external libraries which follow the following pattern, again for the amorphicutils library.
%extra_py_files s3://etl-bucket/<notebook-id>/libs/amorphicutils.zip
The following code example will help the user create a glue session for the notebook.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
With glue sessions enabled, notebooks offer the capability to execute SQL commands using Magic commands
%%sql
select * from table
Once the glue session is created, all active, stopped and failed sessions of the notebook can be viewed in the sessions tab of the notebook details page.
Stop Glue Session

Delete Glue Session

If a glue session enabled notebook is stopped, all the glue sessions associated with the notebook will be deleted.
View & Download Logs for Glue Session

Notebook use case
A use case for ML Notebook could be, a company that wants to use machine learning to predict customer churn.
The company can set up a new notebook instance on the Amorphic platform and use IPython notebooks to perform model training. They can call the Python Sagemaker SDK to create a training job using the customer churn data stored in the S3 bucket.
Once the training job is complete, the company can use the S3 model location information to create a model in the Amorphic portal. They can access the customer churn dataset inside the IPython notebooks using the dataset details and S3 location information. The ml-temp bucket can be used to create the Sagemaker model and upload the model tar file, which can then be used to create a model object in the Amorphic portal.
The company can use the S3 location mentioned in the use case to read the files related to the customer churn dataset and save the output Sagemaker model tar file for Amorphic model object creation. This allows the company to effectively train a machine learning model to predict customer churn and use it in their business processes.
- Recently, AWS announced that users of SageMaker service can only access the commercial Anaconda repository without requiring a commercial license until February 1, 2024. After this date, customers will need to determine their own Anaconda license requirements for continued use (refer official AWS documentation). If you are making use of Anaconda channels within your notebooks, you may need to evaluate your specific needs concerning the Anaconda license to ensure compliance and prevent any interruptions in your code (refer Anaconda's Terms of Service).
- Should you have already procured the necessary licenses, you can make use of the command
conda config --add channels defaultsto add Anaconda's commercial channels. - If you wish to continue using Anaconda without having to procure a license, there are a few free channels that you can use that are run by volunteer communities and offer best effort security (Ex:
conda,conda-forge,Bioconda). These can work well for research projects, prototypes, and education. However, they are not recommended for use in sensitive environments.
Query View in Notebook
A view can be queried in notebook using two different methods
Using python 'awswrangler' package: If the notebook has internet enabled, then the user can download the awswrangler python package into the notebook using the below command
!pip install awswrangler
Once the package is installed, the user can query the view by using the following code snippet
#imports
import pandas as pd
import awswrangler as wr
import boto3
# get the aws region
boto3_session = boto3.session.Session()
region_name = boto3_session.region_name
#function to get the notebook id
def get_notebook_id():
log_path = '/opt/ml/metadata/resource-metadata.json'
with open(log_path, 'r') as logs:
_logs = json.load(logs)
return _logs['ResourceName']
ssm_client = boto3.client('ssm', region_name)
athena_bucket_name = ssm_client.get_parameter(Name="SYSTEM.S3BUCKET.ATHENA")["Parameter"]["Value"]
notebook_id = get_notebook_id()
# glue sessions disabled notebook has notebook_type -> sagemaker
# glue sessions enabled notebook has notebook_type -> sagemaker-glue-session
notebook_type = "<>"
# set the database name & view name to query the data from
domain_name = "<>"
view_name = "<>"
# set the quey output loc -> s3://AthenaBucket/NotebookType/NotebookId/
df_athena = wr.athena.read_sql_query(f"SELECT * FROM {domain_name}.{view_name}", database=domain_name, ctas_approach=False, s3_output=f"s3://{athena_bucket_name}/{notebook_type}/{notebook_id}/")
Using boto3 S3-Athena client: If the notebook has internet disabled or a view is queried inside a conda_glue_pyspark kernel in glue sessions enabled notebook, then the user should prefer using the below script.
#imports
import boto3
# get the aws region
boto3_session = boto3.session.Session()
region_name = boto3_session.region_name
#function to get the notebook id
def get_notebook_id():
log_path = '/opt/ml/metadata/resource-metadata.json'
with open(log_path, 'r') as logs:
_logs = json.load(logs)
return _logs['ResourceName']
#boto3 clients
athena_client = boto3.client("athena")
ssm_client = boto3.client('ssm', region_name)
athena_bucket_name = ssm_client.get_parameter(Name="SYSTEM.S3BUCKET.ATHENA")["Parameter"]["Value"]
notebook_id = get_notebook_id()
# glue sessions disabled notebook has notebook_type -> sagemaker
# glue sessions enabled notebook has notebook_type -> sagemaker-glue-session
notebook_type = "<>"
# set the database name & view name to query the data from
database_name = "<>"
view_name = "<>"
# set the quey output loc -> s3://AthenaBucket/NotebookType/NotebookId/
query_output_loc = f"s3://{athena_bucket_name}/{notebook_type}/{notebook_id}/"
#initiate the query through athena client
queryStart = athena_client.start_query_execution(
QueryString = f'SELECT * FROM {database_name}.{view_name}',
QueryExecutionContext = {
'Database': database_name
},
ResultConfiguration = { 'OutputLocation': query_output_loc}
)
# after starting the execution of the query, user should wait for s3athena to process the equation
queryExecution = athena_client.get_query_execution(QueryExecutionId=queryStart['QueryExecutionId'])
results = athena_client.get_query_results(QueryExecutionId=queryStart['QueryExecutionId'])