
Intro
The Amorphic Dataset portal allows you to create unstructured, semi-structured, and structured Datasets, while also providing comprehensive data lake visibility. These Datasets can act as a unified source of truth for different departments within an organization.
Datasets with the same name can now be created throughout the application. That is, more than one dataset can have the same name, but it must be unique within a specified domain. Domain name will now be visible alongside the dataset name throughout the Amorphic application.
The Amorphic Dataset page provides the capability to search through the Dataset Metadata using a Google-like search index. It consists of options to list or create a new Dataset. You can sort through the Datasets using the Domain filters, create new Datasets, or view Dataset details.
How to create a New Dataset?
To create a new dataset click on + New Dataset, and fill the require information like
Domain, Connection type and File Type etc. mentioned below.

To create a Dataset in the Amorphic dataset, you must first create a Domain using Amorphic Administration. Then, you can create a Dataset and upload structured, semi-structured, or unstructured files to it.
Dataset Name: 3-120 alphanumeric/underscore chars; Must be unique per Domain.
Description: Contains info about a topic; text searchable.
Domain Name: Groups related datasets; used as 'database' in Glue/Athena, schema in Redshift.
Classifications: Categories to protect data (e.g. PCI, PII).
Keywords: Meaningful words to index/search within app; helps find related datasets.
Connection Type: Currently amorphic supports below connection types.
- File Upload: Default connection for manual file upload. Refer to Dataset files docs for more info.
- JDBC: Ingest data from JDBC connection as source to dataset. Scheduled ingestion.
- S3: Ingest data from S3 connection. Scheduled ingestion.
- Ext API: Ingest data from external API. Scheduled ingestion.
- Email: Ingest data sent over emails.
File Type: File type should be compatible with ML Model's supported formats. Use auto ML to extract metadata from unstructured datasets integrated with AWS Transcribe and Comprehend services.
Target Location: Currently amorphic supports below target locations.
S3: Files uploaded to dataset stored in S3.
Redshift: Files stored in Redshift datawarehouse. DB selection during deployment determines which DB is displayed.
S3-Athena: Structured data stored in Athena. Refer to Athena Datasets for more info.
Lakeformation: Lakeformation datasets extend S3-Athena datasets, providing access control on dataset columns. For more info, see Lakeformation Datasets.
NoteIf the target location is a data warehouse (Redshift/S3-Athena), the user should upload a file for schema inference and then publish the schema.
Update Method: Currently amorphic supports below three update methods.
Append : This will append data to the existing data.
Latest Record : This update method allows you to query the latest data using the Record Keys and Latest Record Indicator defined during the schema extraction process.
Reload : This update method reloads data to the dataset. There are two exclusive options for a Reload type dataset:
Target Table Prep Mode
- Recreate : Dataset will be dropped and recreated when this option is selected.
- Truncate : Just the data is deleted in the dataset without deleting the table.
Skip Trash (Optional) : When Skip Trash is True old data is not moved to Trash bucket during the data reload process, default is true when not provided.
Based on the above reload settings, data reload process times can vary.
Data Files Have Headers: Users can specify if the dataset files contains headers. Files must consistently include or not include headers. In schema definition step, user may use a sample file with headers even if the final dataset files will not contain headers.
For S3-Athena and Lake Formation type of datasets, users can use additional attributes:
Skip Header Row Count: Specify the number of lines (from starting of the file) to be ignored for every file while querying the dataset through Query engine/other services. This count does include the header along with data rows. For example, If user specifies value as 10 then it ignores 10 starting rows in a file which means it'll skip the header and the next 9 data rows.
Skip Footer Row Count: Specify the number of footer lines to be ignored for every file while querying the dataset through Query engine/other services. The rows from the end of the file will be ignored while querying the dataset.
For example: If user created a S3Athena/Lakeformation dataset with skip header count as 10 and footer count as 5. Uploaded a file with 30 rows then ONLY 16 rows will be retrieved while querying the dataset by excluding/ignoring the starting 9 data rows (1 for header) and last 5 rows i.e. 30-9-5 = 16 data rows.
Important NoteNo changes are being made to the original data uploaded to dataset. This functionality just ignores the header/footer rows while querying the dataset and files stored in s3 will have all the data rows.
For Redshift type of datasets, If 'Data Files Have Headers' set as Yes then users can use additional attributes:
Skip Header Row Count: Specify the number of lines (from starting of the file) to be ignored for every file being uploaded to the dataset. This count does include the header along with data rows. For example, If user specifies value as 10 then it ignores 10 starting rows in a file which means it'll skip the header and the next 9 data rows.
