
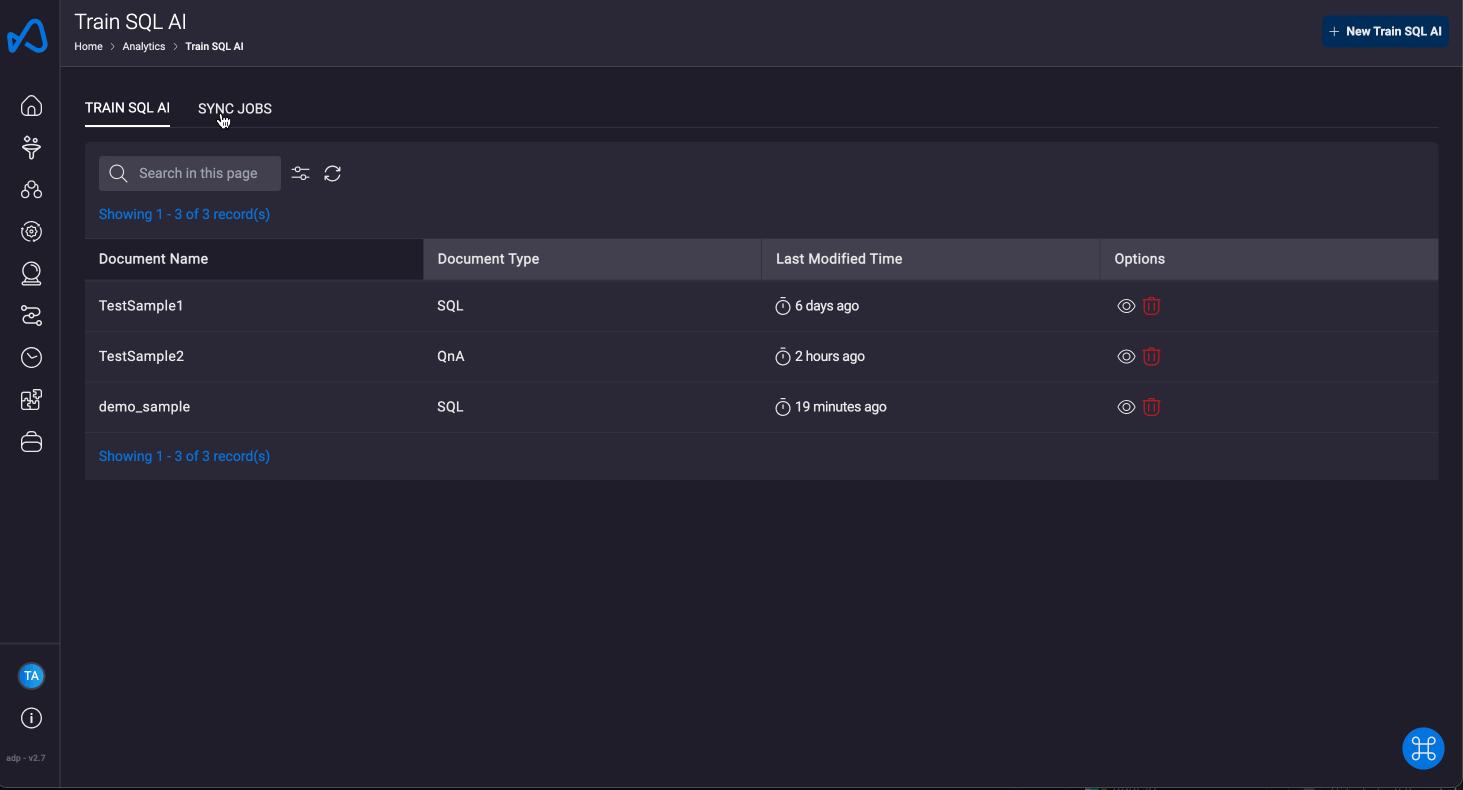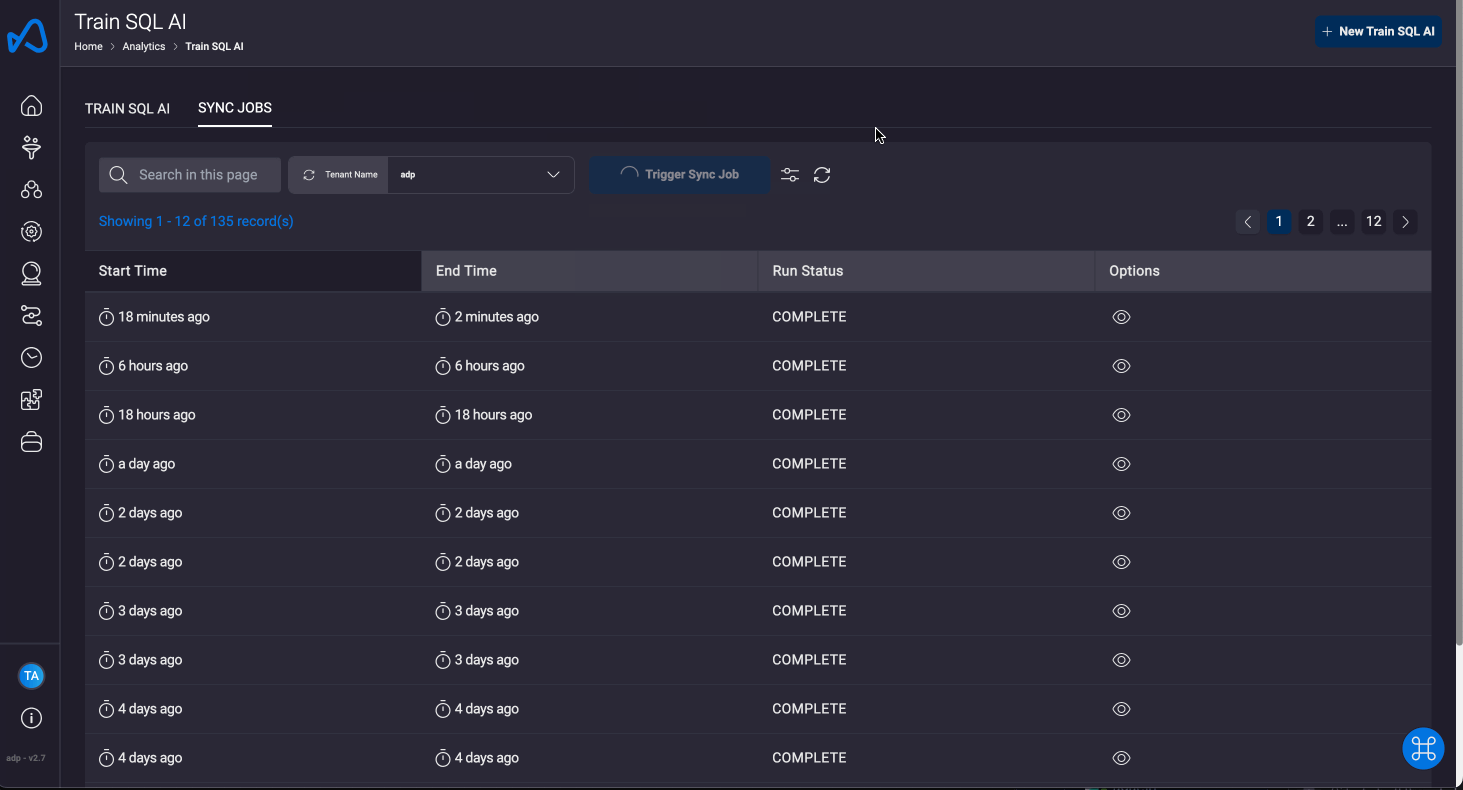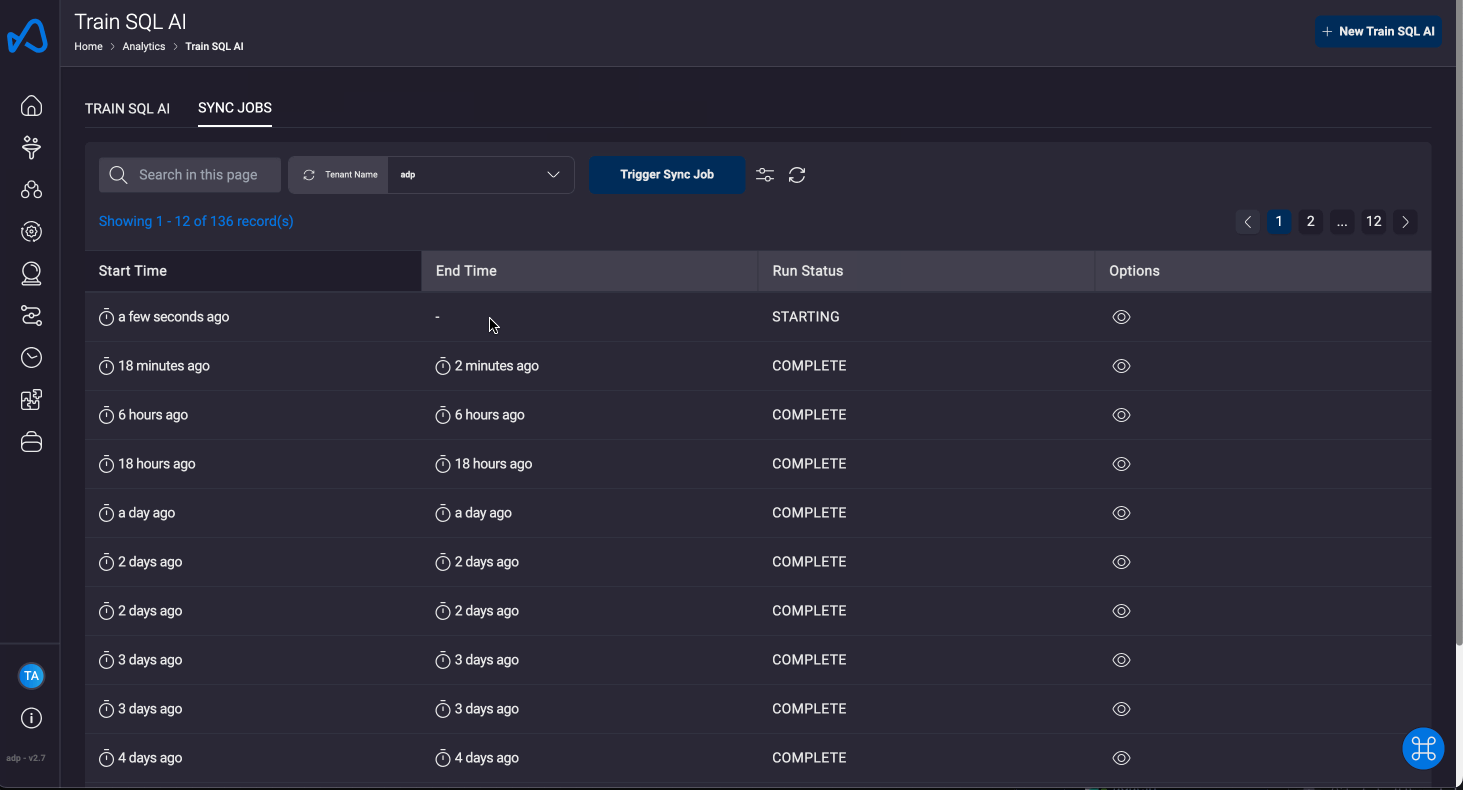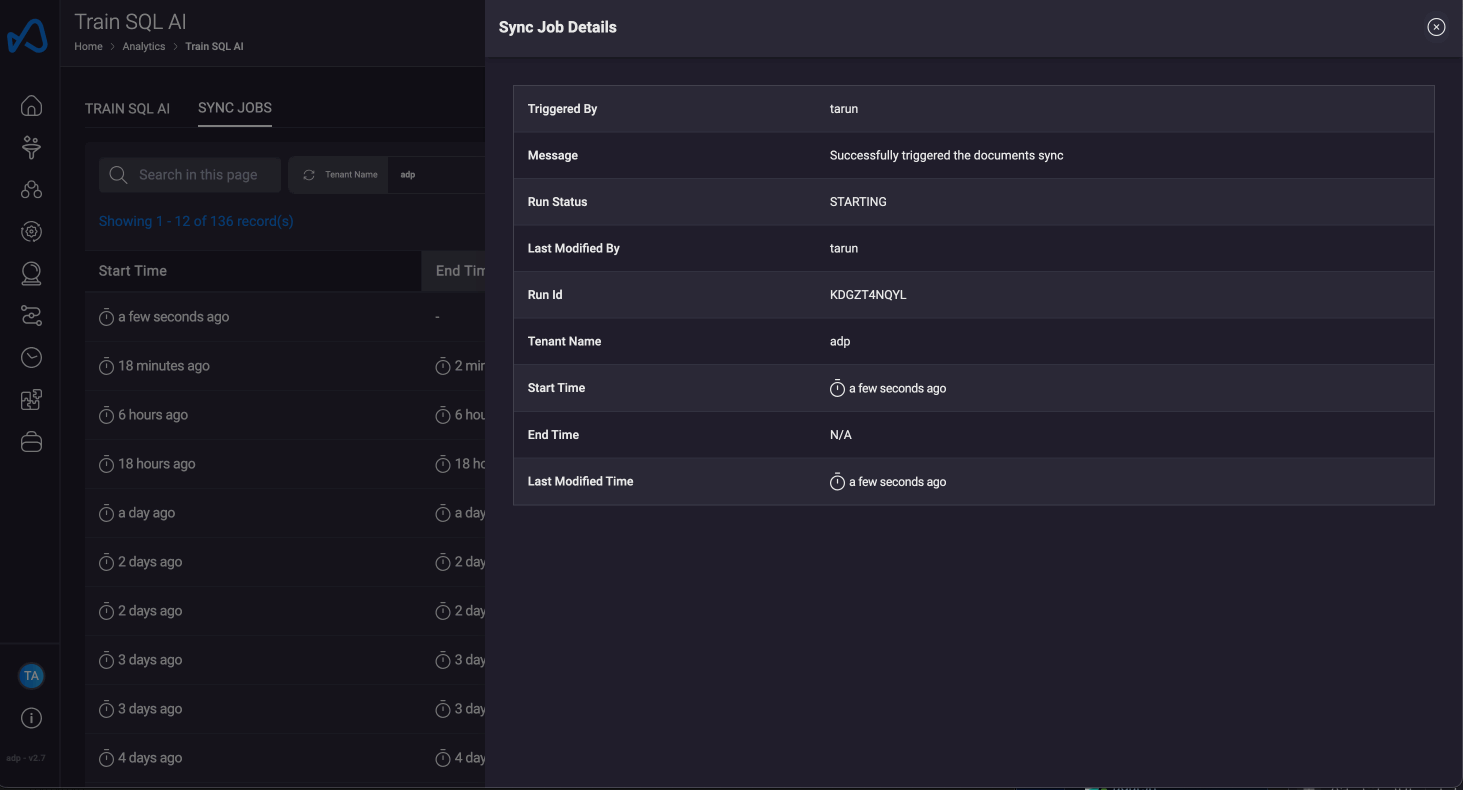
Train SQL AI
Under this section, user can use any created datasets or views as metadata training sample for the SQL AI to configure itself from thereby giving end user the flexibility of molding the SQL AI as per there own use case. This allows for varied use case and increased result generation accuracy.
Two options are available under this section:
Training Data
Here, you can associate training data with an existing dataset or view to enhance the SQL AI's responses for that resource. Training data gives the model additional context, leading to more accurate results.
As the number of resources in the system grows, it becomes increasingly challenging for the model to provide precise answers for a specific resource, which may result in response inaccuracies or hallucinations. Training data plays a crucial role by supplying targeted context, helping the model avoid such issues.