For example: If user created a Redshift dataset with skip header count as 10. Uploaded a file with 30 rows then ONLY 21 rows will be uploaded to the dataset by excluding/ignoring the starting 9 data rows (1 for header) i.e. 30-9 = 21 data rows.
Important NoteChanges are made to the original data uploaded to redshift dataset. Still the original data is being present in S3, which we can query it using Query Target location as Athena.
Skip LZ (Validation) Process: This functionality deals with dataset file upload. If the Skip LZ is set to True, the whole validation (LZ) process will be skipped and the file will be directly uploaded to the DLZ bucket. This will avoid unnecessary S3 copies and validations, and will automatically disable MalwareDetection and IsDataValidationEnabled (for S3Athena and Lake formation datasets). It is applicable only to append and update types of datasets. If it is set to False, the LZ process with validations will be followed.
As of Amorphic 1.14, this is applicable to the dataset file upload process through Amorphic UI (manual file upload), ETL (file write) process streams, and Appflow. It is not applicable to other file upload scenarios like ingestion and Bulkloadv2. The SkipLZ feature will be implemented for these other scenarios in upcoming releases.
- Additional Parameter: Users have the capability to provide allowed additional parameters in the form of key-value pairs. In scenarios where multiple values are possible, they can be provided as a comma-separated list. As of Amorphic version 2.4, this option is available exclusively for Email Connection Datasets.
- Enable Malware Detection: Whether to enable or disable the malware detection on the dataset.
- Unscannable Files Action: When malware is found in a file uploaded to the dataset, decide whether to quarantine or pass-through the file.
- Enable Data Profiling: This is only applicable for datasets targeted to S3Athena or DataWarehouse (Redshift).
- Enable AI Services: Only applicable for datasets targeted to S3.
- Enable Data Cleanup: User can enable/disable dataset auto clean up. Data deletion to save storage costs is based on inputted clean up duration. All files past expiration date (clean up duration) will be removed permanently, not undoable. Expired datasets are identified by upload date, not time. E.g. file uploaded August 21, 2020 4:55 PM, clean up duration 2 days, clean up happens August 23, 2020 12:00 AM, not 4:55 PM.
- Enable AI Results Translation: User can enable/disable AI result translation to English for datasets. Amorphic runs ML algorithms to analyze PDF/TXT files uploaded to datasets. Option to enable/disable auto-translate AI results to English, for user to read/search Amorphic interfaces.
For example, Amorphic can identify language, run ML algorithms & analyze sentiment in an Arabic PDF document. Setting the flag to “No” allows user to preserve native language and query AI results in original language. AI results default to English, unless user specifies another language.
Enable Life Cycle Policy: Only applicable for datasets targeted to S3, S3-Athena & LakeFormation.
Enable Data Metrics Collection(API Only): Currently, this feature is only available for datasets regardless of its TargetLocation. If the flag is enabled, the metrics of the dataset will be collected every day. This collected data helps to display the necessary information on the Insights page. Metrics will be automatically expired one year after they are collected.
### API Request Payload Details
- To create a dataset along with enabling/disabling dataset metrics collection
**/datasets** & **POST** method
```
{
(Include all attributes required for creating dataset)
(Include attributes specified below in second point)
}
```
- To update dataset metrics collection flag
**/datasets/{id}/updatemetadata** & **PUT** method
```
{
"DataMetricsCollectionOptions": {
"IsMetricsCollectionEnabled": <Boolean> (true|false)
}
}
```
- To fetch dataset metrics up to given duration in days
**/metrics/datasets/{id}?duration={days}** & **GET** method
`Request Body Not Required`
- Sample Metrics
{
"FileCount": 1,
"TotalFileSize": 5391,
"AvgFileSize": 5391,
"ProcessingFiles": 0,
"TotalFiles": 2,
"CorruptedFiles": 0,
"FailedFiles": 1,
"CompletedFiles": 1,
"DeletedFiles": 0,
"InconsistentFiles": 0, # Negative value indicates that S3 has more files than DynamoDB metadata and vice versa.
"PendingFiles": 0,
"DependentViews": 2,
"AuthorizedTags": 2,
"DuplicateRows": 0,
"Columns": 7,
"DatasetSize": "10 MB",
"Rows": 100,
"PercentageOfDuplicateRows": 0.0
}
`Note: Here only dependent views count are listed, it can also contain other dependent resources`
Amorphic currently supports character recognition in two languages: English and Arabic. Support for additional languages will be added over time.