Training Data Types
SQL
You can add a list of successfully executed queries or queries that are commonly used on top of the specified resources. This will help the system understand the context of the questions that are being asked.
QnA
You can also train the system using question-SQL pairs, which is the most straightforward method. This approach is particularly useful for helping the system grasp the context of the questions being asked. Question-SQL pairs hold valuable information that helps the system grasp the context of a question. This is particularly helpful when users ask questions that are often ambiguous.
Documentation
This can include any relevant documentation about your database, business, or industry that may be important for the LLM to comprehend the context of a user's question.
Create Training Data
To create a training data:
- Select
Create Training Data - Fill the following details
| Attribute | Description |
|---|---|
| Document Name | Name for the training data resource. |
| Document Type | Type of training data created(SQL, QnA and Documentation) |
| Associated Resource Type | Resource Type to which training data will be associated |
| Associated Resource Id | ID of the resource to which training data will be associated(from the selected resource type) |
- Select the document to upload for training data.
Supported File Types
| Format | Extension |
|---|---|
| Plain Text | .txt |
| Markdown | .md |
| HyperText Markup Language | .html |
| Microsoft Word document | .doc/.docx |
| Comma-seperated values | .csv |
| Microsoft Excel spreadsheet | .xls/.xlsx |
| Portable Document |
Once the training document is created, users can download the attached document from the details page. Only one file can be attached per resource for each document type i.e. SQL, QnA, or Documentation.
All users which have access to the training data's associated resource will be able to use the enhanced SQL AI if the sync job was run.

Delete training data
If you notice that adding the training data is having a negative impact on the model's responses, you can remove the training document.
- Once training data is added or deleted, a sync job needs to be run for the tenant in which the associated resource is present for the context to be updated.
- When trying to generate a query on resources present in different tenants, the training data from only one of the tenants will be taken into context
Sync Jobs
Sync jobs are responsible for updating the model's context with the most recent data. This includes information related to newly added or removed datasets, as well as updates to the training data.
In this section, you can monitor all the sync jobs that have been executed, along with their current status and statistics regarding the number of documents which are indexed, modified or deleted. Additionally, you have the ability to manually trigger sync jobs for a specific tenant, ensuring that the knowledge base for that tenant is always up-to-date with the latest data. This manual sync can be particularly useful for keeping the model relevant and accurate for tenant-specific queries.
An automated sync job is also triggered every 12 hours