The Notification settings have been moved to the Settings page. Users can use this page to choose the type of notification settings for their Datasets. Please refer to the Notification settings documentation for more information.
For a multi-tenancy deployment, data uploaded to the Dataset is stored in its respective tenant database. For example, if a User creates a Dataset under the domain "testorg_finance", all the data uploaded will be stored in the tenant database "testorg". Users can connect to "testorg" using any third-party connector to view their tables.
Schema

The Amorphic Dataset registration feature helps users to extract and register the schema of uploaded files when they choose a data warehouse (Redshift) as the target location.
Schema Definition
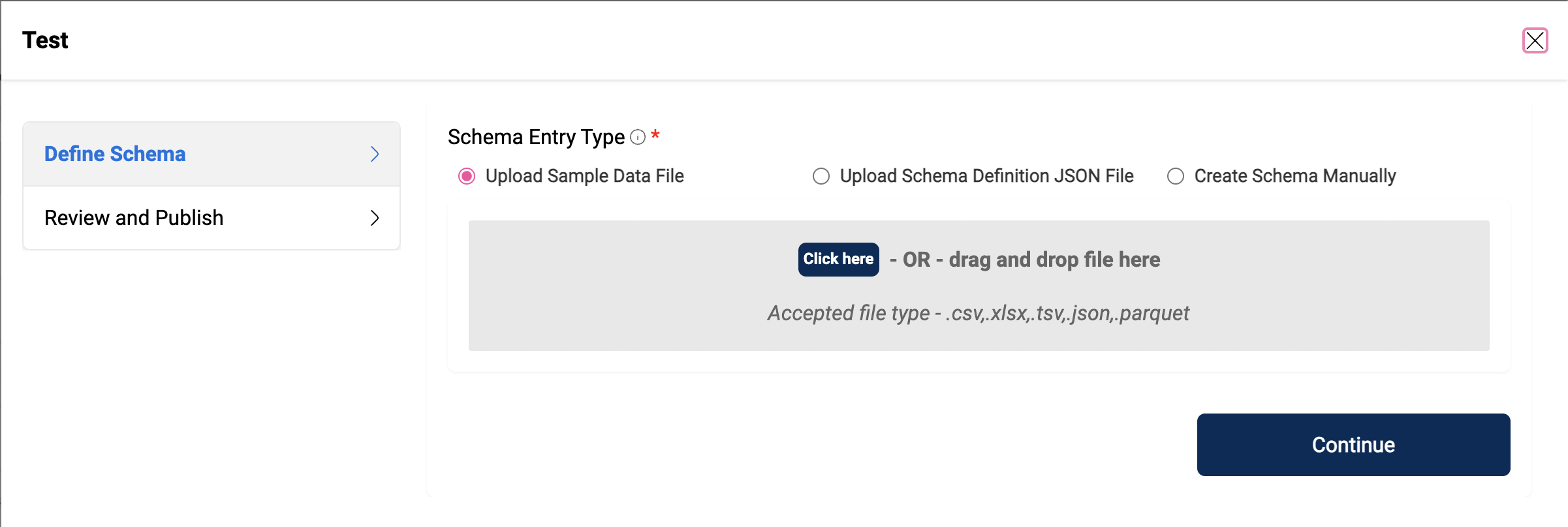
When a user registers a dataset with a data warehouse as the target location, they are directed to the "Define Schema" page. Here, they can upload a schema file, upload a JSON file containing the schema definition, or manually enter the schema fields. The schema file can be of the following types: csv, xlsx, tsv, json, parquet
Schema Publishing

When a user registers a dataset with a data warehouse (Redshift) as the target location and selects "My data files have headers" as "Yes", they are directed to the "Publish Schema" page, where an inferred schema will be displayed.
On the Schema Extraction page, the user has the option to add or remove new fields, or edit the "Column Name" and "Column Type". The user can also change the data type of all columns to varchar by using the 'Set all columns to varchar type' button.
Below are the data types supported for Redshift targeted dataset:
INTEGER, SMALLINT, BIGINT, REAL, DOUBLE PRECISION, DECIMAL (Precision: 38), VARCHAR (Precision: 65535), CHAR (Precision: 4096), DATE, TIMESTAMP, TIMESTAMPTZ, TIME, TIMETZ, BOOLEAN
Column names must be 1-120 (common limit) alphanumeric characters, _ is allowed and must start with an alphabetic character only.
Redshift: A single table can contain up to 1600 columns.
You can also custom partition the data. Please check the documentation on Dataset Custom Partitioning.
Create dataset with schema in a single step(API Only)
Users can create and register the schema of a dataset in a single API call by adding the schema information to the request body. If anything fails for the schema registration, the dataset will still be created but the registration will be in pending state.
Here is an example of creating and registering schema for a dataset using this API
### API Request Payload Details
**/datasets** & **POST** method
Request Body
{
"DatasetName": "TestDatasetName",
"DatasetDescription": "",
"Domain": "TestDomainName",
"ConnectionType": "api",
"IsDataValidationEnabled": true,
"SerDe": "OpenCSVSerde",
"FileDelimiter": ",",
"FileType": "csv",
"IsDataCleanupEnabled": false,
"IsDataProfilingEnabled": false,
"LifeCyclePolicyStatus": "Disabled",
"TargetLocation": "s3athena",
"MalwareDetectionOptions": {
"ScanForMalware": true,
"AllowUnscannableFiles": false
},
"SkipFileHeader": true,
"SkipLZProcess": false,
"TableUpdate": "append",
"DataMetricsCollectionOptions": {
"IsMetricsCollectionEnabled": false
},
"IcebergTableOptions": {
"IsIcebergTable": false,
"TableProperties": []
},
"DatasetSchema": [
{
"name": "FirstName",
"type": "varchar(256)",
"description": ""
},
{
"name": "LastName",
"type": "varchar(256)",
"description": ""
},
{
"name": "Address",
"type": "varchar(256)",
"description": ""
}
],
"PartitionKeys": [
{
"rank": 1,
"name": "partition1",
"type": "varchar(256)"
}
]
}
Along with the schema add other required parameters, for eg: SortType in case of redshift dataset
View Dataset

Upon clicking on View Details under a dataset, the user will be able to see all the following details of the dataset:
- Details
- Profile
- Files
- Resources
Details

The Details tab would contain dataset information such as Dataset Name, Dataset S3 Location, Target Location, Domain, Connection Type, File Type, etc., as well as user-inputted Dataset Details, including Dataset Name, Domain, Connection Type, and File Type.
- Dataset Status: The status of the dataset will be 'active' if it is in a normal state. If the dataset is undergoing a data reload process, the status will be 'reloading'. If the user initiated a truncate dataset, the status will be 'truncating'.
- Dataset S3 Location: The AWS S3 folder location of the dataset.
- Dataset AI/ML Results: Advanced analytics summary of the dataset.
- Created By: The user name of the user who created the dataset, and the creation date-time in YYYY-MM-DD format.
- Last Modified By: The user name of the user who last modified the metadata of the dataset, and the date-time in YYYY-MM-DD format when the metadata was last modified.
Profile

The Profile tab will contain JDBC connection, Host, and ODBC connection information. This is useful for establishing a connection between different data sources and the amorphic platform.
Note: When a user connects to the JDBC connection through a data source or a BI tool, all the tables (only the schema, not the actual data) in the specific database will be displayed along with the user-owned tables (datasets).
You can view the schema of the dataset if it is registered with the target location as a Data Warehouse (Redshift). If data profiling is enabled for the dataset, then data profiling details will also be displayed in the Profile tab. Please check the documentation on Data Profiling for more information.
Files
 You can manually upload files to the dataset only if the connection type is 'File Upload' (default).
In the Files tab, you can upload files to the dataset, delete files, download them, apply ML, and view AI/ML results. For more information, please refer to the Dataset Files documentation.
You can manually upload files to the dataset only if the connection type is 'File Upload' (default).
In the Files tab, you can upload files to the dataset, delete files, download them, apply ML, and view AI/ML results. For more information, please refer to the Dataset Files documentation.
Invocations & Results
When a machine learning model is applied to a dataset, whether structured or unstructured, the output is referred to as an invocation and result. Users can download the logs for each invocation. If no ML model is applied to the file, clicking the "Invocations and Results" button will display a "No invocations" message.
Apply ML

You can apply Machine Learning models to files in the dataset. After selecting the "Apply ML" option, the application will prompt for the "Type" (e.g. ML Model or Entity Recognizer).
If the selected type is ML Model then user needs to provide below details:
- ML Model: Dropdown shows ML model names user has access to.
- Instance Type: Dropdown shows machine types user wants to apply model on.
- Target Dataset: Dropdown shows amorphic datasets user wants to write output to.
View AI/ML Results
The "View AI/ML Results" option in the File Operation shows you the AI/ML results applied to ML models and Entity Recognizers.
View More Details
When files are added to the dataset via an S3 connection, View More Details provides the location of the file on the source, for example, the source object key.
The source metadata of the file can only be seen for data loaded via an S3 connection of version 1.0 or higher (e.g. new or upgraded connections). Due to S3 limitations, this metadata will not be available for files larger than 5 GB.
File Search
The File Search option will be disabled if Search Datasets is disabled by administrators. Please contact the administrators to re-enable it.
For non-analytic file type datasets, you can search for files metadata. The File Search tab contains a Search bar to facilitate this process. The results of the search will display the matched files, along with the following options:
Available Keys for Search:
'DatasetId', 'FileName'
You can type "\*" in the search bar to get a list of all files for a dataset.
Sample Queries:
* - retrieve all files for that dataset
(FileName:*samplefile*) - returns files containing 'samplefile'
(FileName:"samplefile.csv") - returns file details with FileName exactly matching 'samplefile.csv'
- File Preview: User can preview the file. Supported file formats are txt, json, docx, pdf, mp3, wav, fla, m4a, mp4, webm, flv, ogg, mov, html, htm, jpg, jpeg, bmp, gif, ico, svg, png, csv, tsv.
- Complete Analytics: User can view the complete analytics of the files for S3 AI-enabled datasets.
- File Download: User can download the file.
Resources

View all the resource dependencies of the dataset like Jobs, Schedules, Notebooks, Views etc.
- You should detach/delete all the dependent resources in order to delete the dataset.
- For standard views created in redshift, if views are created by "WITH NO SCHEMA BINDING" option, The source dataset will not consider these views as dependent views.
SQL satement for createing view with no schema binding:
Create view DomainName.ViewName as select * from DomainName.DatasetName WITH NO SCHEMA BINDING
Here, the view is not considered a dependent view of the dataset. However, if the dataset is deleted, the view cannot be queried.
Share Dataset Access
 If the user lacks tenant or domain access, selecting
If the user lacks tenant or domain access, selecting Provide Domain Level Access will automatically grant the necessary access in the background, along with the dataset access.
View the list of users/tags authorized to perform operations on the dataset. The owner, the user who created or has owner/editor access to the dataset can provide dataset access to any other user/tags in the system.
Each resource will have a share icon and on clicking would open a panel with the following sections:-
Users
This section shows the list of users authorized to perform operations on the resource. Either the user, owner of the resource or any users who has owner/editor access to the resource can provide resource access to other users in the system.
Tags
This tab shows the list of tags authorized to perform operations on
resource. A tag is a key-value pair that identifies a list of users granted access to a resource. Tags
are created by going to
Management -> Access Tags
A user can have thousands of datasets, but the list is limited to 5000 per user in reverse chronological order to prevent performance issues. To view all datasets, users can use the "Search Dataset" option under the Dataset tab.
Edit Dataset
You can edit datasets in Amorphic. All editable fields relevant to the dataset type can be modified.
For Redshift targeted datasets, Distribution style can be updated by editing the dataset.
Clone Dataset
You can clone a Dataset in Amorphic. The Clone Dataset page auto-populates with the metadata from the existing dataset, so you only need to change the Dataset Name. You can edit any field before clicking Register, and a new dataset will appear in the Datasets page.
Delete Dataset
You can delete a dataset instantly and remove all associated metadata.
When deleting a dataset, the process runs asynchronously in the background. If new data is uploaded during this time, there is a risk of data loss. To avoid this, please ensure no files are visible in the Files tab of the dataset details before initiating a new data load. Parallel delete cannot be triggered while a dataset deletion is in progress; Amorphic will throw an error if attempted.
Force delete for redshift dataset(API only)
If the deletion of a Redshift dataset fails because of dependent views, even if no related resources are displayed in the UI, it could be due to views created from that dataset exclusively within Redshift. To remove this dataset, you can utilize the 'force delete' option.
Users can see the dependent views only present in redshift while deleting a redshift dataset like this:
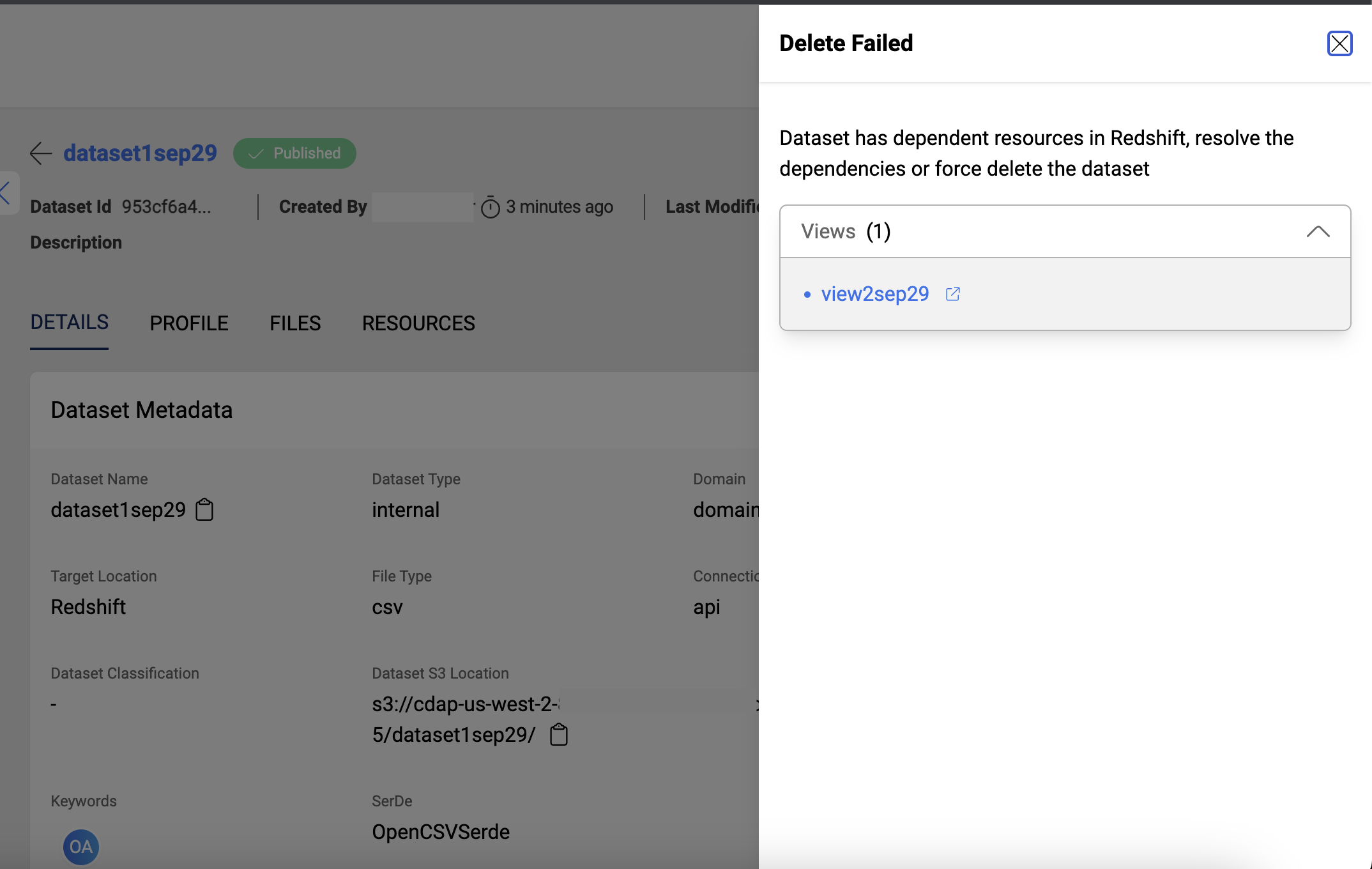
Resource Path: /datasets/{id}
HTTP Method: DELETE
Query String Parameters: force_delete=True // or true
Force delete option only works when there are no other dependencies present from UI( only dependent views in redshift are present)
For bulk deletion of datasets, Please check the documentation on How to bulk delete the datasets in Amorphic
Repair Dataset(s)
Dataset(s) issues can be idenitifed/ repaired in two ways and generated as a report:
- Individually, using the "Repair Dataset/ Generate Dataset Report" button in the top right corner of the dataset details page.
- Globally, using the "Global Dataset Repair/Report" button in the top right corner of the dataset listing page.
For more details, please refer to the How to Repair Dataset(s) in Amorphic documentation.